
해당 포스트는 송교석 님의 유튜브 강의를 정리한 내용입니다. 강의 영상은 여기에서 보실 수 있습니다.
이번 포스트에서는 Convolutional Neural Network를 Visualize 하는 것을 공부해보겠습니다.
CNN이 훌륭한 성능을 보인다는 것은 여러 측면에서 살펴본 바가 있습니다만, 어떻게 그런 성능을 내는 것인지 HOW에 대한 설명이 더 필요합니다.
그래서 이를 시각화하여 들여다보겠습니다.
Visualizations

이번 포스트에서 위와 같은 여러 가지 시각화 주제에 대해서 알아볼 것인데, 우선 CNN이 무엇을 하는지 이해하는 가장 간단한 방법은, CNN의 raw activation 을 보는 것일 겁니다.
Visualize Patches

위 이미지는 하나의 neuron 을 activation 하는 부분이 어떤 부분인가를 시각화 하서 보여주는 것입니다.
예를 들어 pool5 Layer 에서 임의의 neuron 을 취한 다음에 여러 이미지들을 이 Conv. Net 에 돌려줍니다. 그렇게 하면서 이 pool5 Layer 에서 추출한 임의의 neuron 을 가장 excite 시키는 것이 어떤 이미지인지를 살펴본 것입니다.
이미지들의 배열에서 각 행이 neuron 을 의미한다고 보면 됩니다. 첫 번째 행의 경우 사람에게 반응한 것이라고 보면 됩니다.
이처럼 neuron 을 가장 activation 하는 부분이 어떤 부분인지를 시각화하는 방법이 있습니다.
Visualize Weights
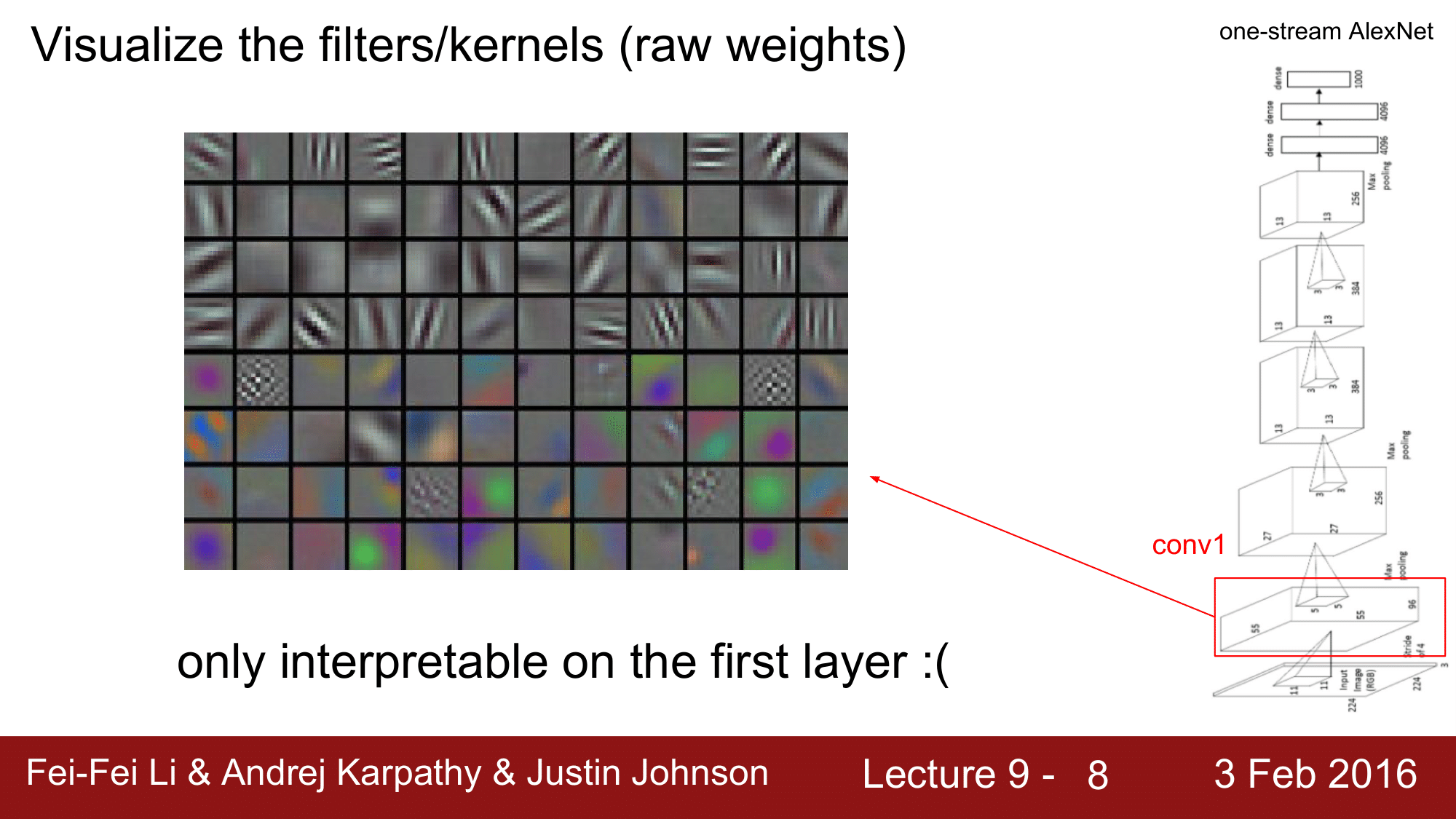
두 번째 방법은 filter 즉, kernel 을 visualize 하는 방법입니다.
이렇게 얻은 이미지는 마치 gabor filter 같이 생겼습니다. gabor filter는 특정 방향성에 대한 외곽선을 검출하는 것으로 texture 분석에 많이 사용됩니다.
예를 들어 conv1 의 filter 들을 시각화하게 되면 gabor filter 처럼 생긴 이미지를 얻게 됩니다.
그런데, 첫 번째 CONV. Layer 에 있는 필터들만 이미지에 직접 작용하게 됩니다.
그렇기 때문에, 첫 번째 레이어의 필터들만 해석이 가능하다는 것이 되겠습니다.

그다음의 레이어들의 weight 들은 위 그림처럼 시각화할 수는 있지만, 이 weight 들을 raw 이미지에 대한 것이 아니라, 전 단계 Layer 의 activation 에 대한 visualize 이기 때문에 해석이 용이하지 않습니다.
그래서 의미가 그렇게 크지 않은 단점이 있습니다. 위 그림에서 괄호 () 안의 것들이 하나의 필터에 대응하는 것이라고 보면 됩니다.
사실 이런 gabor filter 같은 형태의 visualize 를 보면 굉장히 있어 보이긴 합니다만, DeepLearning 의 CNN 에서만 만들 수 있는 게 아니라 전통적으로 알고리즘 기반의 여러 가지 다양한 방식들에 의해서도 나타나는 이미지들입니다.
그래서 gabor filter 과 같은 것들은 피로감이 있을 정도로 예전부터 보여왔습니다.
Visualize Representation Space
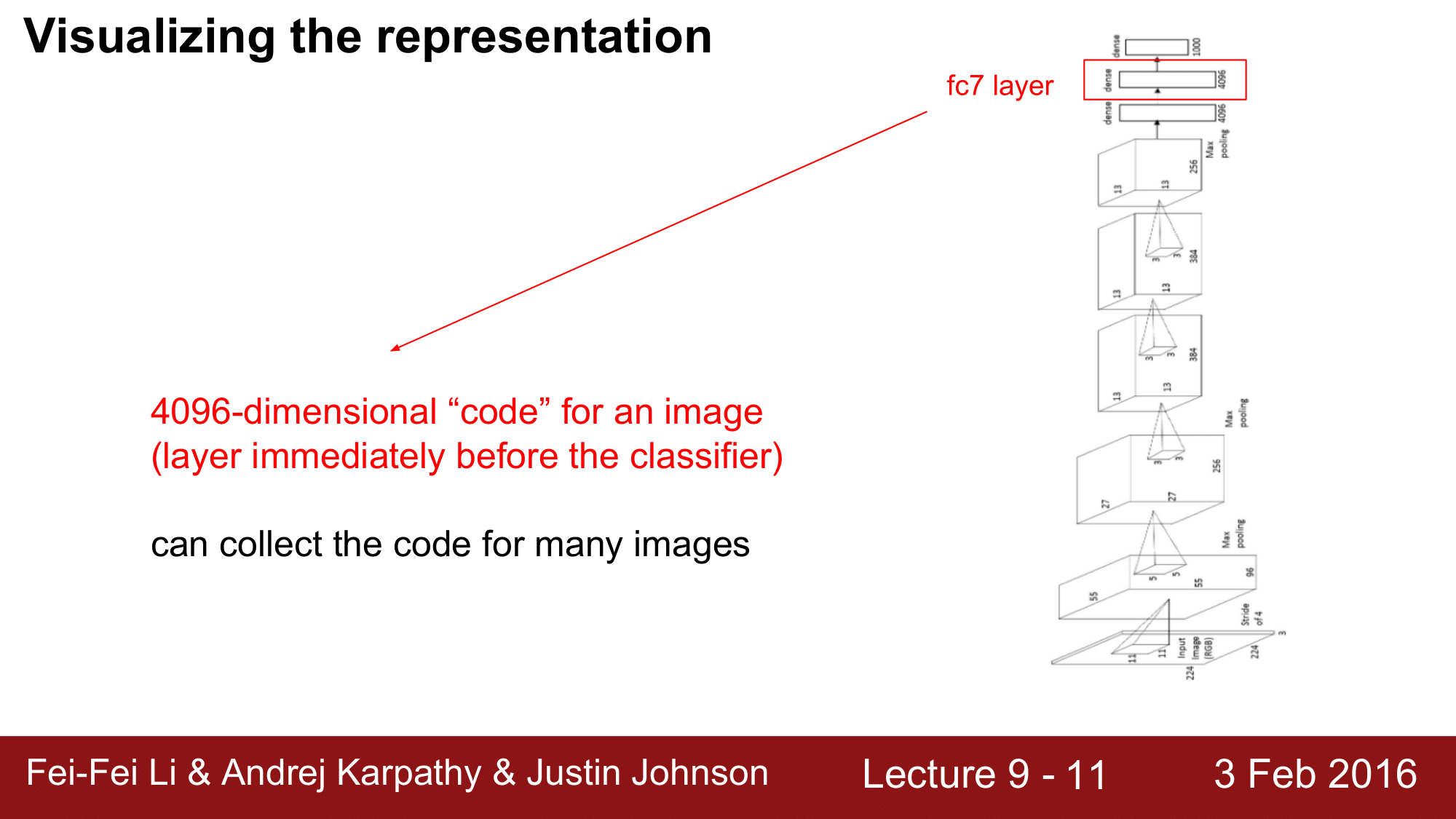
세 번째의 시각화 방법은 Representation 자체를 visualize 하는 것입니다.
classification 을 수행하기 직전의 FC7. Layer 에 이미지에 대한 4096차원의 code 가 들어 있다고 생각할 수 있는데, 여러 개의 이미지에 대한 각각의 code를 모아서 한 번에 visualize 하는 방법입니다.

대표적인 방법으로는, t-SNE visualization 있습니다. 여기에서는 CNN의 시각으로 볼 때, 유사한 것들을 가까운 데로 위치시켜서 clustering 해주는 방법입니다.
오른쪽 그림은, MNIST 데이터를 t-SNE visualization 한 것입니다.

또 다른 예시로, ImageNet 의 1000개의 class 에 대해서 CNN 의 시각으로 볼 때, 가까운 것들을 가깝게 위치시킨 것입니다.
이것을 확대해서 보게 되면, 사람들로 구성되어 있는 부분, 시계로 구성되어 있는 부분들이 모여있는 것을 확인할 수 있습니다.
Occlusion experiments

네 번째 방법으로는 Occlusion experiments 라는 것입니다.
ZFNet 을 만든 분들이 은닉, 은폐를 통해서 실험한 것으로 occluder 라는 회색부분(은페한 부분)들을 0으로 된 정사각형의 행렬로 만들어서 하나의 function 을 만든 겁니다. 즉, 이 function 에서는 occluder 들의 위치에 따라서 얼마나 이미지를 잘 분류하는지, 확률에 어떤 변화가 있는지를 마치 hit map 과 같은 방식으로 해서 보여줍니다.
occluder 를 sliding 하여 진행했을 때, 그 위치에 따른 분류 확률을 살펴본 것입니다.
예상할 수 있듯이, 파란 부분에 occluder 가 위치하게 되었을 때, 분류 능력이 현저하게 떨어지는 것을 확인할 수 있습니다. 그리고 빨간 부분에 위치하게 되면 분류 능력이 상승했다고 합니다. 3번째 그림에서 사람의 얼굴을 가리게 되면 하운드로 분류할 확률이 올라갔다는 의미입니다.
Visualize Activations

이번에는 참고영상을 통해 activation 을 시각화하는 것을 보겠습니다. 지금까지 살펴본 대로 CNN 을 이용해서 이미지를 잘 분류하는 것을 학습해왔는데, 그러나 여전히 이것을 어떻게 잘 분류하느냐 즉, HOW에 대한 부분이 여전히 black-box로 남아있습니다. 그러다 보니 이런 visualization tool 을 만들어서 보다 시각화하여 보여줌으로써 black-box를 풀어 나가는 데에 도움을 주고 싶다는 내용입니다.
참고 영상에서 잠깐 언급이 되었는데, Activation 을 visualization 하는 데에는 두 가지 방법이 있습니다.
- Deconvolution-based approach
- Optimizationi-based approach
위 두 가지 방법이 있는데, 각각에 대해서 살펴보겠습니다.
Deconvolution based Approach

이를 알아보기 앞서서 어떤 이미지가 input 으로 들어올때, 이 input 에 대한 특정 레이어에서의 하나의 뉴런의 gradient 를 계산하려면 어떻게 해야 할까요?
임의의 뉴런이 위치한 레이어까지 forward pass 를 해주고 activation 을 구해준 다음에 해당 레이어에 있는 뉴런들 중 보려고 하는 graident 를 제외하고 나머지를 0으로 주어 필터링해준 다음 back propagation 을 진행해 주면됩니다.
위처럼 진행을 하게 되면 먼저 1. 이미지를 net에 집어넣고,

레이어를 골라서 보고자 하는 gradient 를 제외하고 모두 0으로 설정하고 관심 있는 neuron 만 1로 설정해줍니다.
그리고 backpropagation 을 진행합니다.
이렇게 하면 이미지에 대한 gradient 를 시각화해서 볼 수 있게 되는 것입니다.
위 이미지를 보게 되면 blobby 한 이미지가 나오게 되는데, 그 이유는 positive 한 influence 와 negative 한 influence 가 서로 충돌하다가 서로 canceling out 을 하게 되어 애매한 이미지가 나오게 되는 것입니다.
그래서 이것을 좀 더 선명하게 만들어주는 방법은 그냥 back propagation 을 사용하는 것이 아니라 Guided backpropagation 을 사용하는 것입니다.
Guided backpropagation 을 사용하게 되면 positive 한 influence 만 back propagation 시에 반영합니다. 그렇게 하여 오른쪽 그림과 같은 선명한 이미지를 얻을 수 있습니다.
뒤에 좀 더 살펴보겠지만, Guided backpropagation은 다른 것은 바뀐 게 없고 ReLU 대신에 Modified ReLU 를 이용해서 이런 결과를 얻어 낼 수 있는 것입니다.
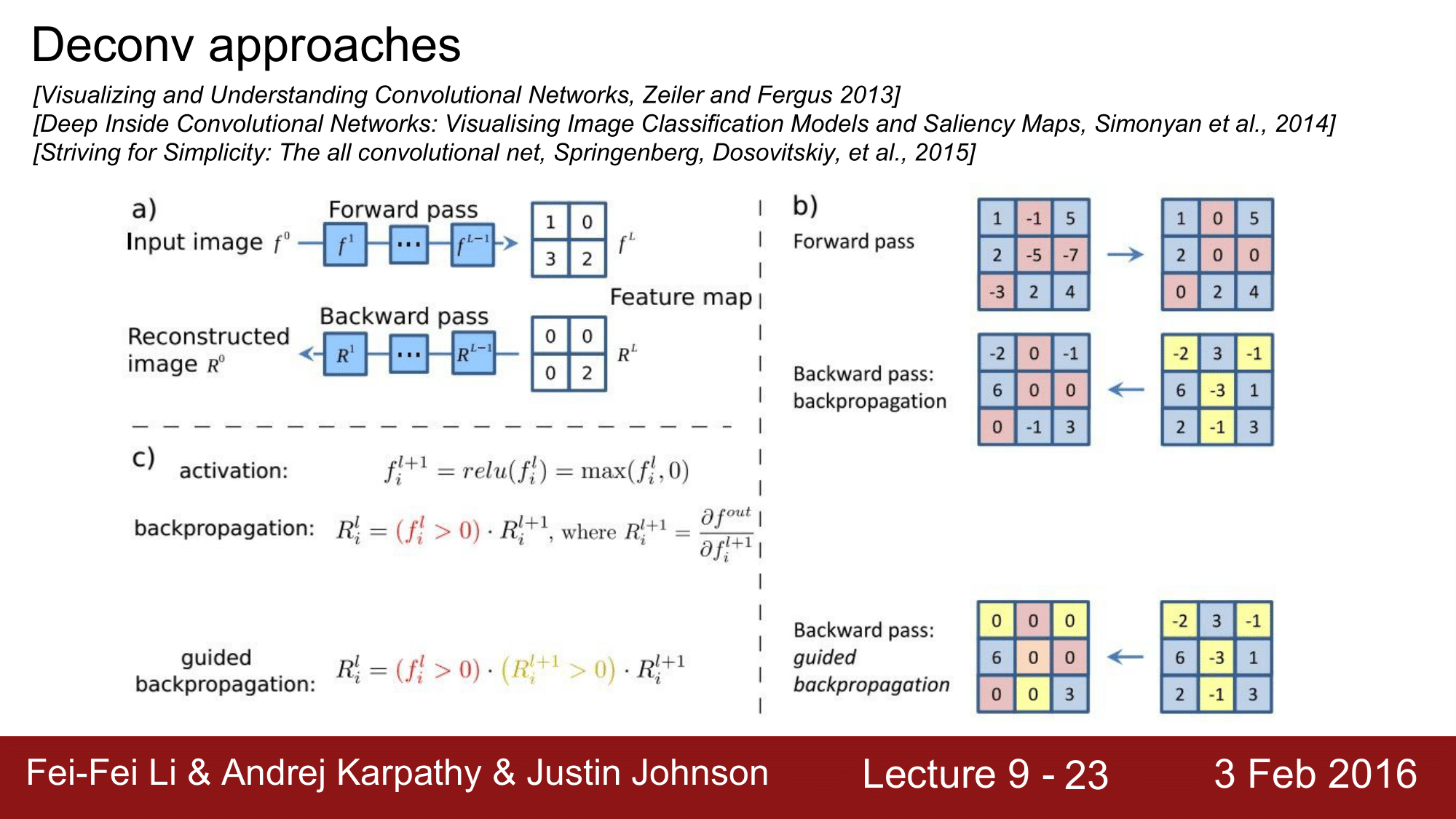
a) 이 과정을 자세히 살펴보게 되면, input 이미지가 들어오고 forward pass 를 거쳐서 $f^L$ 과 같은 feature map 이 나왔다고 하겠습니다. 이때 우리가 관심을 가지고 있는 neuron 이 2 라고 한다면, 이 neuron 의 gradient 만 1로 놔두고 나머지들은 0으로 처리한 것입니다.
b) ReLU 의 경우를 좀 더 살펴보게 되면 input 이 들어왔을 때, forward pass 를 진행하게 되면 0 보다 작은 빨간색 부분들을 모두 0으로 치환합니다. 왜냐하면 ReLU가 max 값을 취하는 형태이기 때문입니다. 그래서 backward pass 에서는 빨간색 부분은 그대로 0이 될 것이고 나머지 노란색 부분에 대해서만 backward pass 가 진행되는 것을 볼 수 있습니다.
결과적으로 4군데 0인 곳을 제외한 나머지는 그대로 전달되는 것을 확인할 수 있는데, Guided backpropagation 에서는 ReLU에 의해 0으로 처리된 부분 외에 마이너스(-)값을 가지는 노란색부분들이 모두 0으로 변합니다. 그래서 결과적으로 6과 3만 남게됩니다.
즉, 이 식에서도 보이다시피 positive 한 influence 만 주는 것들만 통과를 시키는 것입니다.
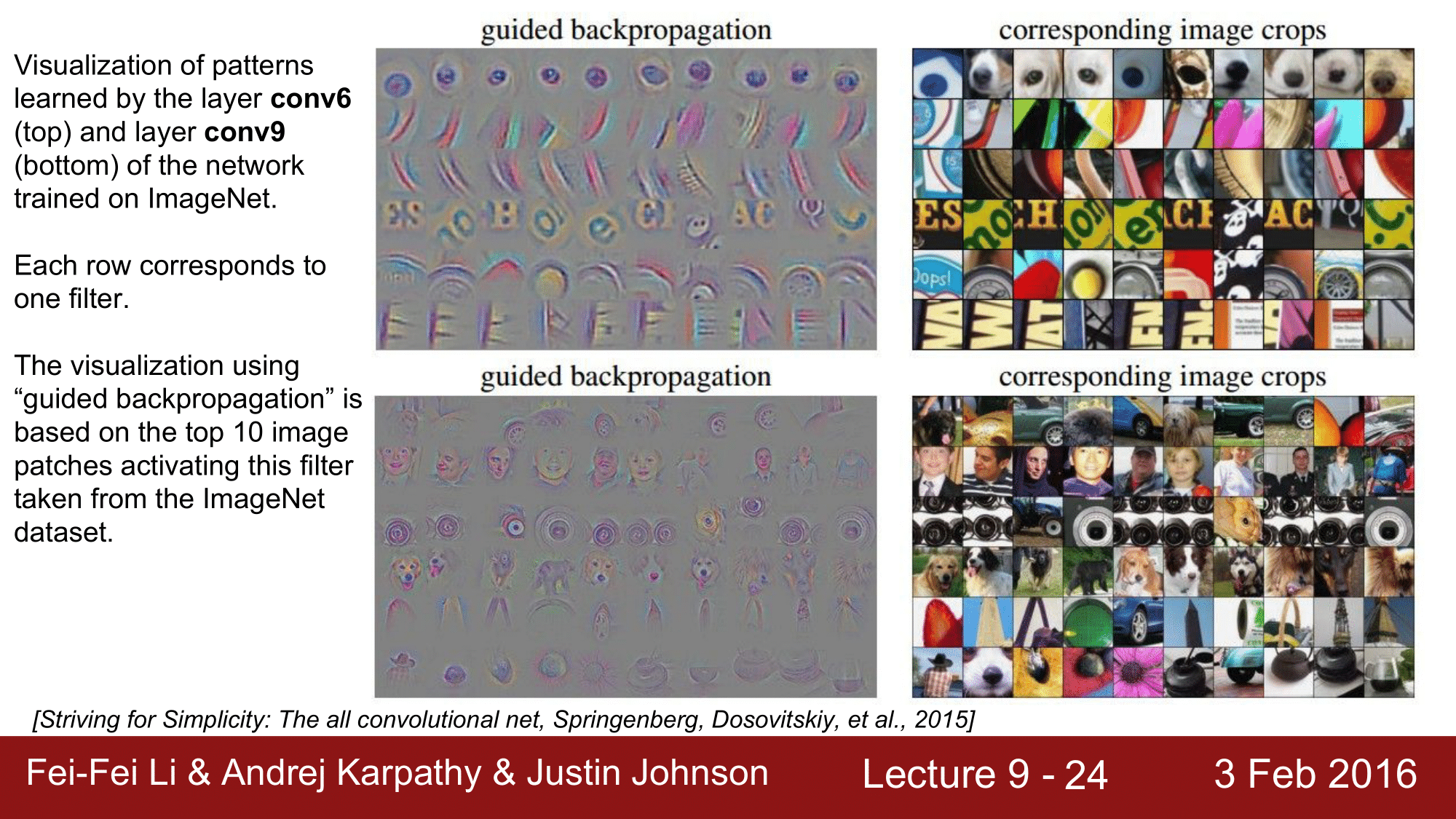
Guided Backpropagation을 한 것들의 예시를 보게 되면, 위에서 차례로 conv6, conv9 레이어인데, 선명하게 나오는 것을 확인할 수 있습니다.
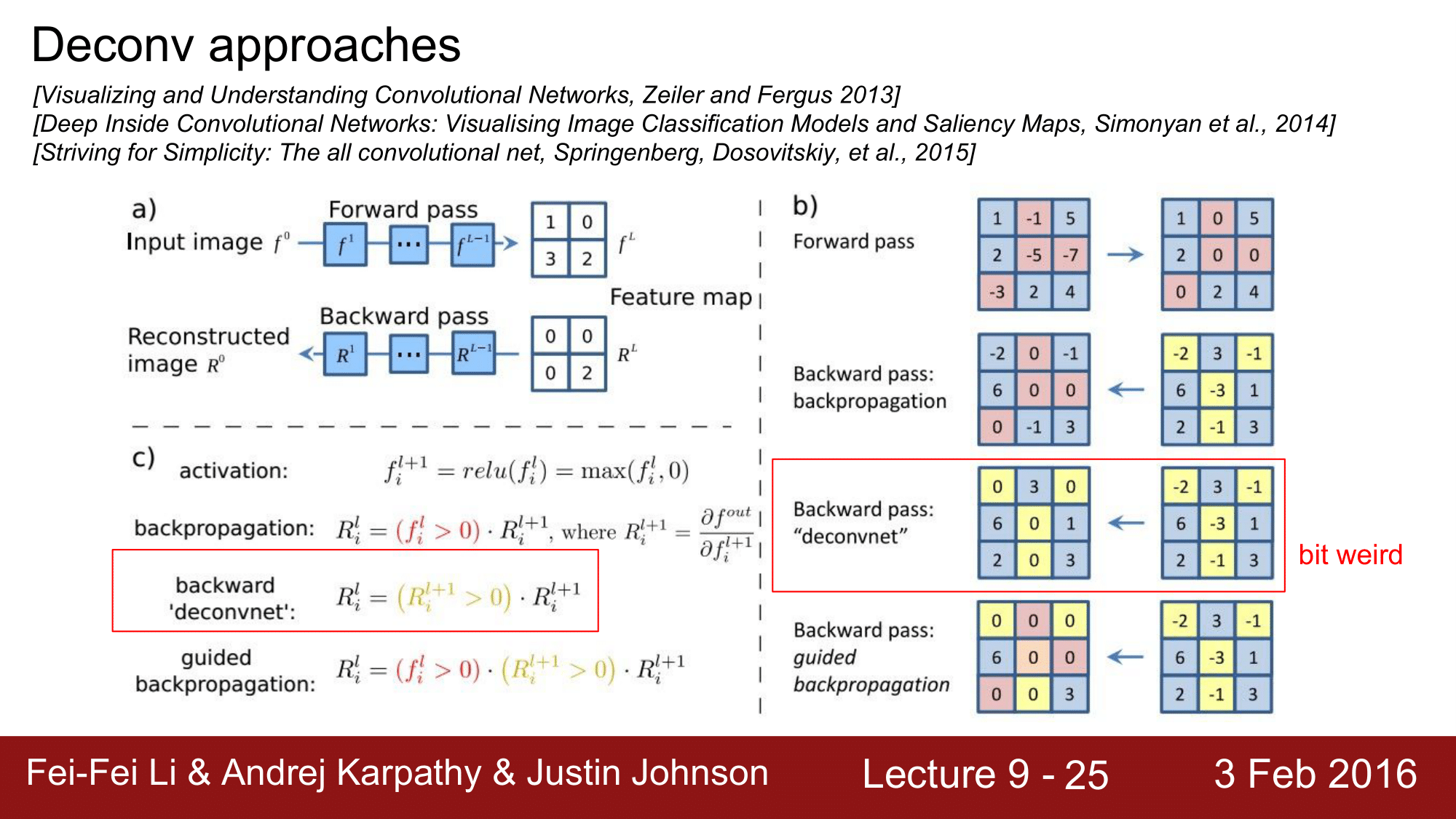
Deconv approcaches 에서 또 하나의 방법은 deconvnet 이라는 것이 있습니다.
deconvnet라는 것도 논문에서 같이 제시됐습니다.
c) 를 보시게 되면, 조금 전의 guided backpropagation에는 activation 즉 ReLU가 식에 들어가 이에 의해서 0으로 되어있는 부분들은 0으로 결과가 나오는 것인데, backward deconvnet에서는 ReLU 의 영향을 받지 않기 때문에, 마이너스 값들이 있을 때 이것을 backpropagation 을 하게 되면, 그냥 마이너스인 값들은 모두 0으로 처리가 되게 됩니다. ReLU 와는 관계없이 0이면 무조건 0이 되는 것입니다. 물론, 양수 값들은 그대로 전달되게 됩니다.
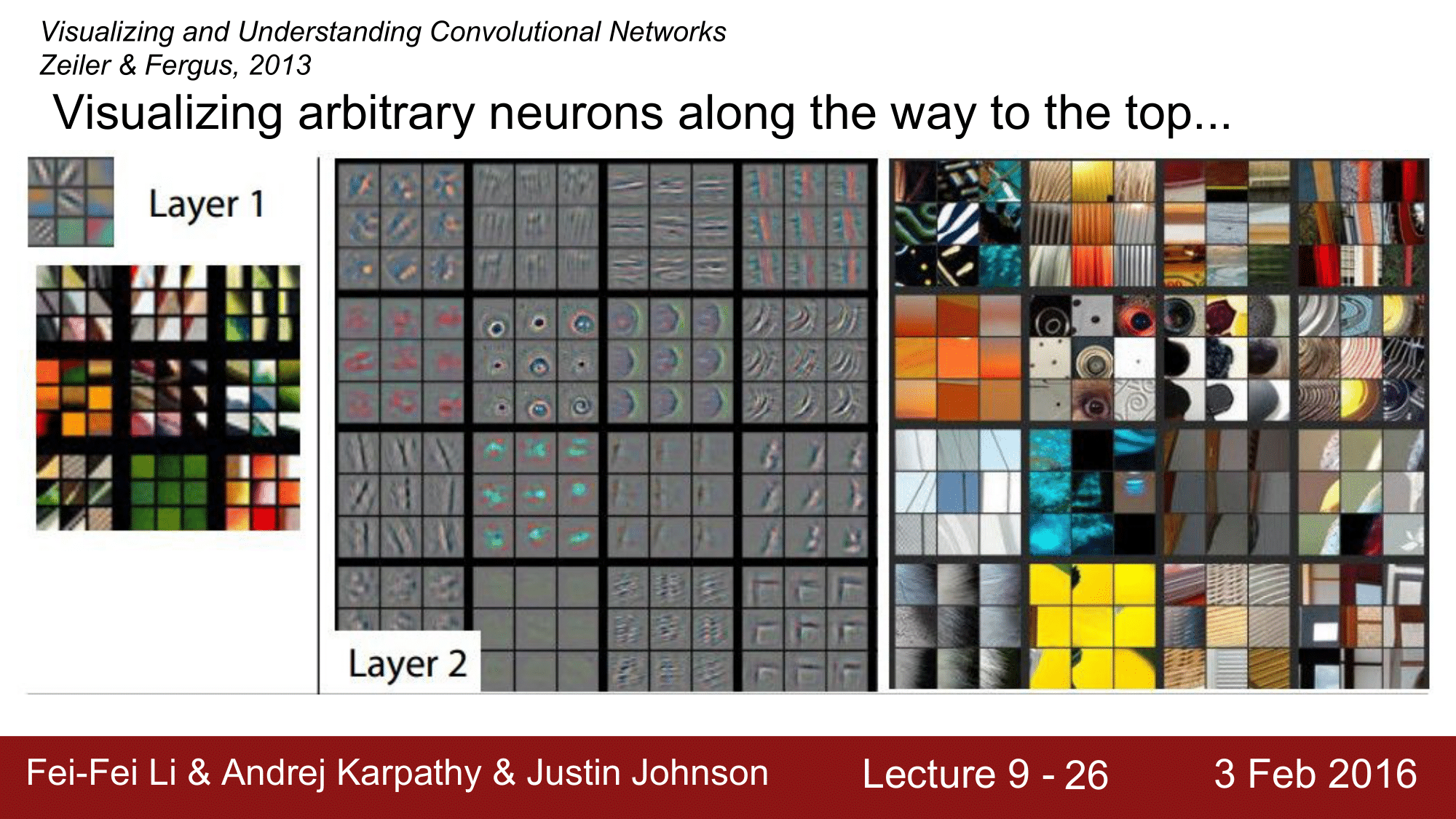
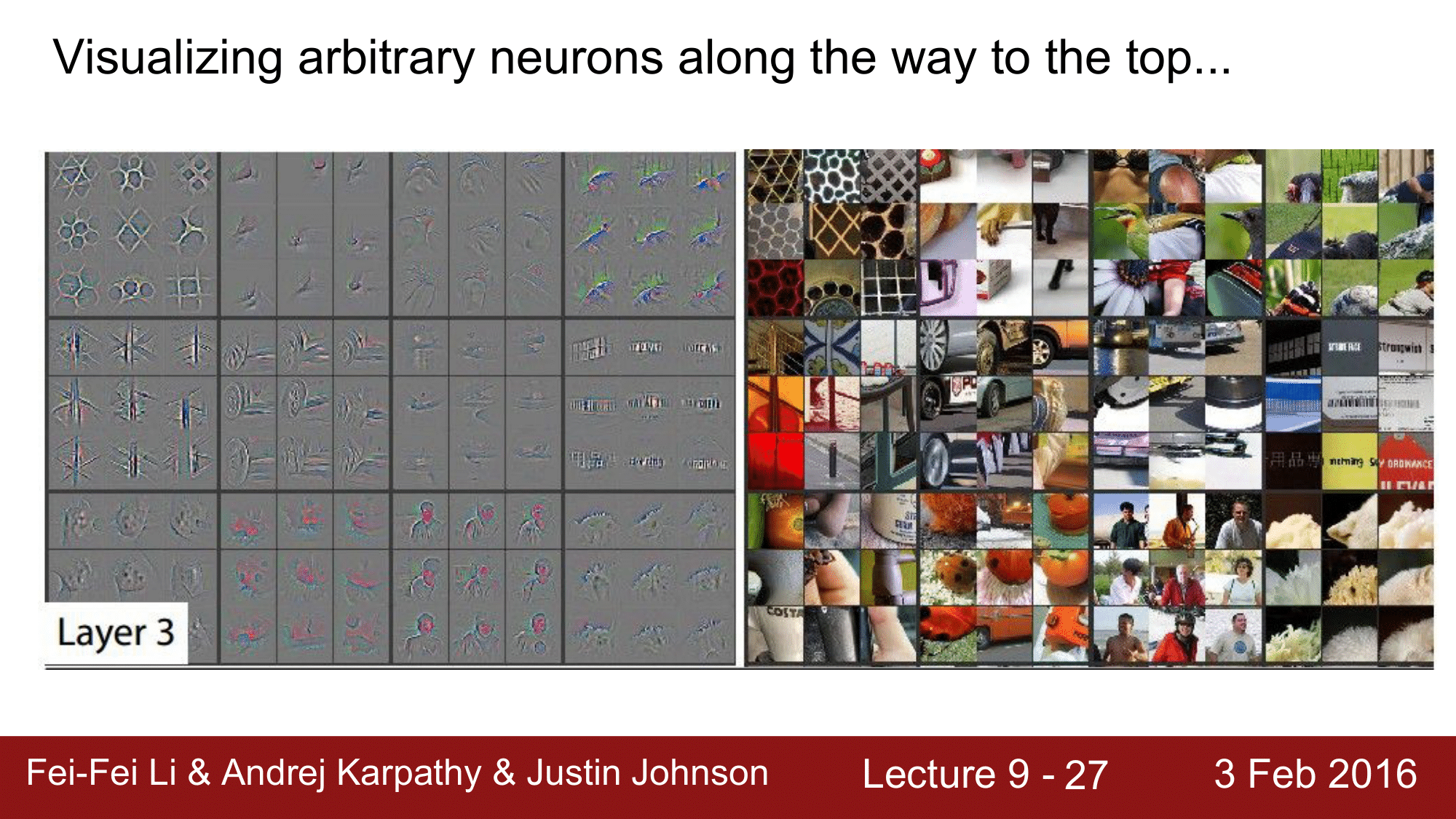

예시 그림을 보게 되면, deconvnet 역시 잘 동작하는 것을 볼 수 있습니다.
Layer 1, 2, … , 5까지 잘 Visualize 되는 것을 확인할 수 있습니다.
지금까지 Deconvolution의 접근 방법들에 대해서 살펴봤습니다.
Deconvolution 은 앞에서 살펴보았다시피 한 번에 forward 되고, 한 번에 backward 되는 것이 장점이라고 볼 수 있지만, 이제부터 살펴보게 될 optimization 기반의 접근 방법은 조금 더 복잡하게 진행됩니다. 하지만 이것보다 직관적으로는 더 이해가 쉽습니다.
Optimization

명칭으로 보게 되면, Optimization to image 입니다. 말 그대로 이미지가 최적화의 대상이 되는 파라미터가 되는 것입니다. 즉, 일반적으로 convolution 을 neural network 에서는 weight 들이 파라미터가 됐었는데, 이와는 다르게 여기에서는 convolution network 의 일반적인 weight 와 같은 파라미터들을 고정시켜주고, 이미지를 파라미터로 이용합니다.
| 정리하자면, 여기에서는 weight의 업데이트가 아니라, 이미지를 업데이트하는 것이라고 생각하면 됩니다. 그래서 특정 Class 의 score 를 최대화할 수 있는 이미지를 찾아보려고 하는데, 그때 이 식 $\text{arg max}S_c(I) - \lambda | I | ^2_2$은 특정 클래스 c 에 대한 score 를 최대화하는 인자를 찾아내면 되는 것입니다. 물론 여기에는 적절한 L2 regularization 과 같은 regularization term 이 들어가면 됩니다. |
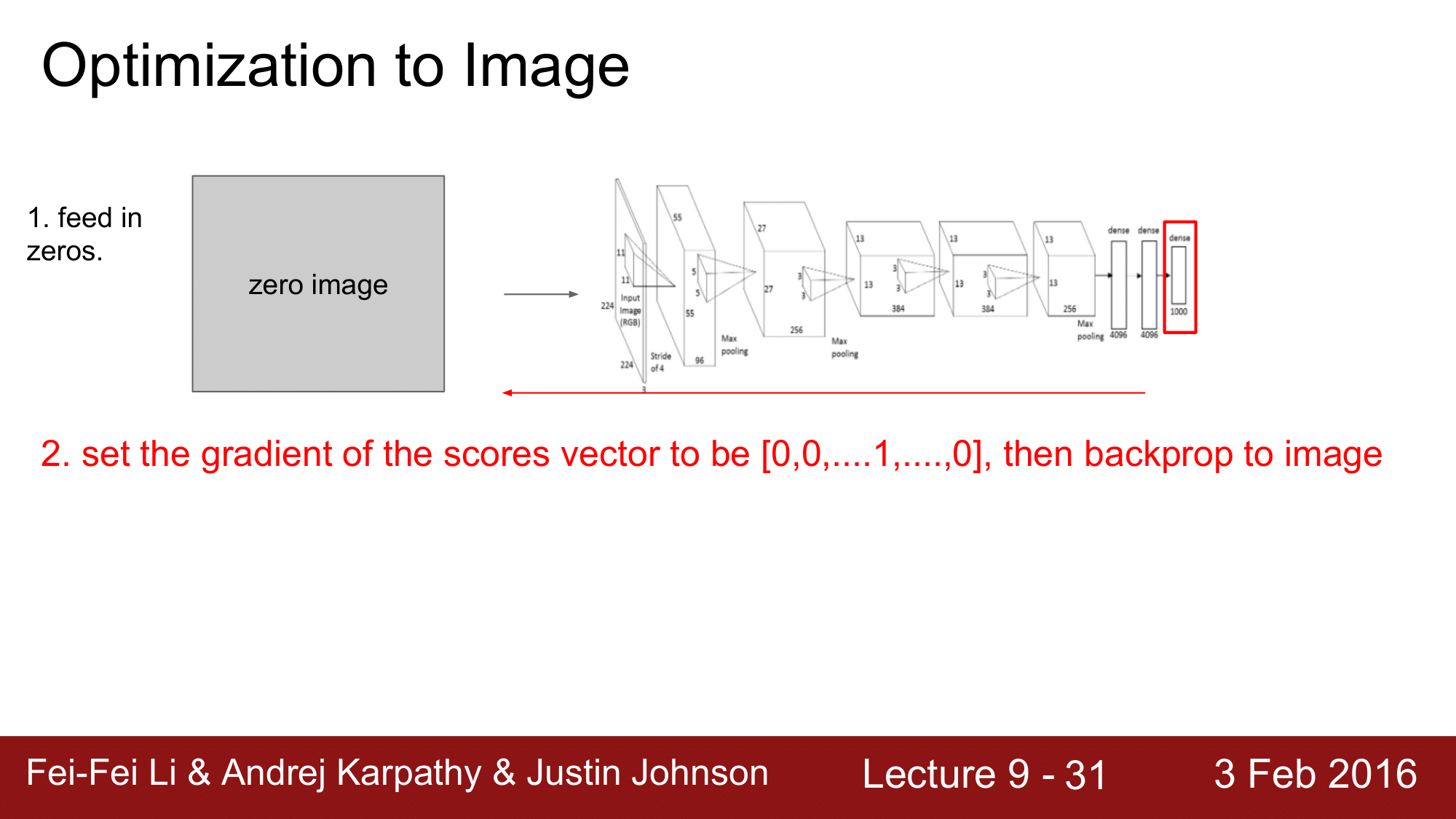
일단 0으로 구성된 zero image 를 network 에 넣어주고 forward pass 를 해줍니다. 여기서 중요한 것은 score vector 에서 우리가 관심을 가지고 있는 Class 에 대해서만 1로 설정해 주고 나머지는 0으로 설정을 해줍니다. 그렇게 하고 backpropagation을 진행하는 것입니다.
이렇게 함으로써 weight 의 업데이트가 아닌 이미지에 대한 업데이트를 약간 수행하게 되는 것이고, 그다음에는 이를 반복하면 되는 것입니다.
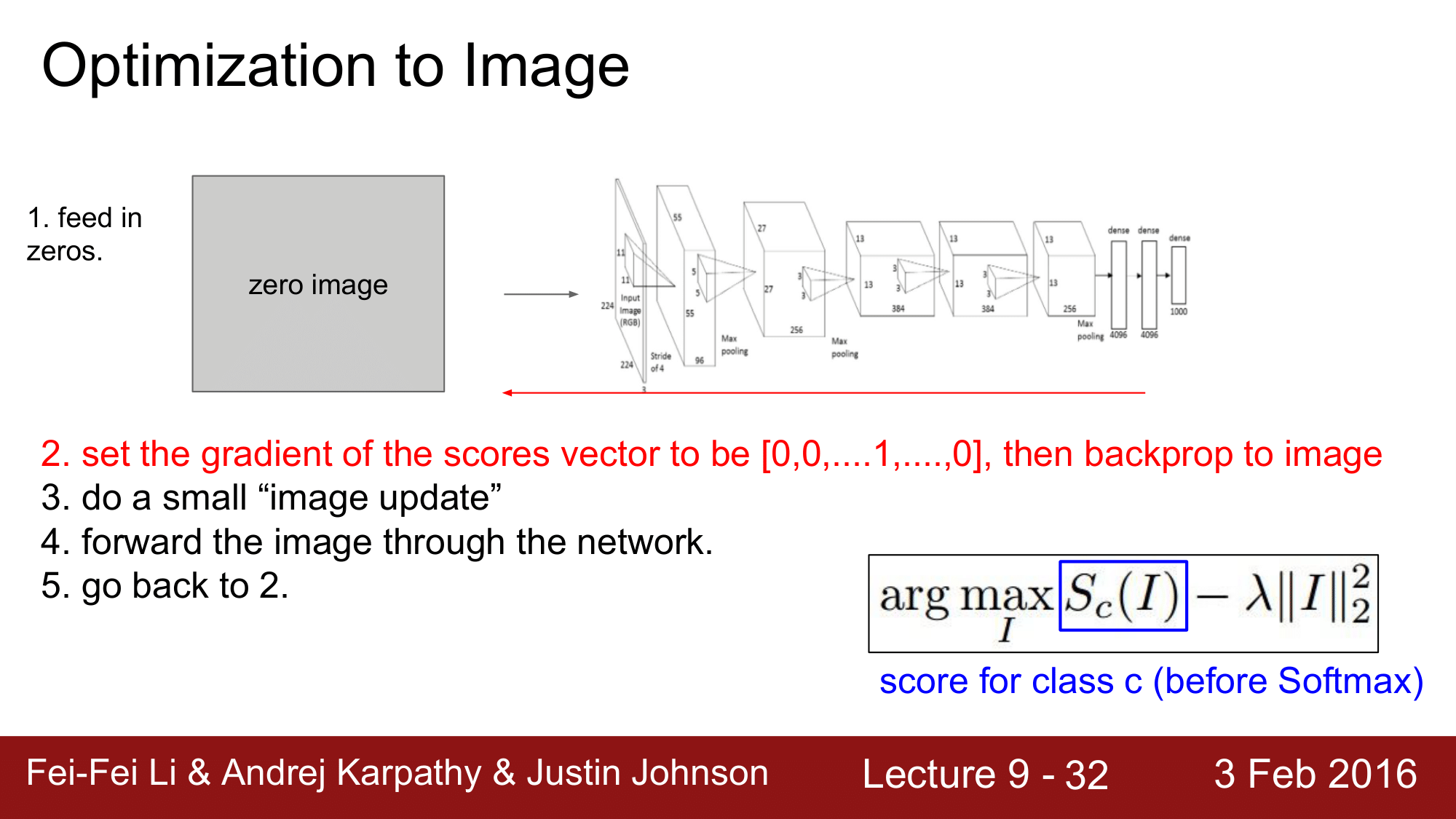
방금 업데이트된 이미지를 network 에 forward pass 하고 특정 Class 만 1로 만들어주고 난 후 다시 backpropagation 을 하는 이러한 일련의 과정을 계속 반복하게 되면 다음과 같은 결과를 얻게 됩니다.

덤벨, 컵, 달마시안 같은 것들이 최초에는 zero image 에서 시작하여 이 클래스가 어떤 것을 보고 activation 이 되는지를 확인할 수 있는 것입니다.

위 거위와 같은 경우는 한 마리만 있는 것이 아니라 여러마리가 곳곳에 위치해서 클래스의 스코어를 최대한 maximize 하려고 노력하고 있다는 것을 눈으로 확인할 수 있는 것입니다.
이렇게 특정 Class 의 score 를 maximize 하는 이미지를 찾아내는 방법을 알아보았습니다.
다음으로, data 의 gradient 를 visualize 하는 방법을 보겠습니다.
Visualize Data Gradient

기본적으로 data 의 gradient 는 3개의 채널을 갖습니다. 이를 염두에 두고 ($i, j, c$) 세 개의 채널에 대해서 squish 해 줌으로써 어떤 결과가 나오는지를 볼 수 있습니다.
그 방법은 다음과 같습니다. 예를 들어 강아지 이미지가 있다고 할 때, 이를 일단 Convolutional Network 에 돌리고 강아지의 gradient 를 1로 설정해 줍니다. 그 상태에서 backpropagation 을 하면 이미지 gradient 에 도달했을 때, 그 순간의 RGB channel 을 squish 해버립니다. 이렇게 되면 1차원의 hit map 같은 것들이 생성되게 되게 됩니다. 그 그림은 다음과 같이 됩니다.

위와 같이 object 가 있는 부분을 1차원의 hit map 같은 형태로 표현한 것을 볼 수 있습니다.
물론, 하얀 부분이 영향을 주는 부분이고 검은 부분이 영향을 주지 못하는 부분이 되겠습니다. 각각의 픽셀들의 영향력의 강도, 세기를 나타내는 것이라고 볼 수 있을 것입니다. 이런 방식을 활용한 grabcut 이라는 segmentation 알고리즘이 있습니다.

이 grabcut을 이용해서 segmentation 을 한 사레도 있다고 합니다. 원본 이미지를 gradient 로 표현해서 grabcut을 이용하여 segmentation 을 하는 것입니다.
지금 살펴본 것은 우리가 원하는 Class 의 score 의 gradient 를 1로 주어 해당 Class 를 시각화했습니다.
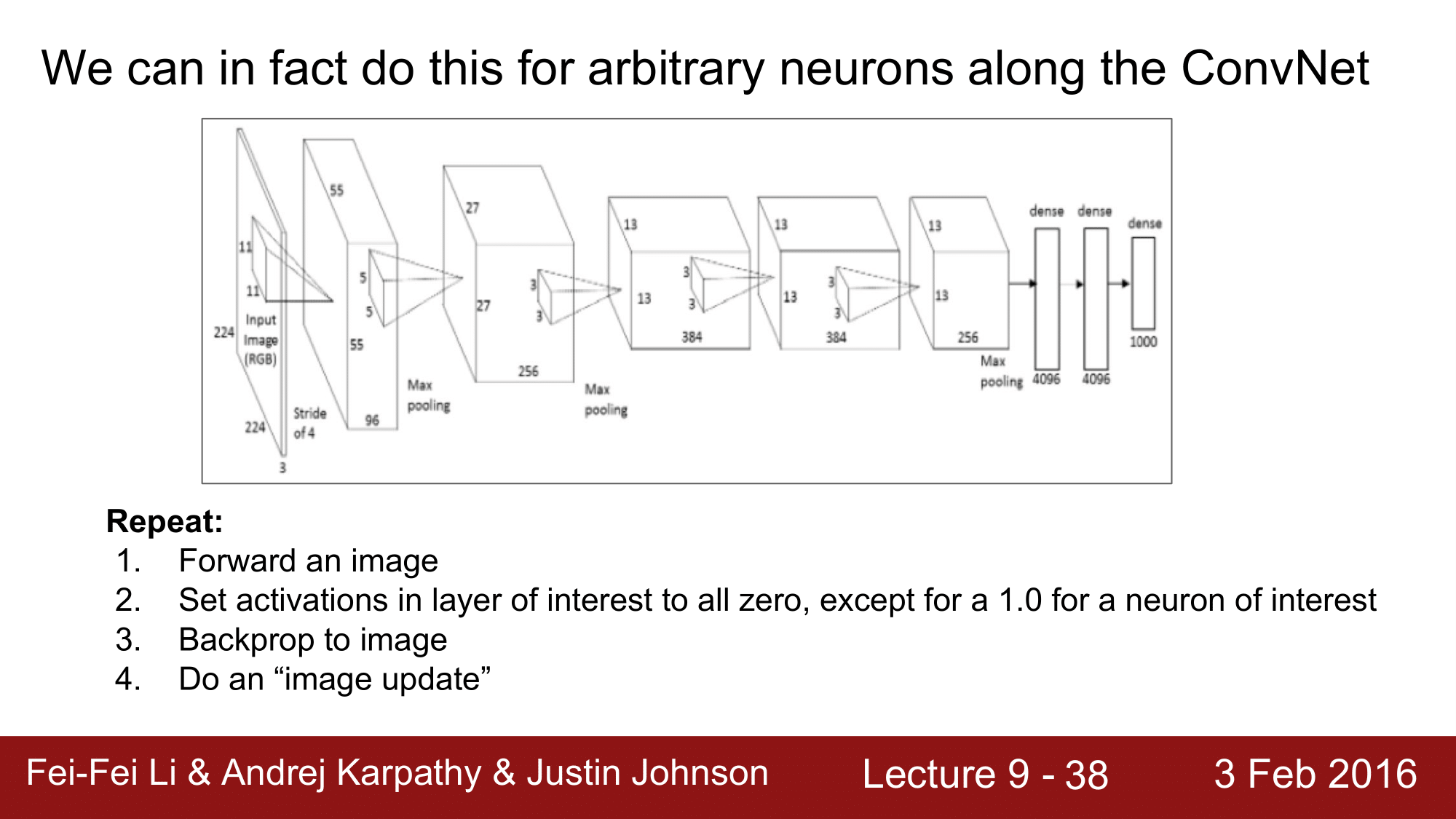
하지만 마지막 레이어에서 score 의 gradient 를 1로 주지 않고, 이를 ConvNet의 과정에서 어떤 layer 든 간에 임의의 뉴런에 대해서 이를 똑같은 방법으로 실행할 수 있습니다.
방법은 동일한데 2번에서, 어떤 특정 레이어에서 우리가 관심을 가지고 있는 그 뉴런의 activation 값을 1로 해주고 나머지 뉴런들의 activation 은 모두 0으로 만들어 주는 것입니다.
이렇게 함으로써 동일한 효과를 얻을 수 있다는 것입니다.

보면 앞에서 봤던 것은 기본적으로 score 애 대해서 빨간색 박스와 같은 regularization term 을 사용했었습니다. 그런데 이 논문에서 제시하는 것은 동일한 방법으로 이미지를 업데이트하는데 위의 regularization term 대신에 이미지 자체를 blur 해준다는 것입니다.
blur 를 함으로써 빈도 높게 발생하는 것을 방지하기 때문에, 이것이 오히려 효과가 더 좋다는 것입니다.
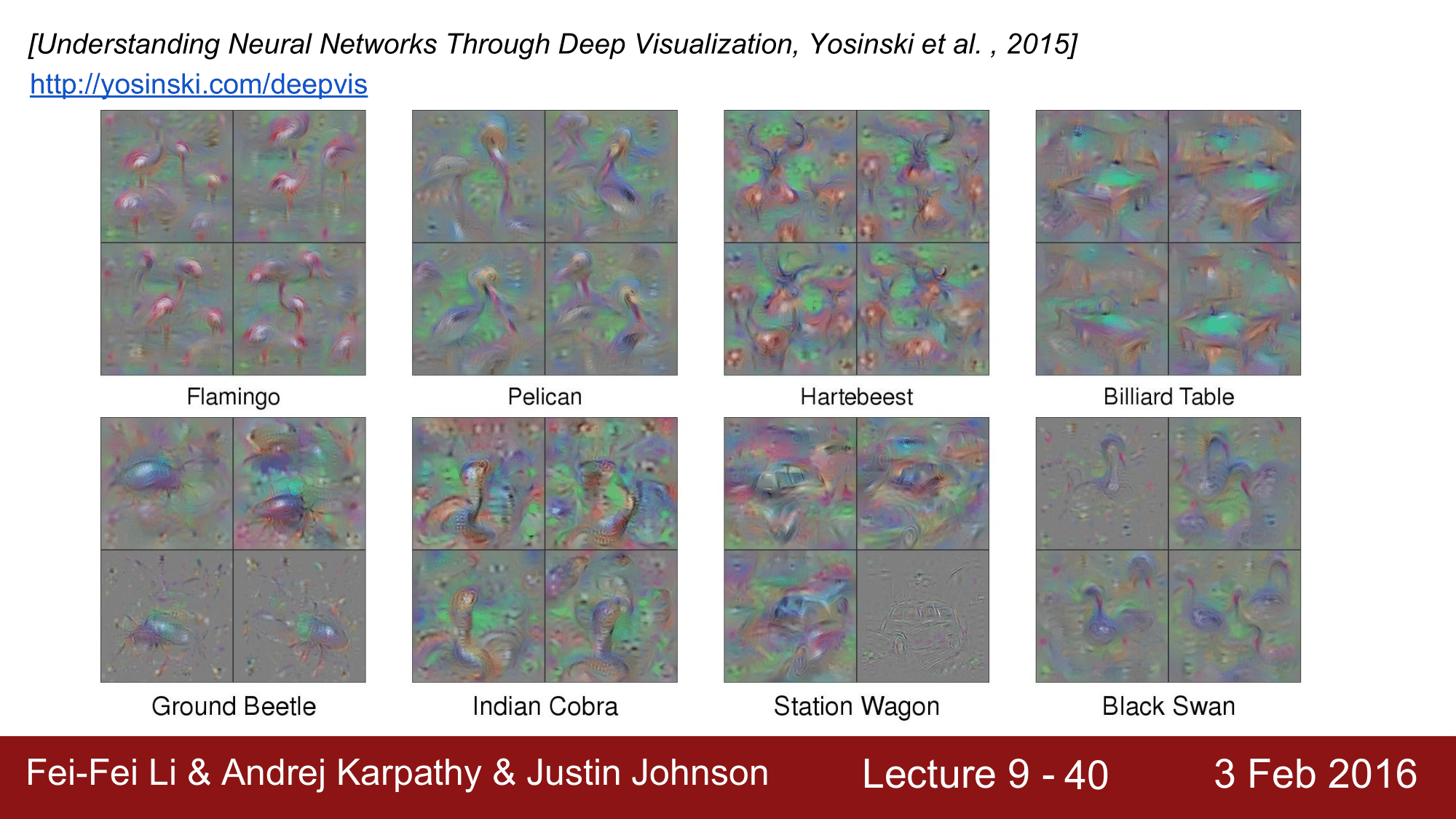
그 결과는 위와 같이 앞에서 본 것들보다는 조금 더 선명하게 나오는 것을 확인할 수 있습니다.
여기에서 차이점은 앞의 과정에서는 L2 regularization 을 사용하였고, 지금 과정에서는 단지 blur 처리를 해줬다는 것 외에는 차이가 없습니다.
마지막 레이어에서는 플라밍고나 펠리컨 같은 것들이 보이는 것이고, 전 단계의 레이어들은 다음과 같이 됩니다.



이렇게 보이게 됩니다. 여기서 생각해야 되는 것은 receptive field 가 Layer 2, 3 같은 곳에서는 굉장히 작아, 좁은 영역을 커버하는 것이고, 뒷단으로 갈 수록 field 가 넓어지면서 이미지 전체를 커버하기 때문에 좀 더 추상적이고 blobby 한 이미지가 나타나게 되는 것입니다.
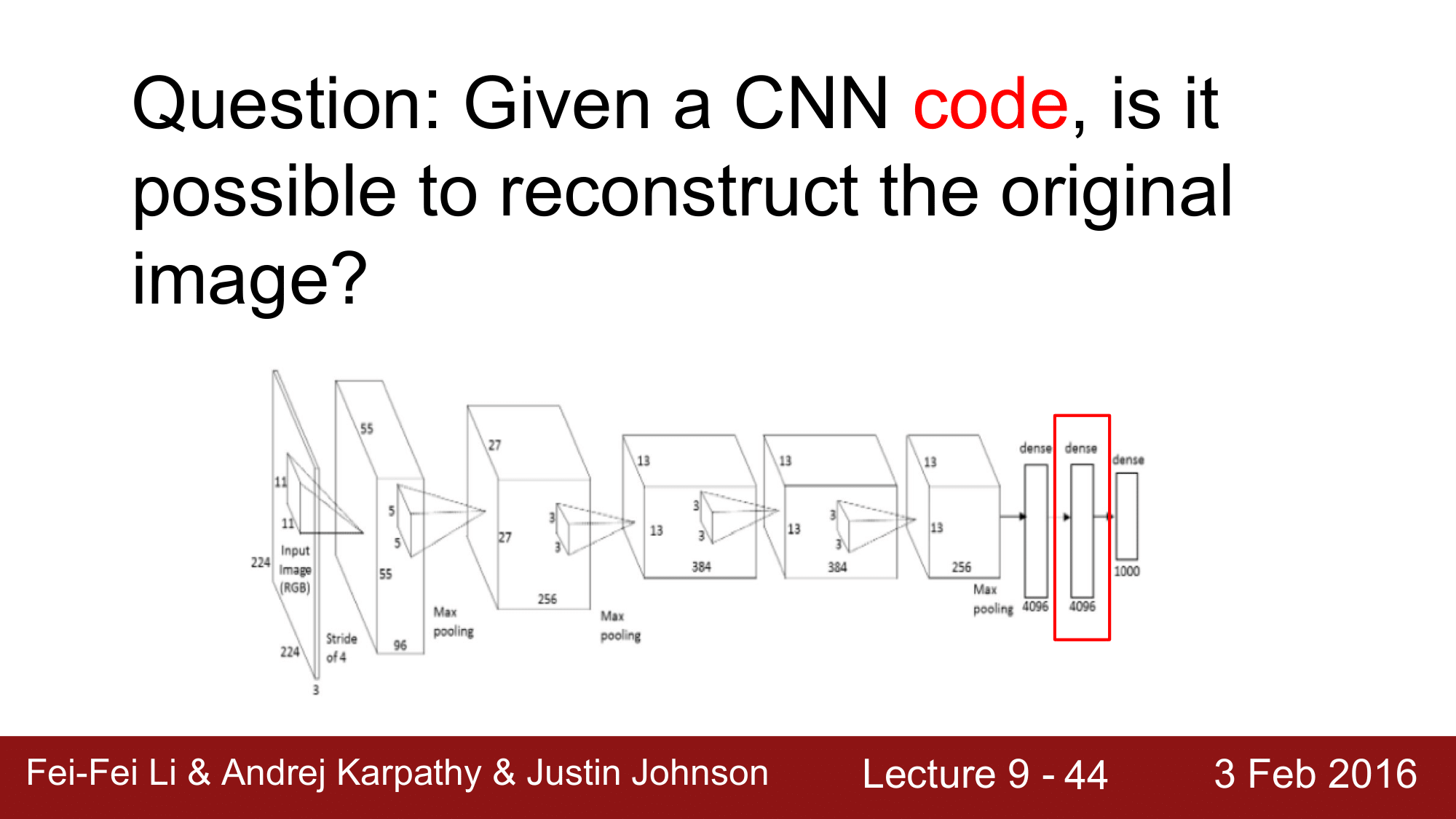
다음으로 넘어가기전에, CNN의 코드가 주어졌을 때, 원본 이미지를 복원할 수 있겠는가라는 물음에 대해 생각해보겠습니다.
예를 들어, 위 그림에서 빨간색 박스 처리되어 있는 FC 7 레이어에서는 4096 차원의 벡터이기 떄문에 4096개의 코드를 가집니다. 이것으로부터 원본 이미지를 복원할 수 있겠는가라는 것입니다.
복원한다는 것으로 reconstruct 나 invert 한다는 표현을 많이 사용합니다.

복원해야 하는 이미지는 주어진 코드와 유사할 것이고, 자연스러워 보여야 합니다.
위 식은 regression 을 진행하면서 차이가 가장 유사한 이미지를 찾는 과정이 되겠습니다.
여기서 임의의 feature 를 maximize 하는 것이 아니라, 특정 feature 를 maximize 하여 이를 찾게 되는 것입니다.
실례를 보면 다음과 같습니다.

앞에서 설명한 것처럼 4096개의 코드로 이를 복원한 것입니다. 그림이 여러 개인 것은 각각 initialization 을 다르게 한 것입니다. 위 그림을 보게 되면, 4096개의 코드가 이미지를 복원하기 위한 어느 정도의 정보를 가지고 있는지 짐작해 볼 수 있습니다.

이러한 작업은 비단, FC 7 레이어에서만 가능한 것이 아니라 Convolution Network 의 그 어떤 것도 모두 가능합니다. 예를 들어 위의 이미지들은 마지막 pooling 레이어의 representation 으로 부터 복원한 것인데, FC 7 레이어보다는 더 앞단에 있기 때문에 spatial location 에 대한 정보가 좀 더 정확하게 나타나 있는 것을 확인할 수 있습니다.

위 그림은 모든 레이어를 단일 이미지가 처리되면서 어떻게 보이는지를 나타내는데, 뒤단으로 갈수록 blobby 해지고, 앞단으로 갈수록 좀 더 선명해지는 것을 확인할 수 있습니다.
그리고 forward pass 를 진행하면서 원본 이미지에 대한 정보를 어떻게 잃어가고 있는지를 대강 파악할 수 있을 것입니다.

이 또한 앞에서 본 것과 비슷합니다.

위 그림들은 구글에서 발표한 Deep Dream 의 결과들인데, 기본적으로 Deep Dream 도 지금까지 본 이미지에 대한 optimization 기법을 그대로 활용합니다.

코드도 100줄 정도 밖에 안되는 정도로 구현이 되는데, 여기서 코드 일부분만 한번 보겠습니다.
이미지를 업데이트할 때마다 위의 make_step 이라는 함수를 호출하게 됩니다. 파라미터 중 end 라는 것에 실제로 어떤 레이어에서 위의 Deep Dreaming 을 할 것인가를 지정하게 되어있습니다.
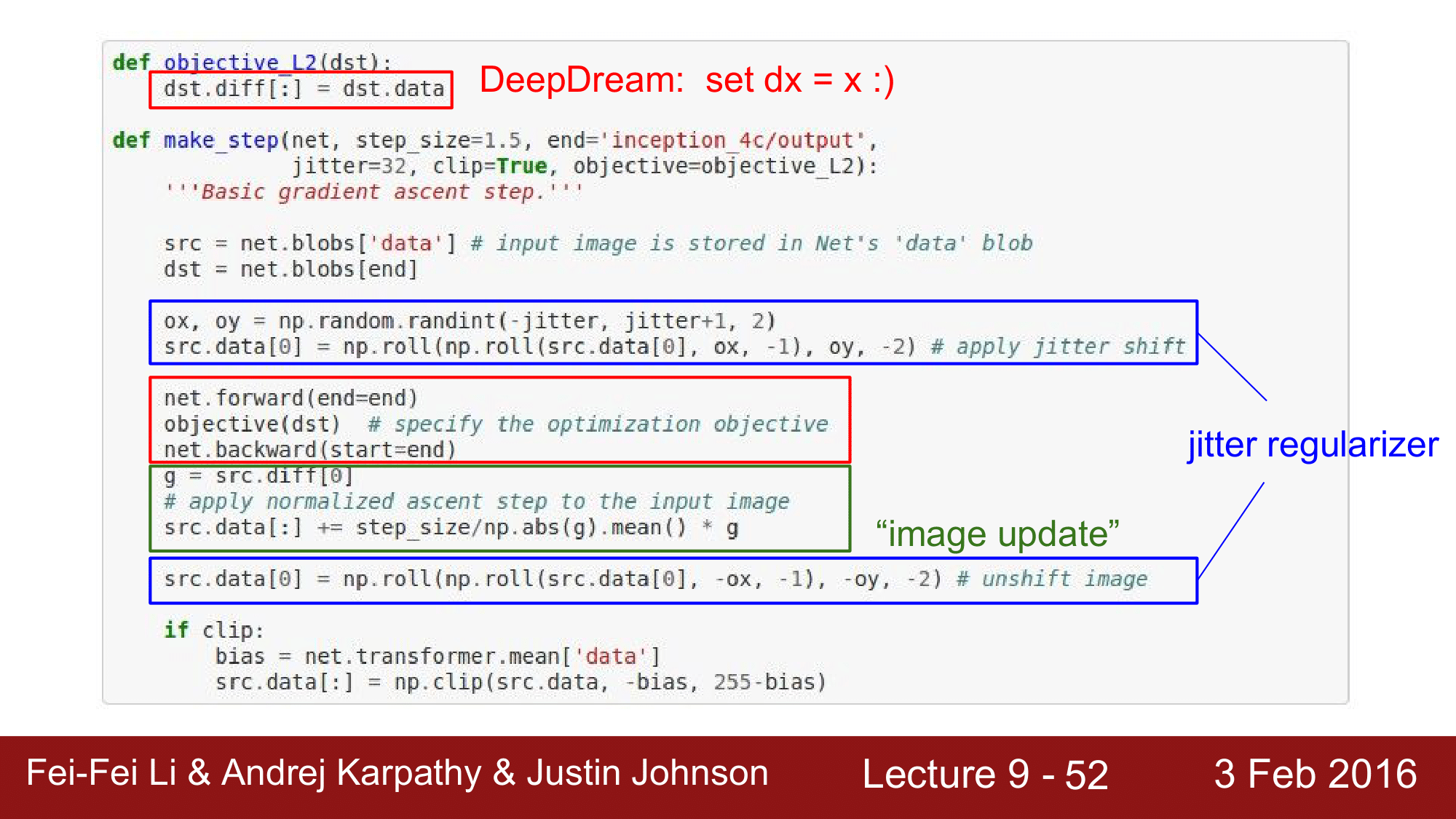
주요 부분을 보면, regularizer 를 jitter 하는 것도 있지만, 핵심은 그 사이의 빨간 박스 부분입니다.
net.forward 를 해서 딥드립을 하길 원하는 레이어까지 forward pass 를 해주고 dst 를 인자로 하여 objective 함수를 호출하는데, dst는 위의 코드 dst = net.blobs[end] 를 보면 blobs 이라는 것을 알 수 있습니다. caffe 에서 이 blob을 사용하는데 이는 두 가지 종류가 있습니다.
blob
- diff field : gradient 정보
- data field : raw activation 정보
위 두 가지 정보를 가지고 있는 dst를 인자로 넘겨주어, objective 라는 함수에서 gradient 를 activation 으로 설정해 줍니다. 즉, dx = x 로 설정한다는 것이 핵심이 되겠습니다.
이후, net.backward로 backward pass를 해주고 normalization 과 image update, clipping 을 진행합니다.
앞에서 핵심은 gradient 값을 activation 으로 그대로 설정해 준다는 것이라고 했는데, 이게 어떤 의미인지를 생각해 볼 필요가 있습니다. 여기서 activation 으로 ReLU를 사용하고 있습니다. 이 ReLU의 특성은 activation이 zero cropped 된다는 것입니다. 음수의 경우 무조건 0이 되고, 양수의 경우 그대로 값을 유지하기 때문에 무조건 0 이상인 activation 을 가지는 상태에서 gradient 를 activation 으로 설정했습니다. 그런데 앞에서 이미지에 대한 optimization 을 할 때, 특정 class 의 score 나 특정 conv layer 에서의 activation 즉, 관심 있는 뉴런의 값을 1로 주고 나머지 뉴런, gradient 들은 모두 0으로 설정했었습니다. 그런데 여기는 0으로 설정하는 것이 아니라 gradient 를 activation 값으로 설정하기 때문에, 모든 activation 에 있어서 boosting 이 일어나게 됩니다.

예를 들어, 구름이 흘러가면서 동물의 형상을 띄기도 합니다.
dog detector 가 있다고 할 때, 해당 detector 가 위 그림을 보고 어떤 부분이 “개” 같이 생겼다고 판단하면, 해당 특징을 갖는 class 가 boost 되는 효과가 일어나는 것입니다.
그래서 오른쪽 그림과 같이 여러 가지 이미지들이 그림과 함께 boost 되어 나타나는 것을 볼 수 있는데, “개” 가 많이 나오게 됩니다. 그 이유는 ImageNet 의 1000개의 Class 중 200개 정도가 개와 관련된 Class 이기 때문입니다.

그래서 이처럼 다양하고 이상한 이미지를 생성하는 것이 Google 의 Deep Dream 이 되겠습니다.

위의 레이어는 3b 레이어로 앞에서 봤던 4c 레이어 보다는 앞단에 있는 레이어이기 때문에 구체적인 형상이 아니라 패턴 위주로 boosting 이 일어난 것을 볼 수 있습니다.
다시 한번 핵심을 짚고 넘어가면, Google 의 Deep Dream 은 gradient 를 activation 값으로 설정하는 것이 핵심이고, 해당 activation 이 ReLU 이기 때문에, boosting 효과가 일어나서 여러 가지 그림들이 합성하는 것과 같은 효과가 나타난다는 것입니다.
아래 링크는 Deep Dream 과 관련된 영상입니다.
Deep Dreaming Fear & Loathing in Las Vegas: the Great San Francisco Acid Wave
NeuralStyle

다음으로 NeuralStyle 에 대해서 알아보겠습니다.
이 NeuralStyle도 앞서 살펴본 DeepDream과 같이 이미지를 Optimization 하는 과정에서 만들어낼 수 있는 모델입니다.
위에 보이다시피 간달프의 사진과 피카소의 사진이 있습니다. 그래서 파카소 사진의 스타일과 간달프 사진의 컨텐츠가 합성이 되어 새로운 이미지가 나오는 것을 확인할 수 있습니다.
기본적으로 NeuralStyle 의 input 은 style 이미지와 content 이미지로 구성됩니다.

위처럼 다양한 예시들을 보실 수 있습니다.

NeuralStype 이 어떻게 동작하는 지 한번 살펴보겠습니다.
우선 Content 이미지를 ConvNet 에 집어넣고, 각각의 레이어에서 raw activation 들을 저장해 줍니다. 예를 들어, CONV5 레이어에서는 [14 x 14 x 512]의 array 를 저장합니다.

다음으로, Style 이미지를 CONV. NET 에 돌립니다.
앞에서 Content 이미지에 대해서 raw activation 들을 저장하고 이것들을 추적했지만, 이번 단계에서 style 과 관련된 통계는 raw activation 에 있지 않고 pair-wise statistics 에 있습니다. 그렇기 때문에 pair-wise statistics 에 있는 style gram matrices를 사용하게 됩니다.
예를 들어, CONV1 레이어에 [224 x 224 x 64]의 activation 이 있다고 할 때, 이 [224 x 224] 를 묶어서 하나의 fiber 라고 합니다. 이렇게 되면 64차원의 activation fiber 라고 생각할 수 있습니다. 그러고 나서, 모든 spatial location 에 대해서 outer product 를 해주고, 이를 모두 sum up 해주게 되면 [64 x 64]의 Gram matrix를 생성하게 됩니다. 이것은 마치 $G = V^TV$라고 생각할 수 있습니다. activation 을 traspose 해준 것과 activation 과 곱을 해주게 되면, [64 x 224 x 224][224 x 224 x 64]이기 때문에 [64 x 64] 의 Gram matrix를 얻는다라고 생각할 수 있겠습니다.
Gram matrix는 기본적으로 공분산행렬(covariance matrix)의 특성을 띄고 있고, 그래서 두 개의 쌍 feature 모두가 activation 되는 경우를 관찰하게 됩니다.
여기에서 무조건 Gram matrix를 사용해야 되는 것은 아니고, spatial varience 한 특성만 가지면 다른 것들도 적용함으로써 동일한 효과를 얻어낼 수 있습니다.

그 다음으로 이미지를 Optimize 를 해주게 되는데, activation 이 되는 content 이미지의 content, gram matrix 가 되는 style 이미지의 style 이 중간의 식처럼 content Loss 와 style Loss 로 존재하게 됩니다.
밑의 그림에서 적절한 초기값을 갖는 랜덤이미지를 CONV 에 넣어줬을 때, activation 부분(Content)과 gram matrix 부분(Style)의 Loss 를 최소화해 나가는 과정에서 둘의 배타적상호작용에 의해 NeuralStyle을 완성해 나가게 됩니다.
여기서 한가지 참고할 내용은, 이전 Optimization 관련 포스트에서 SGD, Adam 과 같은 fist order optimization 과 L-BFGS 와 같은 second order optimization 이 있다고 했는데, 바로 이
NeuralStyle이 L-BFGS 로 최적화 될 수 있는 좋은 예가 될 수 있습니다. 왜냐하면,NeuralStyle이 Huge 한 데이터셋을 가지는 것도 아니고, 아주 간단한 데이터셋을 이용하기에 모든 데이터를 메모리에 올릴 수 있어 큰 연산이 필요하지 않기 때문에L-BFGS로 최적화 할 수 있는 좋은 예시입니다.

지금까지 살펴본 대로, input 이미지에 대한 최적화를 함으로써 어떤 클래스의 score 라도 optimize 하는 것이 가능하다는 것을 알아보았고, 이는 매우 유용합니다.
그런데 여기서 한가지 짚고 넘어갈게 있습니다.
이것을 이용해서 ConvNet 을 속일 수 있겠는가에 대한 내용으로 답은 “속일 수 있다” 입니다.
이런 것을 Adversarial examples 라고 하는데, Kaggle Competition 에도 올라왔던 주제 입니다.

예시를 보게 되면, 위에 버스 이미지가 있습니다. 이 버스 이미지를 input 이미지로 CONV. NET 에 집어 넣는데, 타조 클래스의 Gradient 만 1로 설정하고 나머지들은 모두 0으로 한 것입니다. 스쿨버스도 마찬가지로 gradient 를 0으로 설정한 것입니다. 그 상태로 backpropagation 을 하게되면, 실제로는 좌우의 버스가 거의 동일하게 보이지만 오른쪽 버스를 타조로 분류하게 된다는 것입니다.
이처럼 약간의 변화만으로 위의 타조 예시 뿐만 아니라, 어떤 클래스로 든지 속일 수 있는 것입니다.

앞에서의 같은 랜덤 이미지 뿐만 아니라, 위의 그림과 같이 랜덤한 노이즈에도 똑같이 적용할 수 있습니다.
위 노이즈는 우리 눈에는 그냥 노이즈로 보이지만, 실제로는 치타, 버블 등으로 인식하는 것을 볼 수 있습니다.
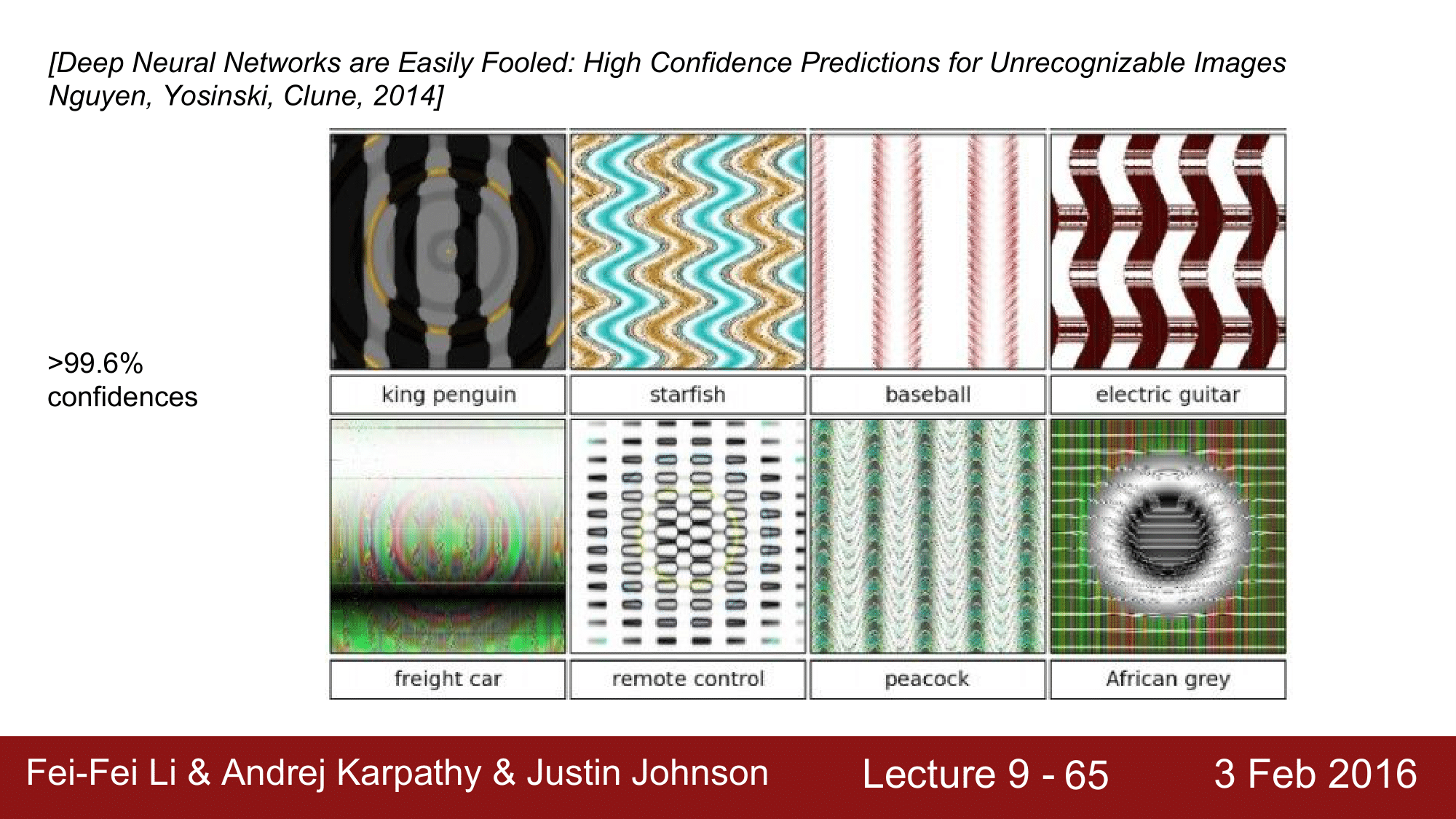
더 나아가서, 위의 특이한 패턴이나 텍스쳐들도 불가사리나 야구공으로 약 99.6%의 confidence 로 classify 하는 것을 볼 수 있습니다.
이러한 결과는 Convolution Network 에서만 있는 것이 아니라 이전의 분류 모델에서도 나타납니다.

파란색 박스가 쳐진 공룡이미지를 변형을 주어 검정 박스, 빨간 박스 이미지를 만들어 낸 것인데 모두 HOG representation 에 있어서 완전히 동일하다라고 인식하게 됩니다. 이런 것을 Adverserial examples라고 합니다.

2014년에 Goodfellow 의 위 논문을 보면, neural network 이 adverserial attack 에 취약하다는 것은 linear 한 성질 때문이다 라고 나옵니다.
이미지는 매우 고차원의 object 인데, 실제로 학습을 시키는 이미지는 통계적 구조를 가지게 되고, 이미지를 학습시키는 data manifold 에 있어서 이미지가 너무 고차원이고 gradient 는 최적화를 위해서 backpropagation 을 하면서 저차원의 통계적 구조에 involve 되게 되면서 생각하지 못했던 결과들을 낳게 될 수 있다라고 한 바 있습니다.
그래서 linear classifier 가 실제로 어떻게 문제가 될 수 있는지 한 번 살펴보겠습니다.
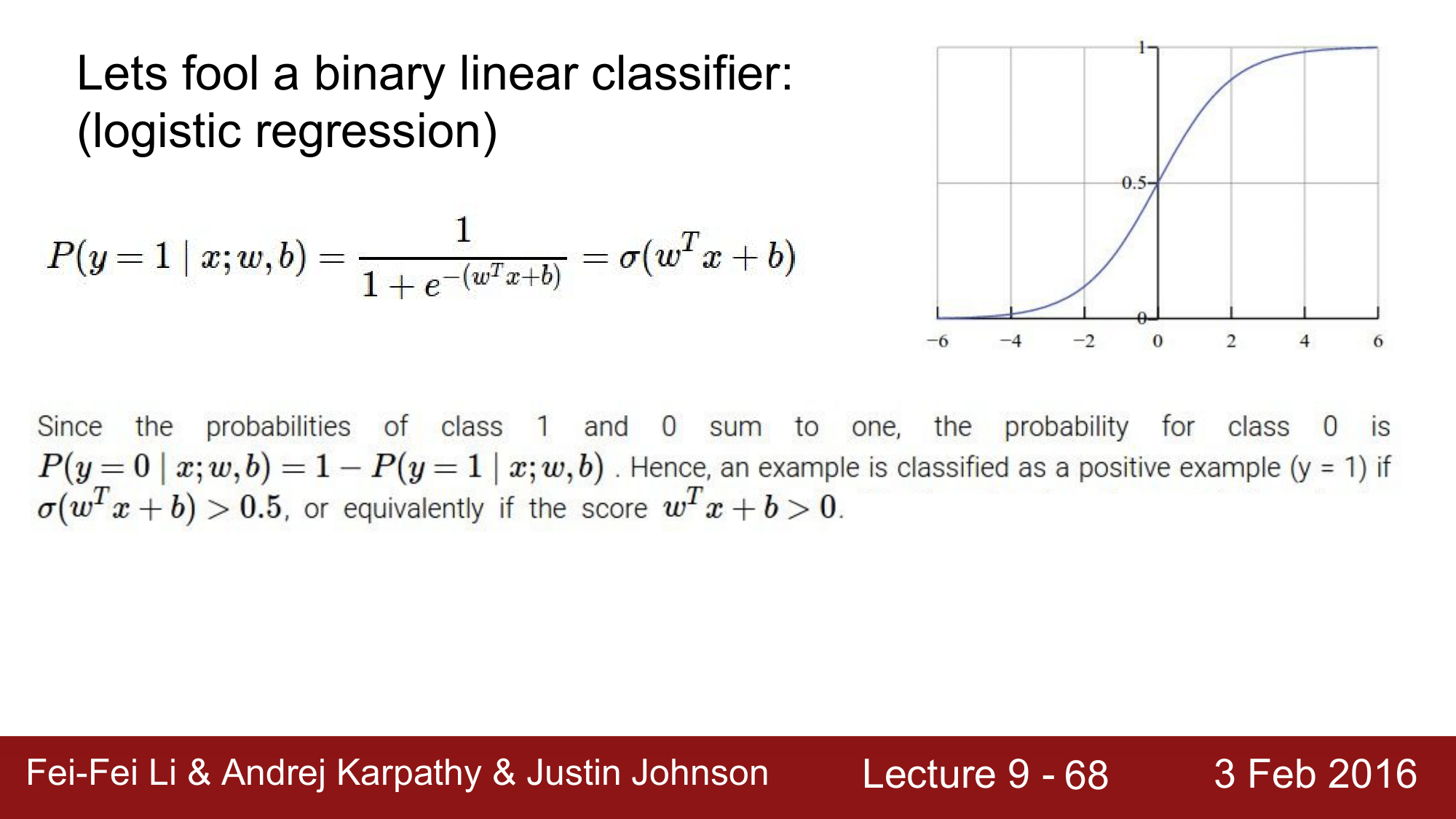
Logistic Regression 의 예로, sigmoid 함수가 있고 binary classifier 입니다. 때문에 결과가 1 또는 0으로, class 가 0 또는 1이 될 확률을 합치면 1이 될 것이고, class 0이 될 확률은 1에서 클래스 1이 될 확률을 뺀 것이 되겠습니다. 그 값이 0.5 이상이 될 경우 0으로 classify 가 된다고 생각할 수 있습니다.

위의 숫자들로 예를 들어 보겠습니다.
여기서 $w^Tx + b$를 크게 만들어야 1로 classify 가 될텐데, input이 x 이고 weight이 w 가 있을 때 class 1 의 score 는 위와 같이 됩니다.
dot product 를 하여 계산을 하게 되면 -3이 나오고, 이 값을 sigmoid 에 넣어주게 되면 0.0474라는 값이 되어 클래스 1이 될 확률이 5%가 됩니다. 반대로 클래스 0이 될 확률은 95%가 됩니다.

그래서 x를 적대적인 x 를 만들어보겠습니다.
adversarial x 를 어떻게 구성해야지 이 classifier 를 속일 수 있을까요. 가중치 w 를 보고 w > 0 인 경우에는 적대적 x 을 좀 더 크게 만들고, w < 0 인 경우는 적대적 x 를 조금 더 작게 만들어서 1에 더 가깝게 만들어 줄 수 있을 것입니다.
다만, x 를 속이기 위한 유사한 적대적 x 를 만들어야 하기 떄문에 약간의 변형만 주게 됩니다.
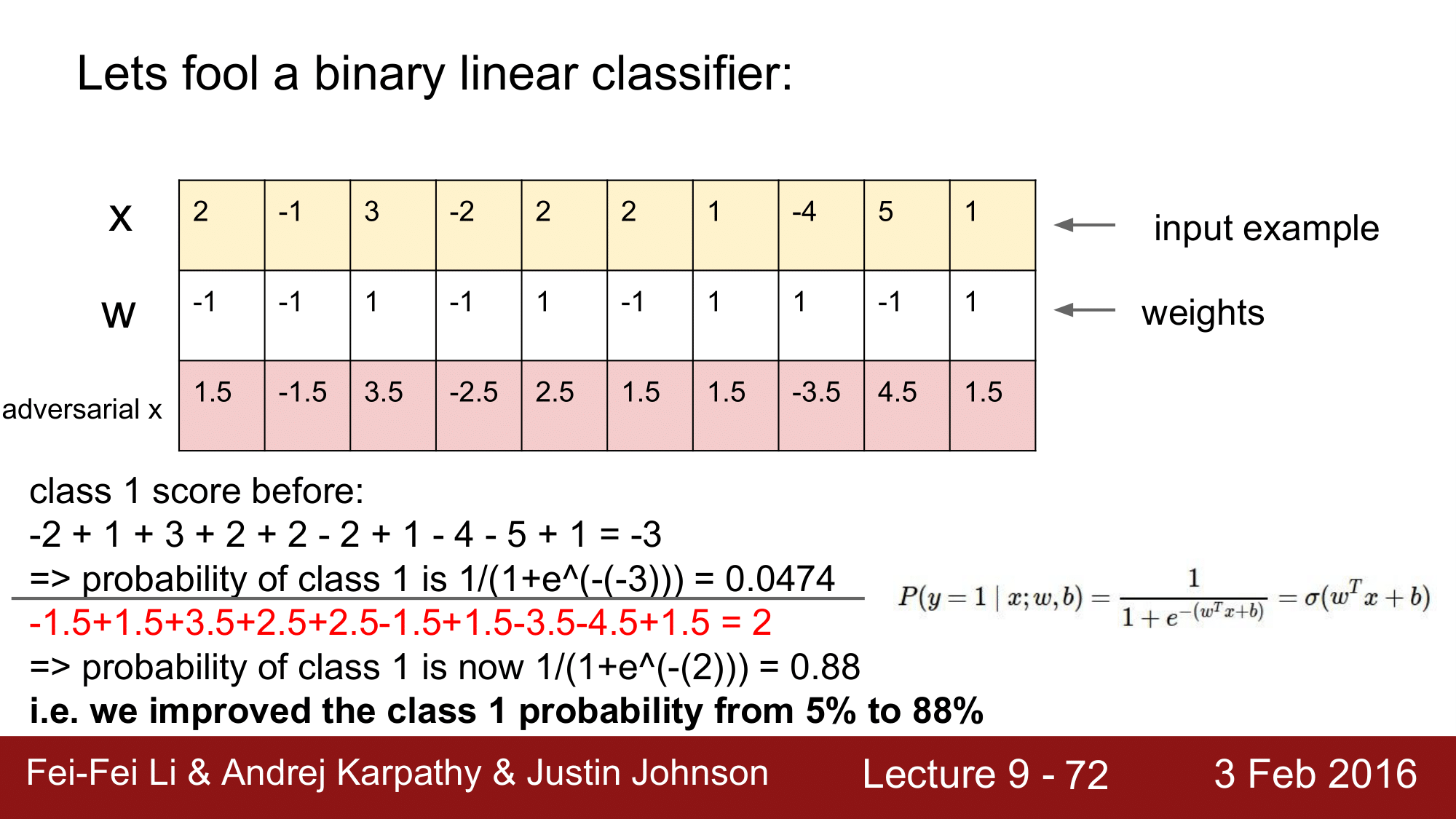
예를 들어, 음수의 가중치를 갖는 경우에는 0.5를 빼주고, 양수의 가중치를 갖는 경우는 0.5를 더해주는 식으로 0.5씩 차이를 만들어 줍니다.
이렇게 해서 계산하게 되면, 2라는 값을 얻게 되어 시그모이드 함수에 넣게 되면 0.88 이란 값을 얻게 됩니다.
결과적으로 1이 나올 확률이 5%에서 88%로 증가하는 것을 볼 수 있습니다. 즉, 원래 x 는 class 0 으로 분류가 되는 이미지였는데, 이를 class 1 으로 분류가 되도록 속인 것입니다.
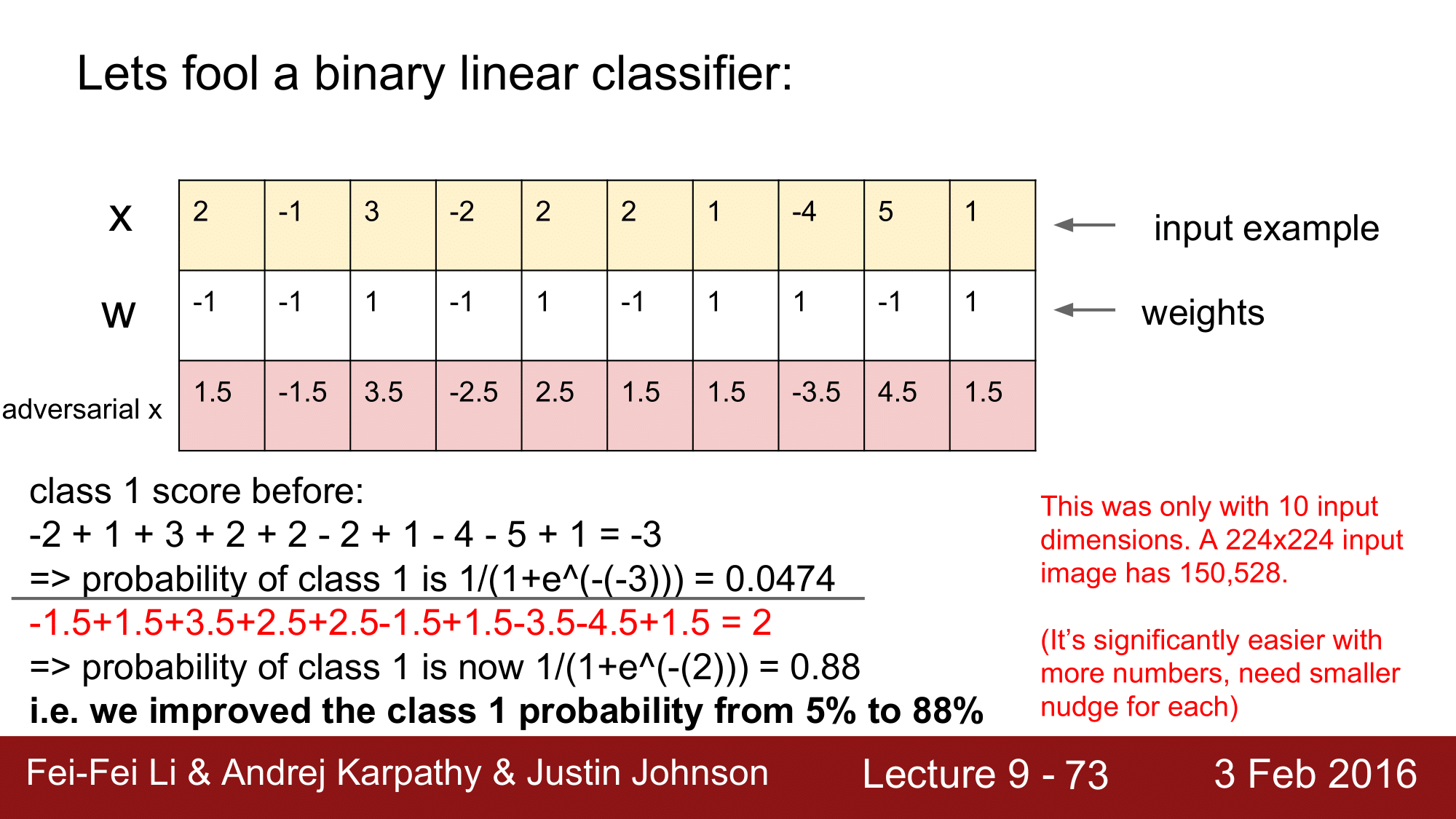
앞서 본 예시는 단지 10개의 input dimension 만 가지고 있는 경우로, 사실 이미지 같은 경우는 [224 x 224]의 식으로 굉장히 큰 차원을 가지게 됩니다. 그렇기 때문에 앞의 예에서는 0.5씩 조정을 했지만 [224 x 224]와 같은 큰 차원에서는 약간의 변화만 주게 되더라도 쉽게 adversarial x를 만들 수 있게 됩니다.
이렇게 linear regression 은 어떤 변화를 주어야 할 지 정확하게 파악하고 있는 경우라면, 아주 작은 변화만으로도 크게 변경시킬 수 있는 것이 문제가 될 수 있습니다. 그래서 딥러닝의 문제나 CNN 의 문제가 아니라 linear classifier 의 문제라고 할 수 있습니다.
이와 관련된 예를 하나 더 보겠습니다.

CIFAR-10 에서의 Linear Classifier 는 앞의 포스트에서 다룬적이 있는데, ImageNet 에 대해서도 Linear Classifier를 도출 하게 되면 아래 이미지들과 같은 결과를 얻을 수 있습니다. 여기에 adversarial example 을 적용해보겠습니다.
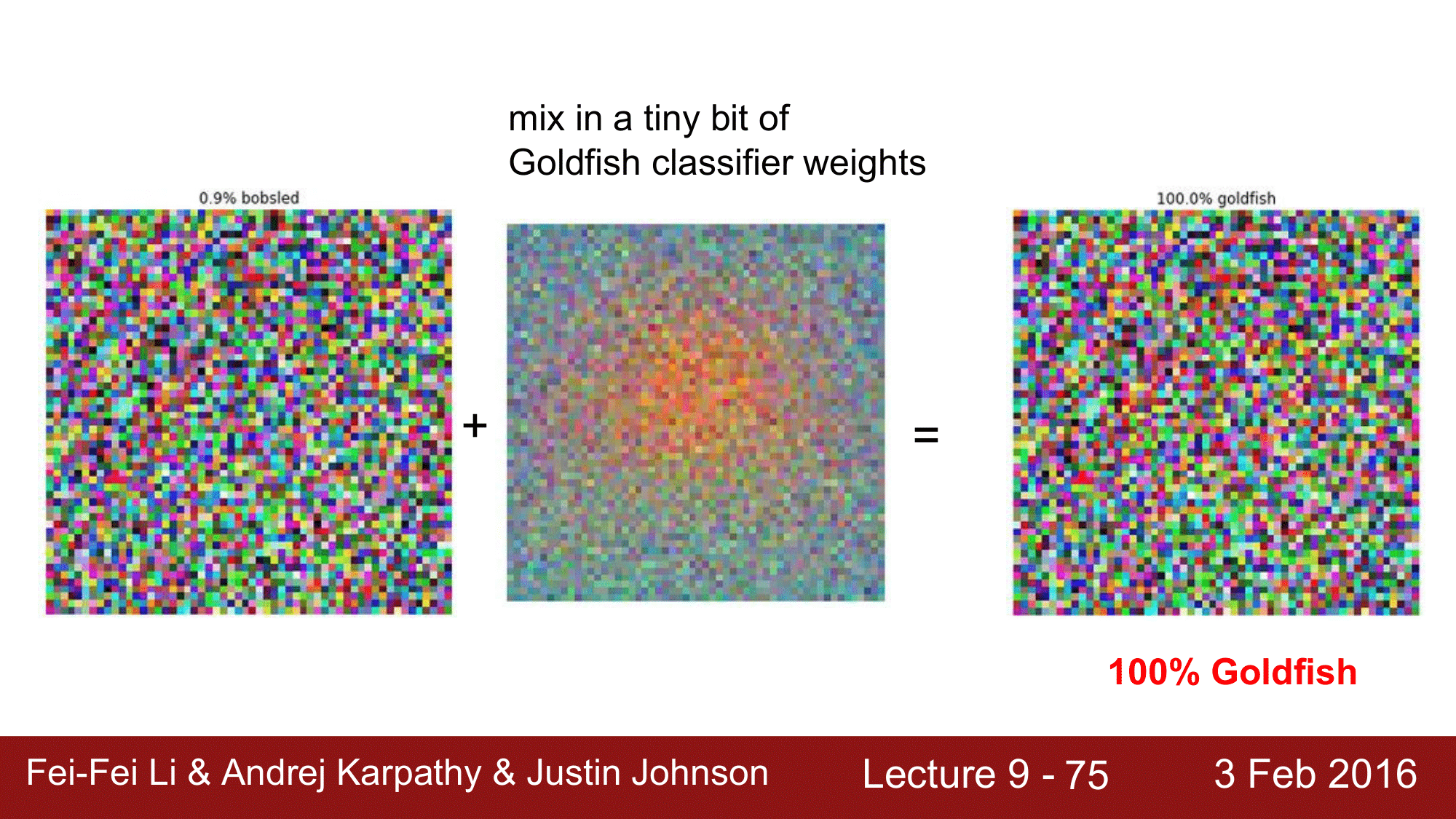
위와 같은 임의의 노이즈 패턴을 CNN 에 돌리게 되면 0.9% 의 확률로 bobsled 라고 인식했습니다. 그런데, 이미 알고 있는 goldfish 의 weight 를 약간 가미를 하게 되면 100% 로 goldfish 라고 인식하게 되는 결과가 나오게 됩니다.

위의 예시도 마찬가지로 1.0% 의 확률로 kit fox 라고 Classify 했는데, 여기에 goldfish 의 weight 을 약간 가미해줌으로써 8.0%의 goldfish 로 인식하게 됩니다.

이 예시 역시 앞에서의 설명과 같이 동작하는 것을 볼 수 있습니다.

다시 한번 강조하자면, Adversarial examples는 비록 Convolution 을 하면서 처음 보긴 했지만, Deep Learning 이나 Convolution 의 문제가 아니라, 기본적으로 Linear Classifier 의 문제라는 것입니다. 더 나아가서, 이는 이미지에 국한되는 문제도 아닙니다. 이미지 외의 어떤 Modality 에 대해서도 발생할 수 있는 것으로, speach recognition 과 같은 모든 분야에서 발생할 수 있는 문제라는 걸 알고 넘어가면 좋을 듯합니다.
앞서 본 adversarial examples 과 같이 적대적인 공격에 대해, 이를 방지할 수 있는 정답은 아직 명확하게 나와있는 상태가 아니라 지금도 활발하게 연구가 되고 있는 분야입니다. 이를 막을 수 있는 counter measure 로는 기본적으로 class 의 수가 많게 하거나, adversarial example 을 의도적으로 생성하여 학습데이터에 넣어주고, 해당 적대적 예시에 대해서 negative class 로 분류하게 해주는 방법이 있습니다. 이러한 방법은 근본적인 해결책이라고는 할 수 없습니다. 또 다른 방법으로는 Linear function 을 사용하지 않고 다른 방법을 시도하는 것도 갸능할 수 있겠지만, 현재로써는 Linear function 을 빼게되면 공격에는 robust 해지긴 하지만, classify 의 capacity 가 떨어질 수 있는 문제점이 있습니다.
 있는 정답은 아직 명확하게 나와있는 상태가 아니라 지금도 활발하게 연구가 되고 있는 분야입니다. 이를 막을 수 있는 counter measure 로는 기본적으로 class 의 수가 많게 하거나, adversarial example 을 의도적으로 생성하여 학습데이터에 넣어주고, 해당 적대적 예시에 대해서 negative class 로 분류하게 해주는 방법이 있습니다. 이러한 방법은 근본적인 해결책이라고는 할 수 없습니다. 또 다른 방법으로는 Linear function 을 사용하지 않고 다른 방법을 시도하는 것도 갸능할 수 있겠지만, 현재로써는 Linear function 을 빼게되면 공격에는 robust 해지긴 하지만, classify 의 capacity 가 떨어질 수 있는 문제점이 있습니다.
있는 정답은 아직 명확하게 나와있는 상태가 아니라 지금도 활발하게 연구가 되고 있는 분야입니다. 이를 막을 수 있는 counter measure 로는 기본적으로 class 의 수가 많게 하거나, adversarial example 을 의도적으로 생성하여 학습데이터에 넣어주고, 해당 적대적 예시에 대해서 negative class 로 분류하게 해주는 방법이 있습니다. 이러한 방법은 근본적인 해결책이라고는 할 수 없습니다. 또 다른 방법으로는 Linear function 을 사용하지 않고 다른 방법을 시도하는 것도 갸능할 수 있겠지만, 현재로써는 Linear function 을 빼게되면 공격에는 robust 해지긴 하지만, classify 의 capacity 가 떨어질 수 있는 문제점이 있습니다.
있는 정답은 아직 명확하게 나와있는 상태가 아니라 지금도 활발하게 연구가 되고 있는 분야입니다. 이를 막을 수 있는 counter measure 로는 기본적으로 class 의 수가 많게 하거나, adversarial example 을 의도적으로 생성하여 학습데이터에 넣어주고, 해당 적대적 예시에 대해서 negative class 로 분류하게 해주는 방법이 있습니다. 이러한 방법은 근본적인 해결책이라고는 할 수 없습니다. 또 다른 방법으로는 Linear function 을 사용하지 않고 다른 방법을 시도하는 것도 갸능할 수 있겠지만, 현재로써는 Linear function 을 빼게되면 공격에는 robust 해지긴 하지만, classify 의 capacity 가 떨어질 수 있는 문제점이 있습니다.
있는 정답은 아직 명확하게 나와있는 상태가 아니라 지금도 활발하게 연구가 되고 있는 분야입니다. 이를 막을 수 있는 counter measure 로는 기본적으로 class 의 수가 많게 하거나, adversarial example 을 의도적으로 생성하여 학습데이터에 넣어주고, 해당 적대적 예시에 대해서 negative class 로 분류하게 해주는 방법이 있습니다. 이러한 방법은 근본적인 해결책이라고는 할 수 없습니다. 또 다른 방법으로는 Linear function 을 사용하지 않고 다른 방법을 시도하는 것도 갸능할 수 있겠지만, 현재로써는 Linear function 을 빼게되면 공격에는 robust 해지긴 하지만, classify 의 capacity 가 떨어질 수 있는 문제점이 있습니다.