
해당 포스트는 송교석 님의 유튜브 강의를 정리한 내용입니다. 강의 영상은 여기에서 보실 수 있습니다.
Localization and Detection

이번 포스트에서 살펴볼 것은 Localization 과 Detection 입니다.
Computer Vision Tasks
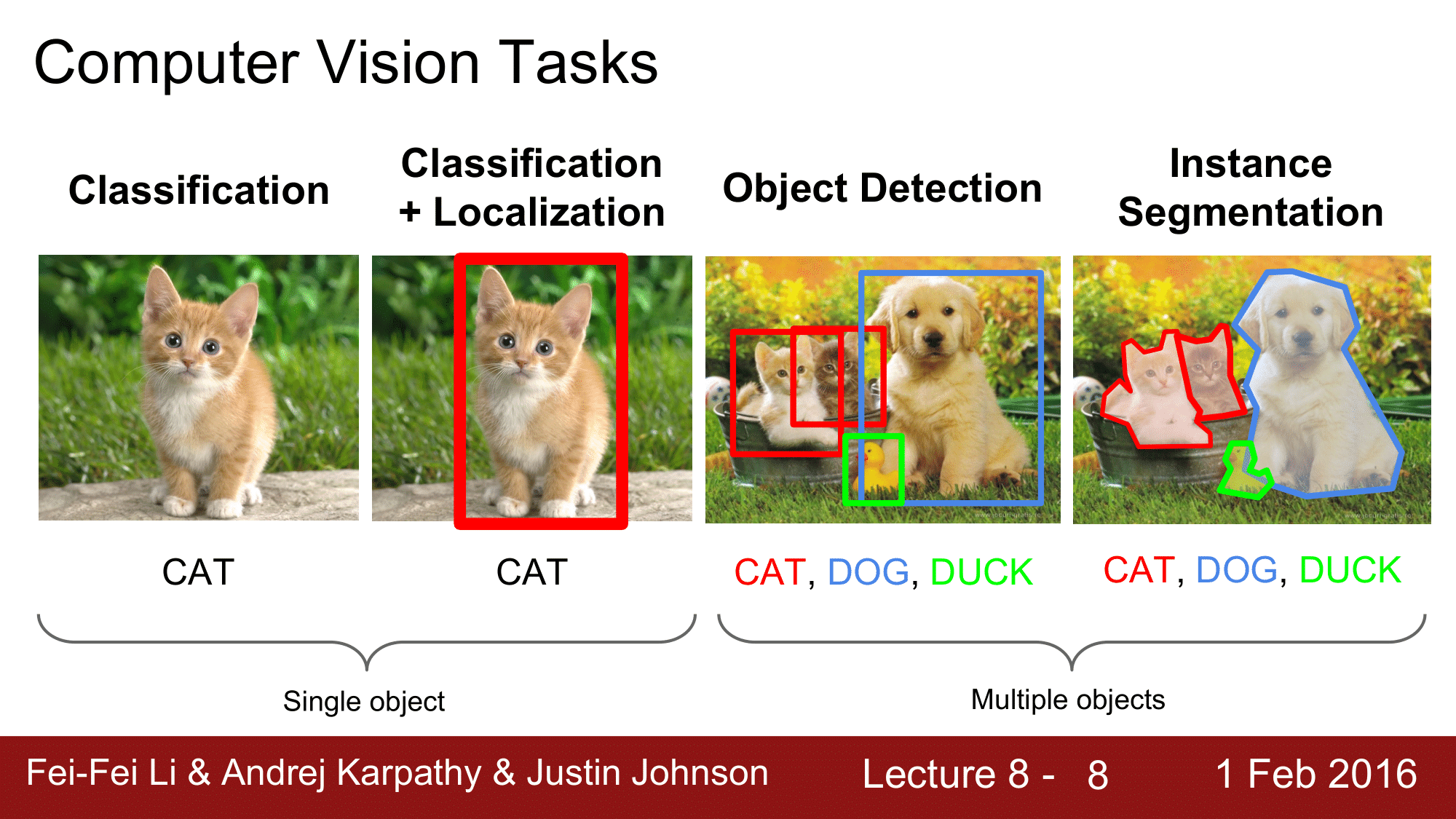
우선, 유사한 개념들의 차이점을 정리해보고 들어가도록 하겠습니다.
Classification 은 이미지가 들어오면 이 이미지가 어떠한 이미지인지, 예를 들어 위의 그림과 같이 CAT 이라고 labeling 해주는 것 입니다.
Classification + Localization 은 분류와 함께, Localization 을 진행하는 것인데, CAT 이 이미지의 어디에 위치해 있는지를 Boxing 해주는 것을 localization 이라고 합니다.
다음으로, Detection 이라는 것은 하나의 object 를 boxing 해주는 localization 과는 다르게 여러개의 Object 들을 모두 찾아내는 것을 Object Detection 이 되겠습니다.
마지막으로 Segmentation 은 위 그림과 같이 고양이, 오리, 개를 형상대로 테두리를 따 주는 것을 말합니다.
그래서 이번 포스트에서는 Localization 과 Detection 에 대해 다뤄보고, Segmentation 은 후에 Lecture 13 에서 다뤄보도록 하겠습니다.
Localization

Classification 은 C 클래스가 있을 떄 input 으로 이미지를 받아서 output 으로 Class label 을 줍니다. 그리고 이를 평가하는 지표는 Accuracy(정확도)가 됩니다. 위 그림에서 처럼 이미지가 들어왔을 떄 고양이다 라고 분류를 하는 식으로 동작합니다.
Localization 은 이미지가 들어오면 결과로 Label 이 아닌 Box를 리턴합니다. 예를 들어 left top 에서 시작하는 (x, y) 좌표와 width, height 를 주게 되는 것 입니다. 그리고 평가 지표는 IoU(Intersaction over Union). 즉, 겹치는 부분이 몇 퍼센트인지 가 됩니다.
그리고 Classification 과 Localization 을 같이 진행하게 되면, Label 과 (x, y, w, h) 를 같이 얻게 되는 것 입니다.

이전 포스트들에서 계속 언급했던 ImageNet 에는 Classification 대회만 있는 것이 아니라 여러가지 대회가 있는데, 그 중 하나가 Classification 과 Localization 을 결합한 것이 되겠습니다.
여기서도 마찬가지로 1,000 개의 Class 들이 있고, 각 이미지들에는 1개의 Class 와 최소 1개의 bounding box 가 있습니다. 그리고 Classification 에서 와 같이 top 5 error 를 계산했던 것 처럼, 5개의 후보를 추출하여 최소한 1개의 Class 를 맞추고, IoU 가 0.5 이상이 되면 맞춘걸로 간주합다고 합니다.
Idea 1. Localization as Regression
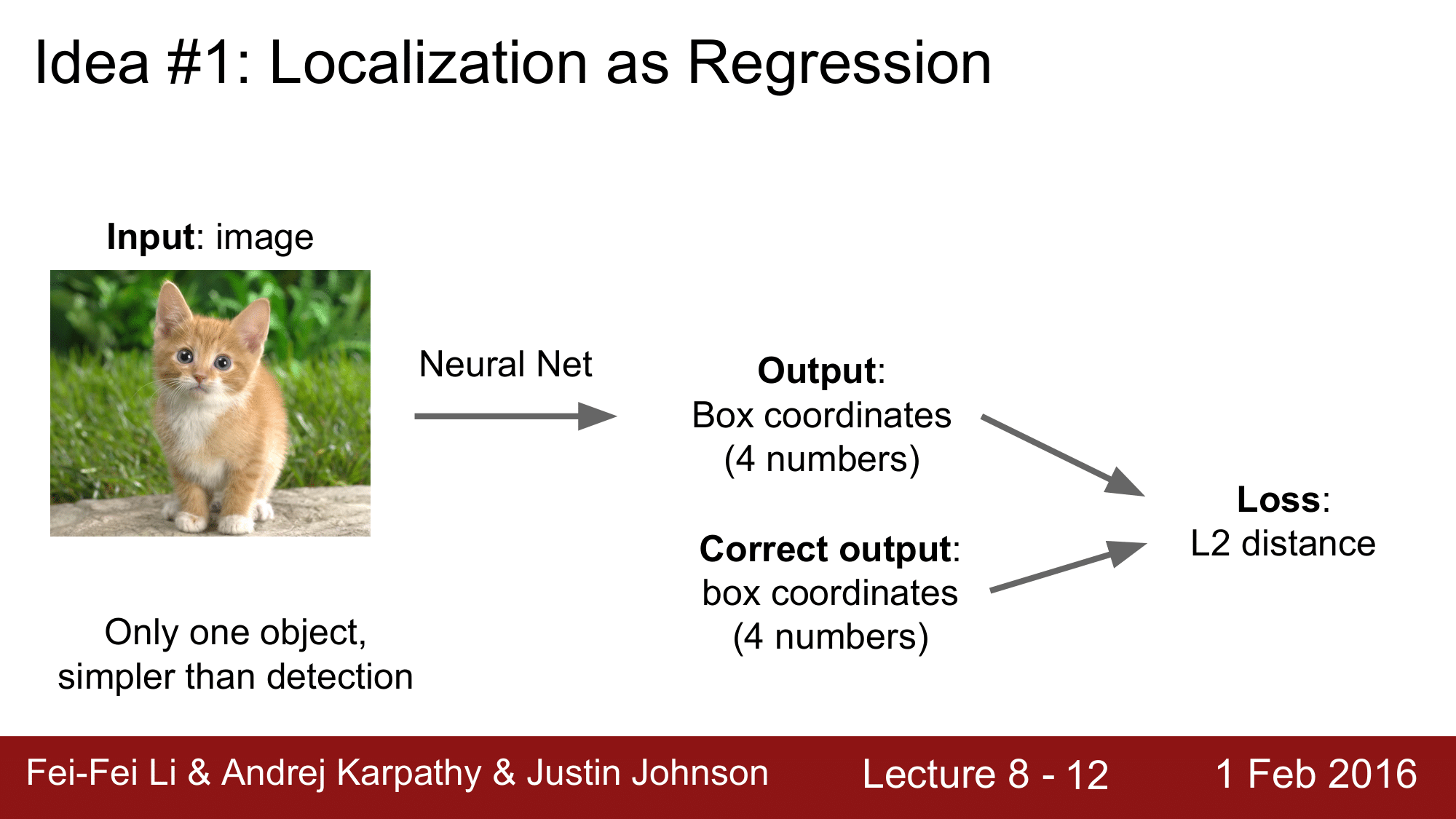
Localization 을 하는 방법에는 크게 2가지가 있습니다. 그 중 첫 번째 방법은 Localization as Regression 입니다. 즉, Localization 을 Regression 이라고 간주하는 것인데, 이 방법은 나름 매우 강력합니다.
1개를 localize 하거나 $k$ 개를 localize 할 때, Image Detection 을 고집하지 않고 이 방법을 사용해도 된다는 의미입니다.
방법은 다음과 같습니다.
- 이미지를 input 으로 받아 신경망에 넣어줍니다.
- output 으로 4개의 숫자로 구성된 box 의 좌표를 얻습니다.
- 이를 실제 correct box 좌표와 비교를 하여 L2 Distance 를 활용한 Loss 를 구하게 됩니다.
- 이렇게 구한 Loss 를 Backpropagation 때 학습하여 최적화합니다.
단계별로 보면 다음과 같습니다.

첫 번째 단계에서는 Classification model 을 학습시킵니다.
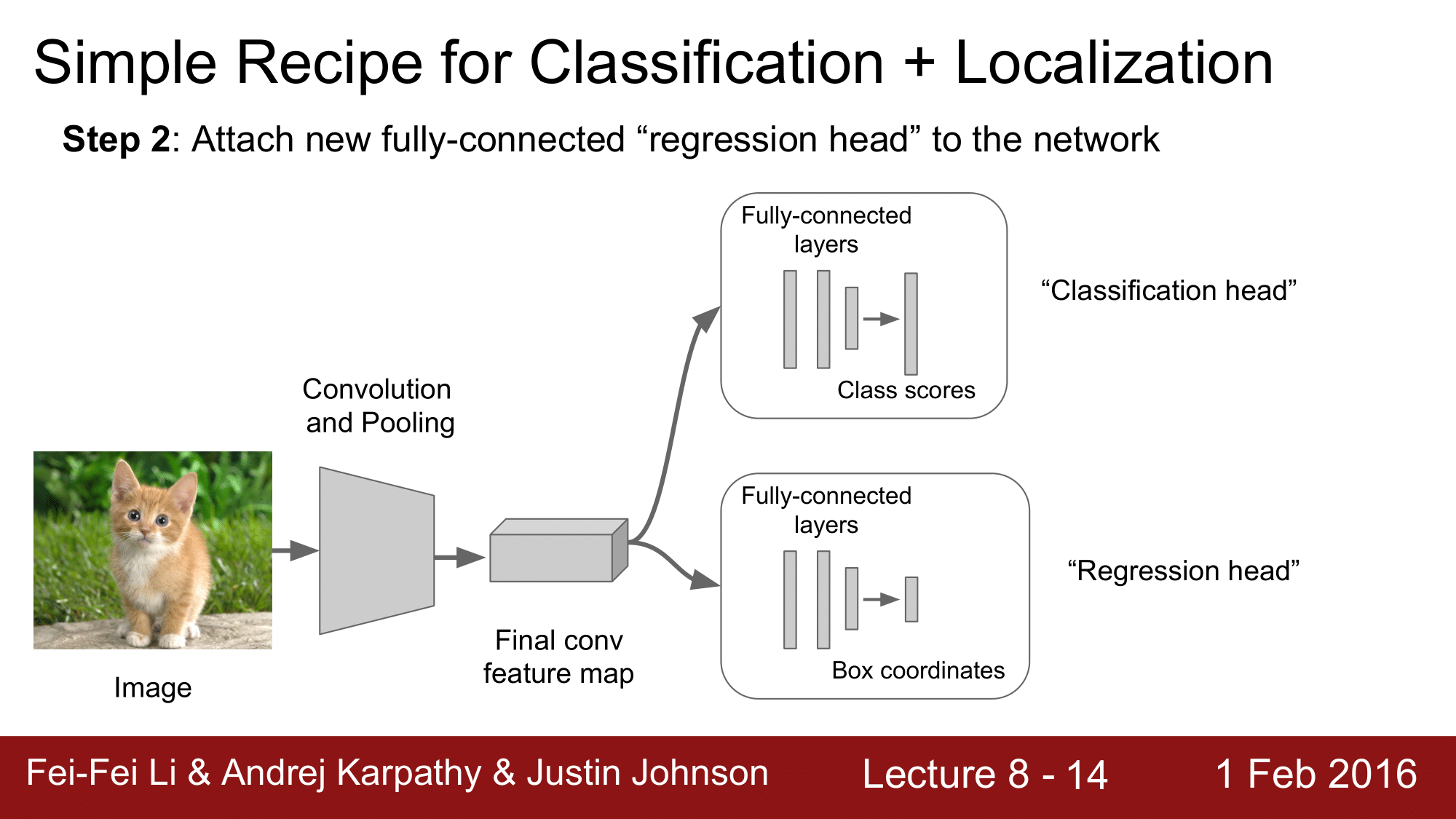
두 번째 단계에서는 지금까지 해왔던 Classification head 에 Regression head 를 추가 해줍니다.
그래서 Regression head 에서는 결과물이 박스의 좌표가 되도록 합니다.

세 번째 단계에서는 방금 앞에서 추가했던 Regression head 부분만 학습을 진행합니다.
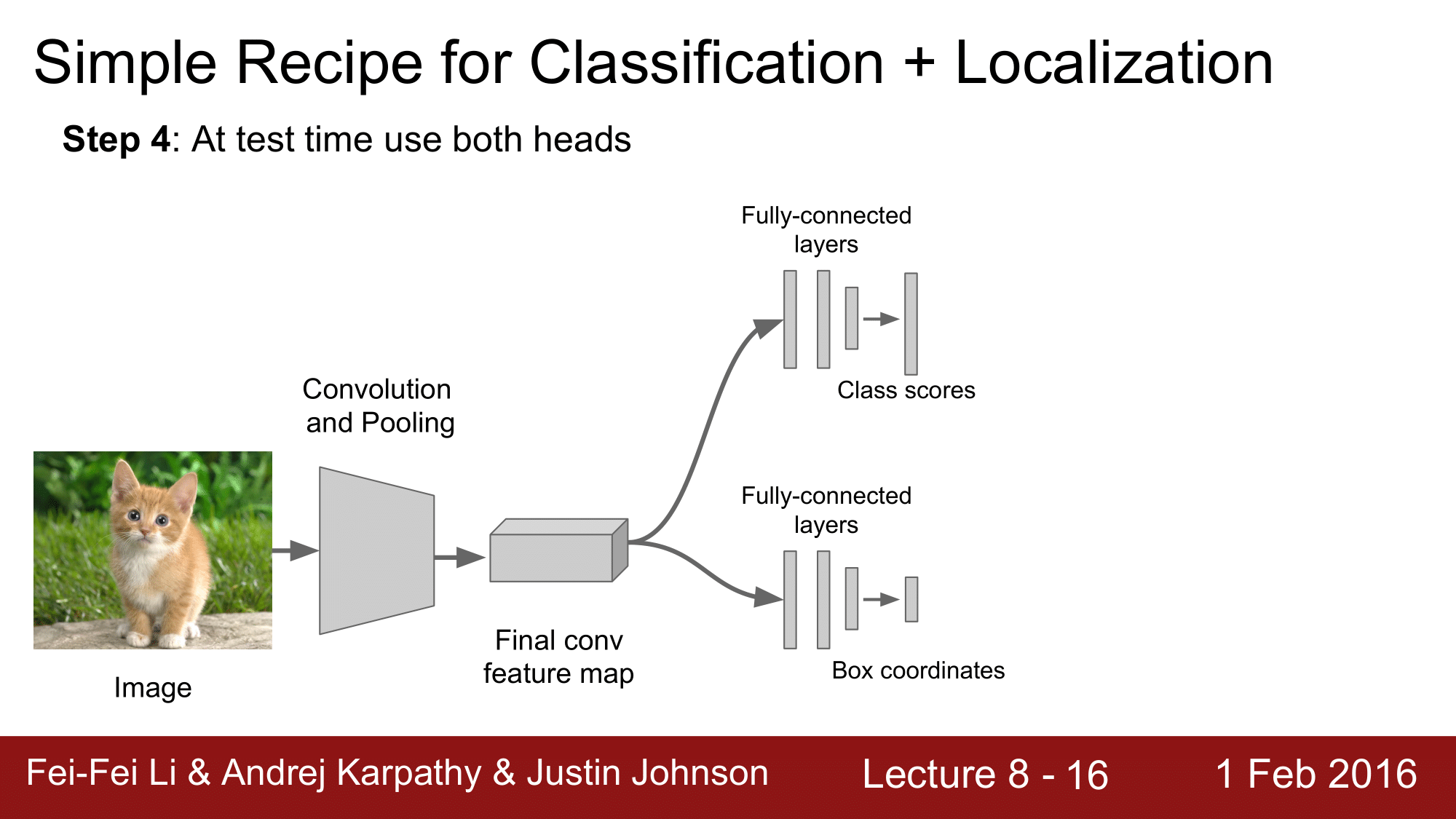
그리고 마지막 단계에서는 Classification head 와 Regression head 모두를 이용해서 결과물을 산출해냅니다.
이처럼 간단하게 구성이 됩니다.

그런데, Regression head 부분에는 Per-class 와 Class agnostic 이라는 2 가지 방법이 있습니다.
쉽게 말하면, Per-class 는 어떤 Class 에 특화된, Class Specific 한 방법이고, Class agnostic 이라는 것은 각각의 Class 와 무관하게, 범용적인 접근 방법이라고 할 수 있습니다.
class agnostic 은 특정 class 에 특화되지 않기 떄문에, 하나의 box 만을 결과물로 도출하게 됩니다.
반면에, per-class 즉, class specific 은 각 class 당 하나의 box. 즉, 4개의 숫자가 각 class 별로 결과를 도출하게 됩니다.
이 두가지 방법은 loss 를 계산하는 방법 외에는 별 차이가 없는 굉장히 유사한 방법입니다. 다만, loss 계산에서 class specific 한 방법은 Ground-truth 의 좌표만 이용한다는 차이만 있습니다.
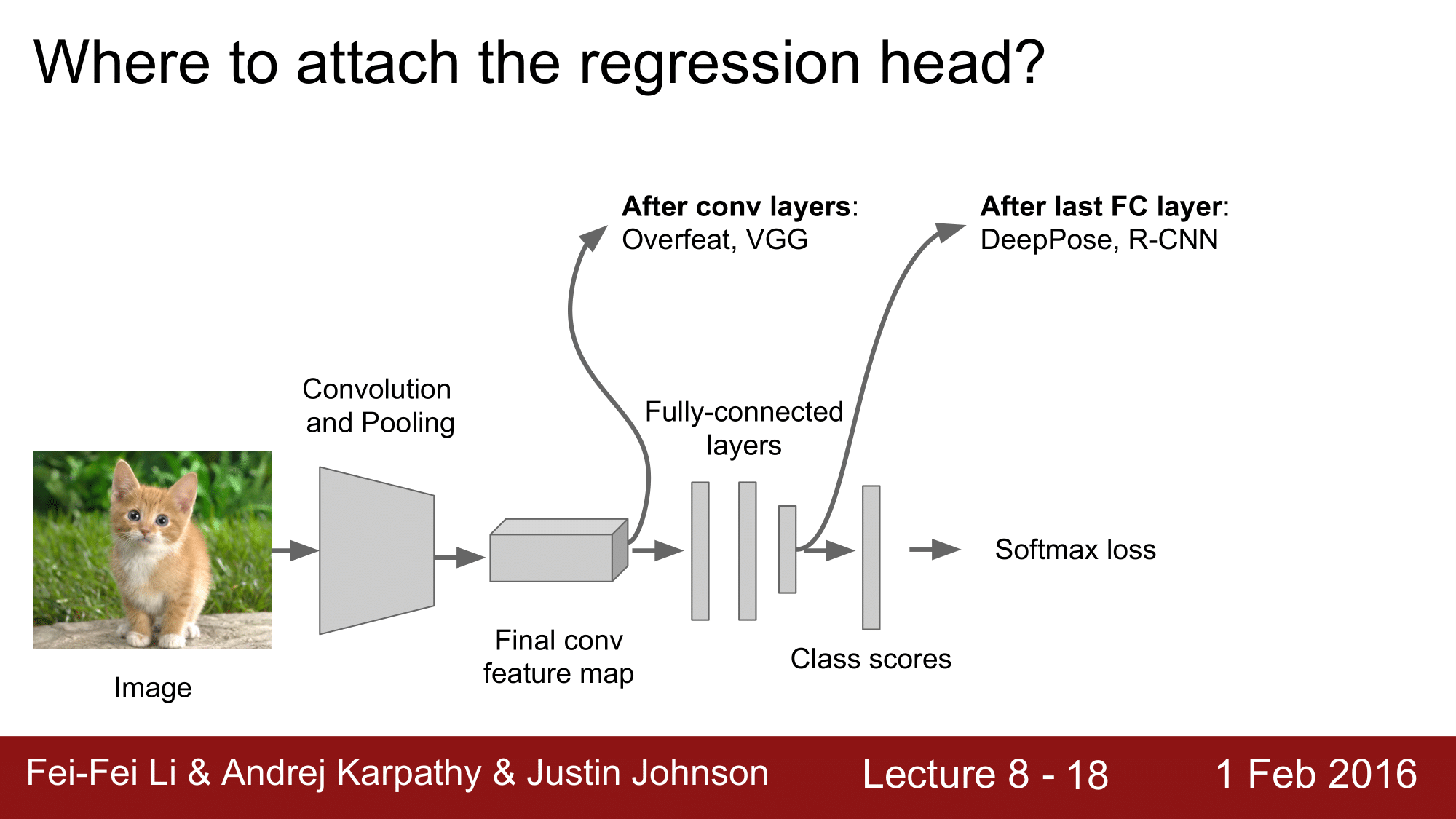
그렇다면, Regression head를 어디에 붙여야하는지에 대해서 보겠습니다.
이것도 두 가지 방법이 있는데, 두 가지 방법 모두 통합니다.
첫 번째로, 마지막 CONV. Layer 뒤에 붙여주는 방법이 있습니다. Overfeat 이나 VGG 같은 경우 이렇게 합니다.
아니면, FC. Layer 뒤에 붙여주는 방법이 있습니다. DeepPose 나 R-CNN 같은 경우가 이런 경우인데, 어떤 경우든 잘 동작합니다.
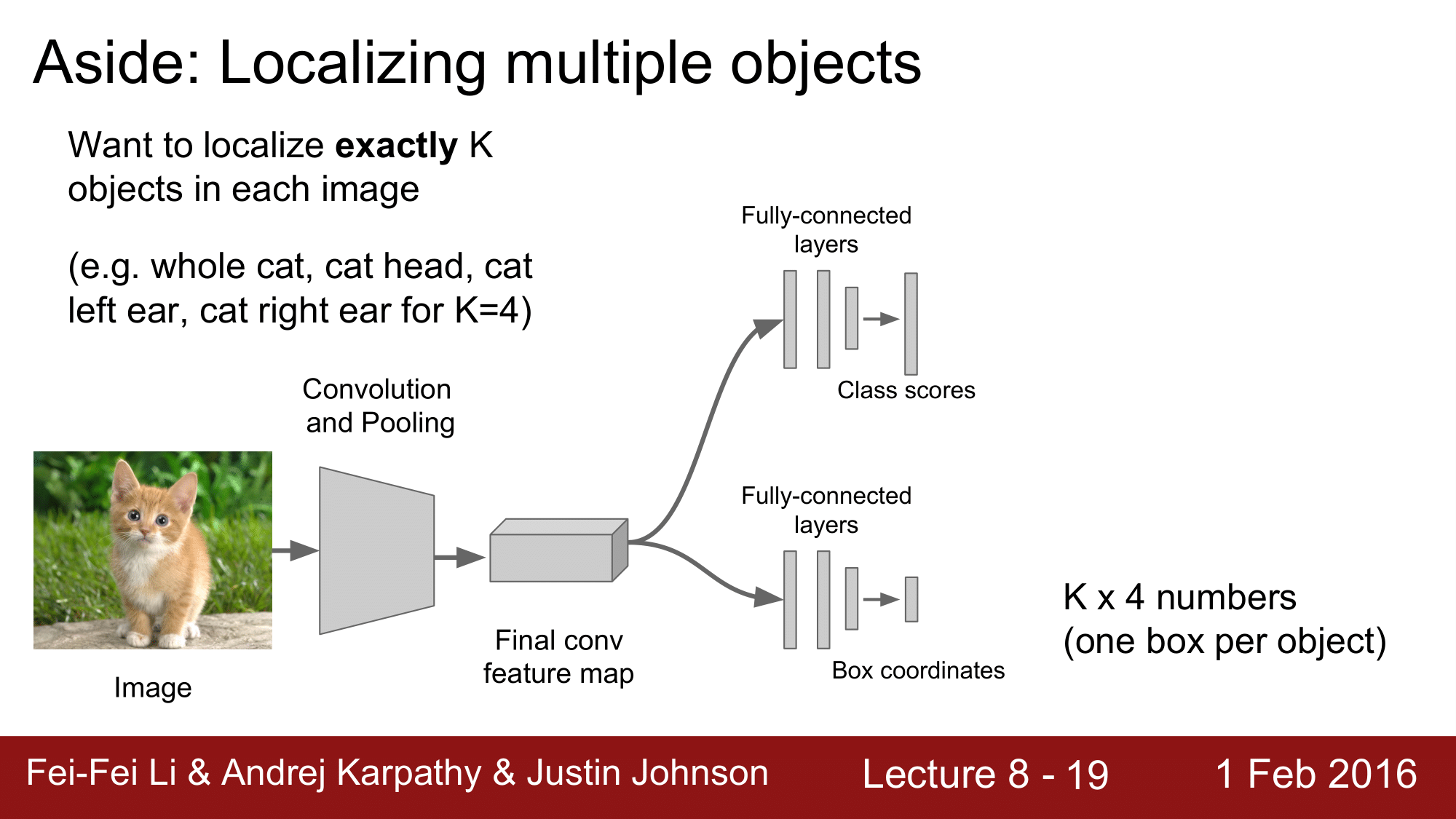
참고로 여러개 Object 의 Localizing 도 잘 동작합니다.
정해진 $K$ 개의 Object 를 찾아내는 것은 Regression 만으로도 잘 동작하기 때문에, 굳이 모든 것을 찾아내야하는 경우가 아니고 정해진 개수만 찾아내면 되는 경우라면 Detection 을 사용하지 않고, Regression 만을 이용해서 쉽게 구현이 가능하다는 것 입니다.
이러한 예로 사람의 자세를 측정하는 것이 있습니다.

사람의 관절 수는 정해져 있기 때문에, Regression 을 통해 쉽게 구현이 가능합니다.

정리하자면, Regression 을 통해서 Localization 을 하는 것은 매우 Simple 하고, 나름 강력하기 때문에 여러 사례에 충분히 응용하기 쉽습니다. 다만, ImageNet Competition 과 같은데에서 수상이 목적이라면, 좀 더 복잡한 방법을 사용해야 할 것입니다. 바로 다음으로 살펴볼 sliding window 가 그것입니다.
Idea 2. Sliding Window

지금부터, Localization 을 하는 두 번째 방법인 Sliding Window 에 대해서 알아보겠습니다.
기본적으로 앞의 Regression 방법과 동일하게, Classification head와 Regression head 두 개로 분류해서 진행을 합니다만, 이미지를 한번만 돌리지 않고 이미지 여러 군데를 돌려 합쳐주는 기법입니다.
그리고 또한, 편의성을 위해 FC. Layer 를 CONV. Layer 로 변환해주어 연산을 진행하게 됩니다.
Sliding Window 의 대표적인 것이 overfeat 이므로, overfeat 에 대해서 알아보도록 하겠습니다.
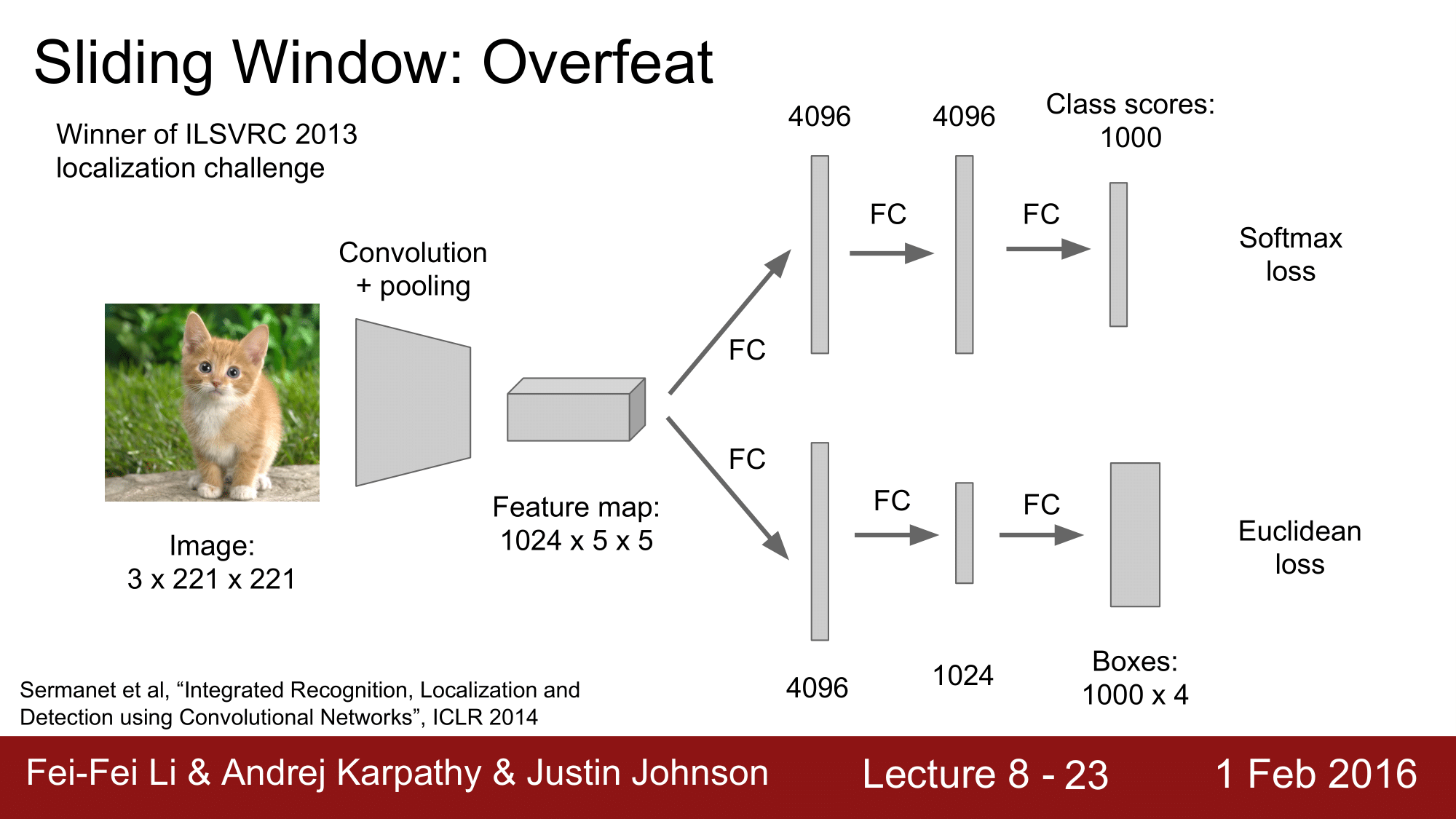
Overfeat 은 2013년 ImageNet Localization Challenage 에서 5승을 한 모델로, 기본적으로는 AlexNet 을 응용한 것 입니다.
Classification head 와 Regression head 두 개로 구성이 되는데, sliging window 에서의 차이점은 다음과 같습니다.

input 이미지보다 좀 더 큰 이미지로 진행합니다.
가운데 이미지에서 검은색 box 가 sliding window 가 됩니다. 이 sliding window 가 위치한 left top 에서 regression head 로 빨간색의 bounding box 를 만들게 되고, classification head 에 의해서 고양이로 분류하는 score 를 계산해주게 됩니다. 오른쪽 그림이 left top 에서의 score 입니다.
이렇게 right bottom 까지 진행을 하게 되면, 다음과 같이 됩니다.

결과적으로 얻게되는 것은, 아래 그림과 같이 4개의 bouding box 와 4개의 score 가 됩니다.

여기에서 알고리즘을 상세하게 설명하지는 않지만, 다음과 같이 합칩니다.

이렇게 단일 bouding box 와 단일 score 를 얻는 것이 최종적인 결과가 되겠습니다.
이 예제에서는 간단하게, 슬라이딩 윈도우를 4개로 구성하여 진행했는데, 실제로는 훨씬 더 많은 슬라이딩 윈도우를 사용합니다.

위 그림을 보시면, 수십에서 수백개의 슬라이딩 윈도우를 사용하고 결과적으로 스코어 맵을 작성한 것을 볼 수 있습니다.
최종 결과를 보게 되면, 이미지가 곰인 것을 확인 할 수 있는데, score map 을 보게 되면 곰이 있는 부분의 socre 가 높게 표시되는 것을 확인할 수 있습니다.
box 또한 곰 쪽으로 몰려 있는 것을 확인할 수 있습니다.
결과적으로는, 곰을 bounding box 가 정확하게 포착한 것도 확인할 수 있습니다.
그런데 이렇게 수 많은 슬라이딩 윈도우를 사용하게 되면, 각각의 슬라이딩 윈도우에 대해서 network 를 돌려야 하기 때문에 연산비용이 많이 들어가게 됩니다.
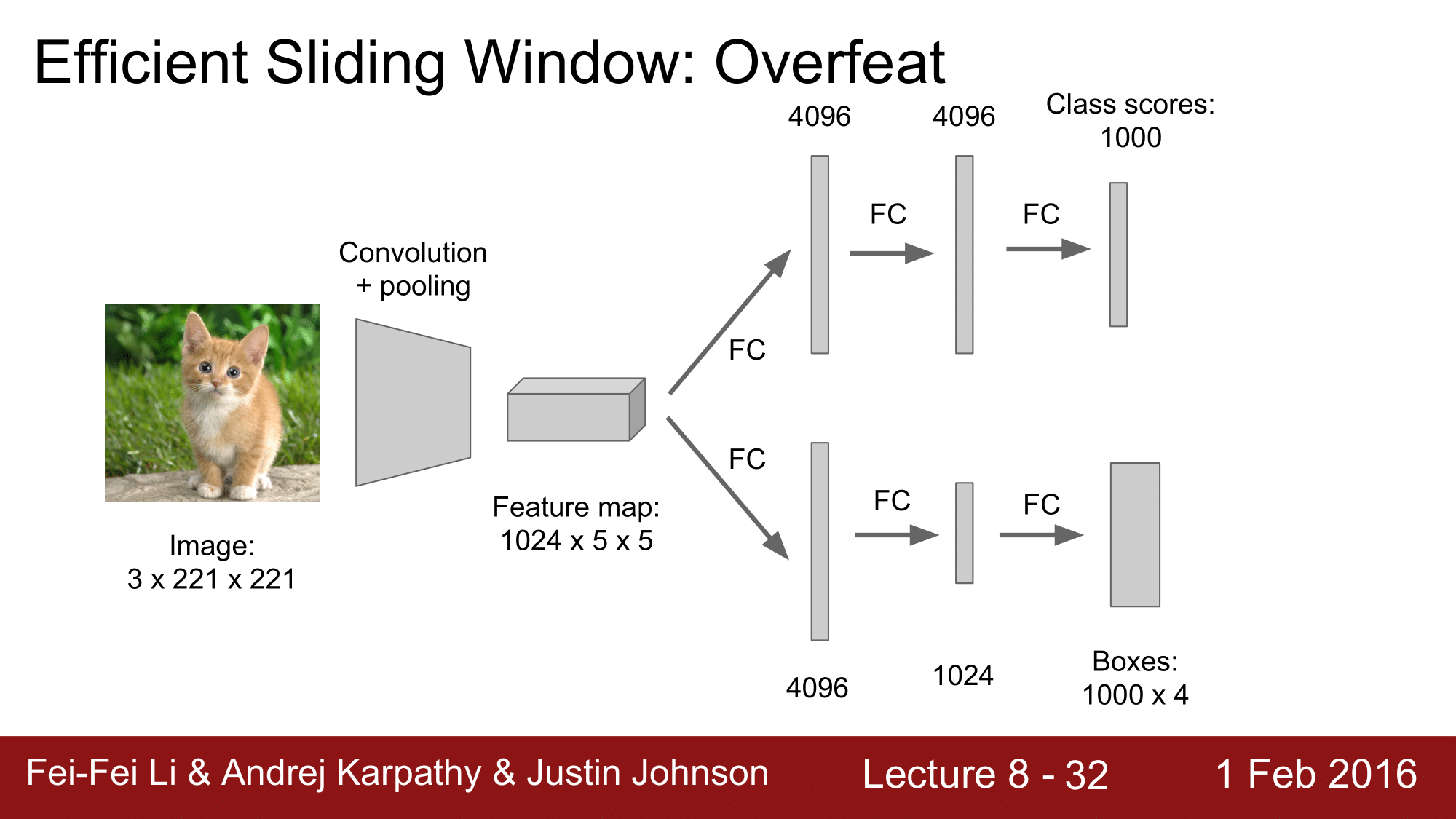
연산비용이 많이 들기 때문에, 뒷단에서 FC. Layer 를 CONV. Layer 로 바꿔준다는 것 입니다.
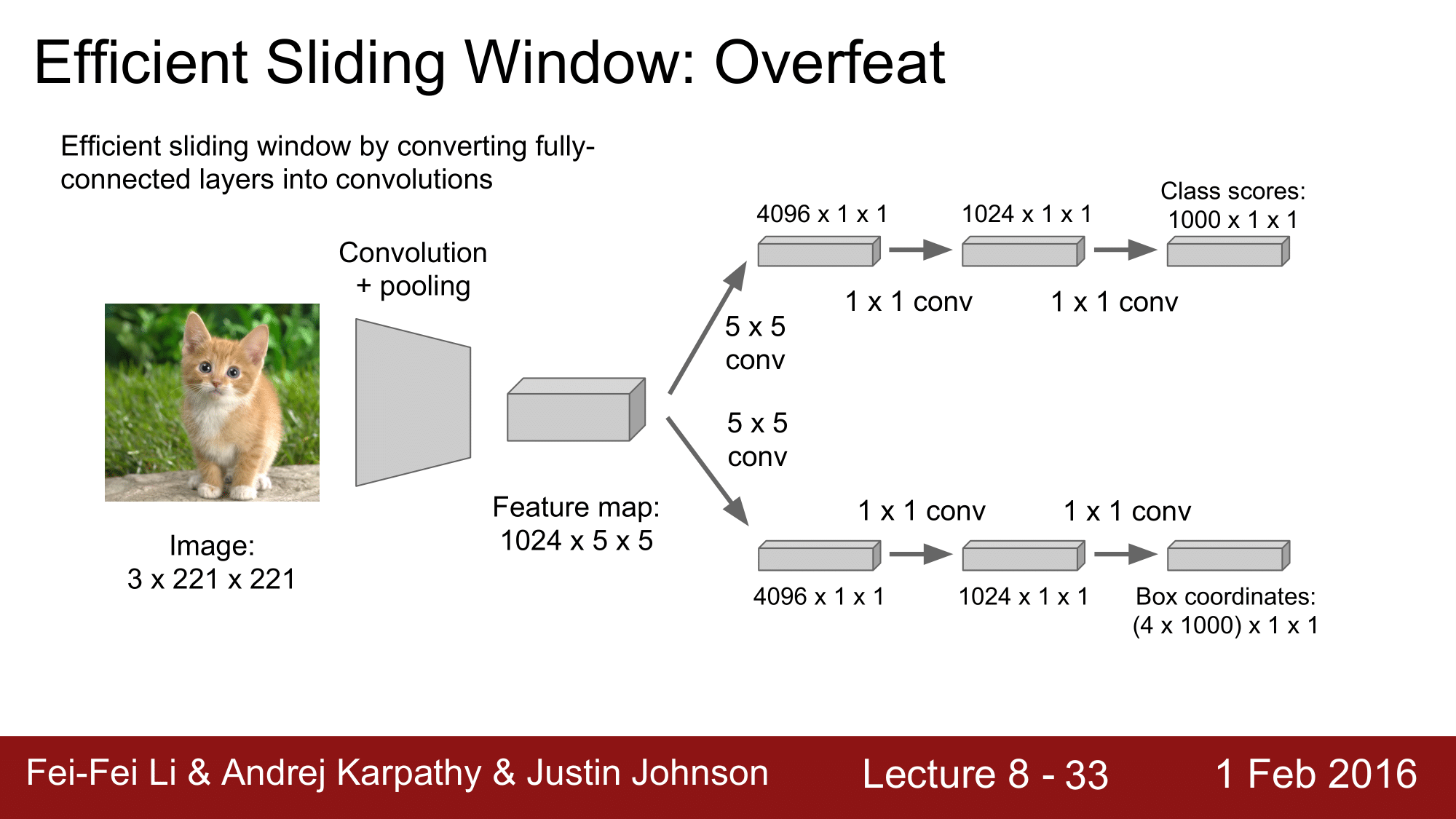
이렇게 CONV. Layer 로 바꿔주어 연산을 더 효율적으로 진행한다는 것 입니다.
기본적으로 앞에서의 FC. Layer 는 4096개로 구성이 되어있었습니다. 이를 vector 로 생각하는 것이 아닌, 또 하나의 Convolutional feature map 으로 생각한다는 것 입니다.
그래서 이를 transpose 해주고, 1 x 1 의 차원을 추가해줌으로써 이렇게 CONV. Layer 로 구성하는 것 입니다.
이처럼 FC. Layer 를 CONV. Layer 로 만들어줌으로써, CONV, POOL, element-wise operation으로 만 네트워크를 구성할 수 있는 것 입니다.

트레이닝 시에는, 14 x 14의 이미지를 받아서 5 x 5의 필터로 Convolution 을 해주게 되면, (14 - 5)/1 + 1 = 10이므로 10 x 10이 되고, 이것을 2 x 2 필터로 Poolling 해주면 5 x 5의 결과를 얻게 됩니다.
여기서부터 우측을 모두 convolution 으로 바꾸었기 때문에, (5 - 5)/1 + 1 = 1로 1 x 1 크기로 변환되는 것을 볼 수 있습니다.
테스트 때는, 좀 더 큰 이미지인 16 x 16의 이미지로 진행하여 2 x 2 크기의 결과를 얻게 됩니다.

ImageNet 에서의 Classification + Localization 성적을 보게되면, 2012년에는 AlexNet, 2013년에는 지금까지 본 Overfeat, 2014년에는 VGG 가 우승을 한 것을 볼 수 있습니다.
2015년의 ResNet 은 152개의 layer 로 구성이 되어 있으면서, 깊이도 깊어졌지만 기본적으로는 localize 하는 방법 자체를 바꿨습니다.
RPN(Regional Proposal Network)이라는 것을 이용하여, 기존과는 비교가 안되는 정확도로 localization을 수행한 것을 볼 수 있습니다.

지금까지 Classification + Localization 에 대해서 살펴보았습니다.
이제부터는 Object Detection. 즉, 한 이미지 내에서 불특정 여러개의 이미지를 인식하는 것에 대해서 학습해보겠습니다.

Object Detection

앞에서, Localization을 볼 때, Regression이 잘 동작했습니다. 그래서 Regression을 Detection에서도 활용해보면 어떻겠는가라는 것이 첫 번째 아이디어가 됩니다.
예를 들어 위의 이미지의 경우, 고양이가 2마리, 오리와 개가 각 한마리 씩 있습니다.
이 이미지를 가지고 Detection을 진행하게 되면 (x, y, w, h) 의 16개의 number 가 도출이 되게 됩니다.

만약, 위 그림과 같이 고양이와 개가 한마리씩 있는 이미지라면, 총 8개의 number 가 도출이 되게 됩니다.

마지막으로, 이런 이미지라면 수십개의 number 가 도출되게 될 것입니다.
여기서 확인할 수 있는 것은, 이미지에 따라서 Object 의 개수가 달라지기 때문에, output 의 개수가 달라진 다는 것 입니다.
따라서 Regression을 적용하기에는 적당하지 않습니다.
그럼에도 불구하고, 나중에 보게 될 YOLO(You Only Look Once) 라는 모델은 Regression을 사용해서 Detection을 진행하게 됩니다만, 일반적으로는 적당하지 않다고 생각하면 됩니다.

아무튼, Regression은 Detection에 적합하지 않기 때문에, Classification으로 간주하자는 것 입니다.
위 그림에서, 검정 박스 영역을 보고 고양이인지 개인지를 이 위치에서는 인식을 못합니다.

오른쪽으로 옮기게 되면, 고양이가 맞고 개는 아니다.

또 다시 오른쪽으로 옮기게 되면, 둘 다 아니다.
이런 식으로, 이미지의 각각 다른 부분에 대해서 classifier 를 돌려주는 것 입니다.
이렇게 함으로써 output의 size 가 변하는 것을 해결하겠다라는 접근 방법이 되겠습니다.
Classification 기반 접근의 문제점 (1)

이렇게 classification 기반으로 detection 을 접근하게 됐을 때, 한가지 문제는 가급적 다양한 사이즈의 많은 윈도우들을 활용해서 너무나도 많은 위치에서 테스트를 해야 한다는 것 입니다.
해법은 그럼에도 불구하고, 그냥 실행하라는 것입니다. 즉, convolution net 과 같은 무거운 classifier 만 아니라면, 다양한 크기의 윈도우를 다양한 크기의 전역에 일단 실행하라는 솔루션이 되겠습니다.
실제로 이 방법이 안통하는 것이 아닙니다. 실제로도 잘 통했습니다.
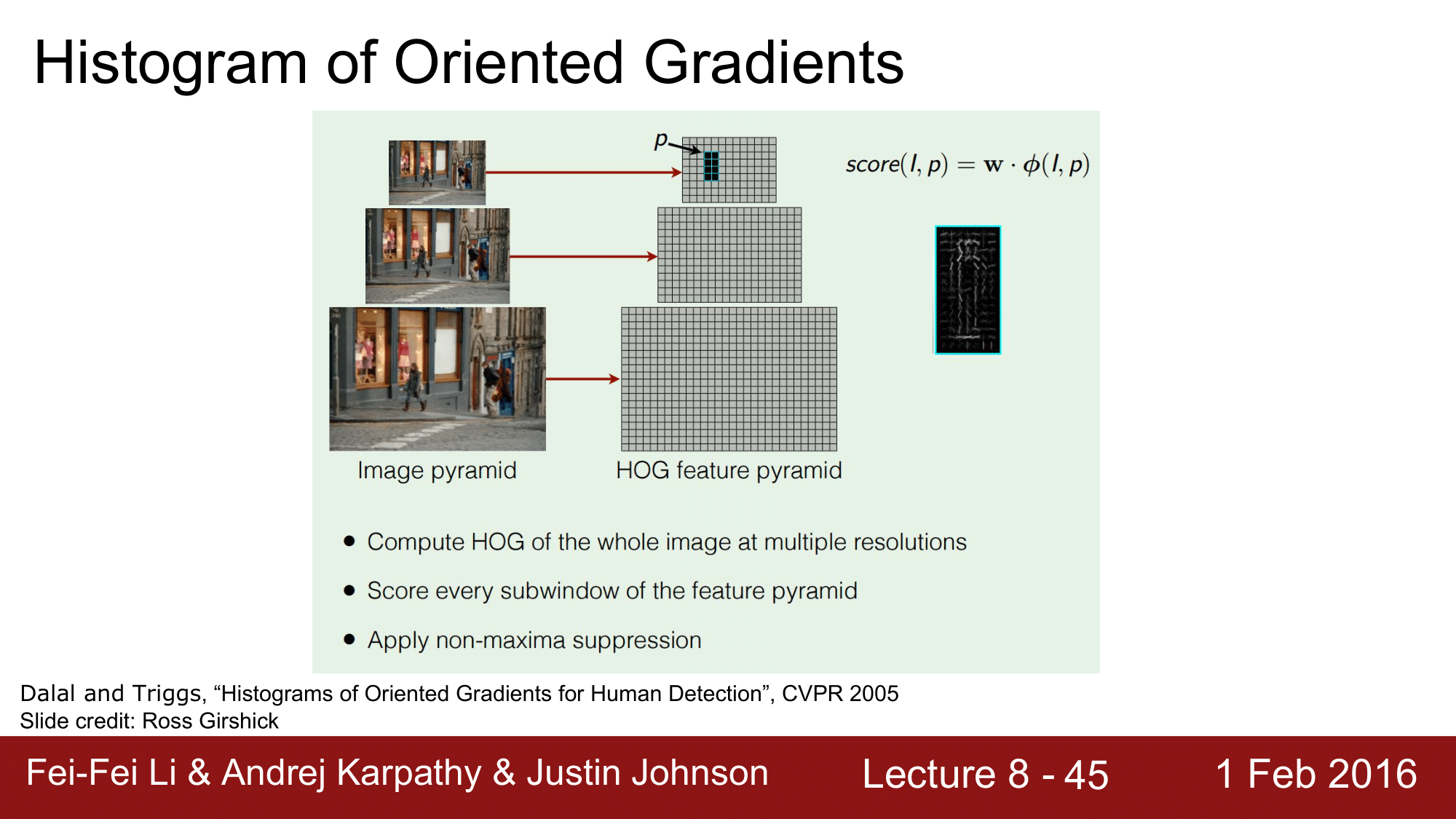
2005년도에 있었던 HOG(Histogram of Oriented Gradients) 라는 방법을 보게되면, 이처럼 다양한 resolution 을 가지는 이미지들에 대해서, linear classifer 를 돌립니다. linear classifier 는 굉장히 빠르게 동작하기 때문에, 이를 이용해서 다양한 해상도의 여러 영역을 돌려보는 방법이었습니다.
위의 예시는 길거리에 걸어가는 행인들을 detection 하는 것 이었는데, 잘 동작했었다고 합니다.
HOG가 잘 동작한다고 알려지면서, 많은 후속 연구가 진행이 되었는데 그 중 하나가 DPM 입니다.

2010년경에 나왔던 DPM(Deformable Parts Model)은 HOG를 기반으로 사용했습니다.
DPM 의 특징은 객체의 부분부분(머리, 몸통, 다리, …)에 대한 템플릿들을 가지고 있습니다. 그리고 그 템플릿들은 각각이 변형된 형태까지 갖고 있습니다. 이렇게 하다보니 당시 수준에서는 굉장히 잘 동작했다고 합니다.

이것은 2015년에 나왔던 논문인데, 사실 알고보니 DPM 이라는 게 CNN의 한가지 종류더라 라는 것입니다.
edge 계산은 convolution 을 이용해서 진행하고, histogram은 pooling 을 이용해서 하는 거다 라는 내용의 논문이 있기도 했습니다.
Classification 기반 접근의 문제점 (2)

Classification 을 기반으로 Detection 을 진행할 때 두 번째 문제점은, CNN 과 같은 무거운 network 을 써야하는 경우입니다.
모든 영역이나 모든 스케일들을 보기에는 convolutional neural network 는 너무 무거운 연산이기 때문입니다.
그래서 이런 경우의 솔루션은 전 지역을 보게 하지말고, 의심되는 지역을 보게하자는 것 입니다.
의심되는 지역을 추천하자는 방식이여서 Region proposal 방식이라고 합니다.
Region Proposals

Region proposal 은 어떤 Object 를 포함하고 있을 것만 같은 뭉쳐있는 이미지의 영역을 찾아 내는 것 입니다.
여기서 blobby image region 이라는 것은 유사한 색상이나 유사한 텍스쳐를 가지고 있는 지역이 될 것이고, Class-agnostic 한 detector 가 되고, blob 한 region 만 찾는 것이 목적이 되게 됩니다.
때문에, class에 신경쓰지 않고 개든 고양이든 꽃이든 신경쓰지 않고 눈동자와 코까지도 포착하는 것을 볼 수 있습니다.
이처럼 Class-angnostic하기 때문에 정확도가 높진 않지만 그만큼 매우 빠르게 실행이 되게 됩니다.
결과적으로 왼쪽의 이미지를 넣게되면 오른쪽의 그림과 같이 여러개의 box 들을 얻게 되는 것 입니다.
Region Proposals: Selective Search

Region proposal 방법에는 여러가지가 있는데, 그 중 대표인 것으로 Selective Search라는 것이 있습니다.
이 방법은 픽셀에서 부터 시작하여, 색상이나 텍스쳐가 유사한 것들 끼리 묶어주고 어떤 알고리즘을 사용해서 큰 blob의 형태로 만듭니다. 작은 blob 들을 merge 해서 큰 blob 을 만들고, 다시 한번 merge 해서 최종적으로 box 들이 나오게 됩니다.
이미지 전체를 convolution net 으로 모두 검사하는 것이 아니라, box 가 쳐진 부분들만 검사를 하면 된다는 것 입니다.
Region Proposals: Many other choices
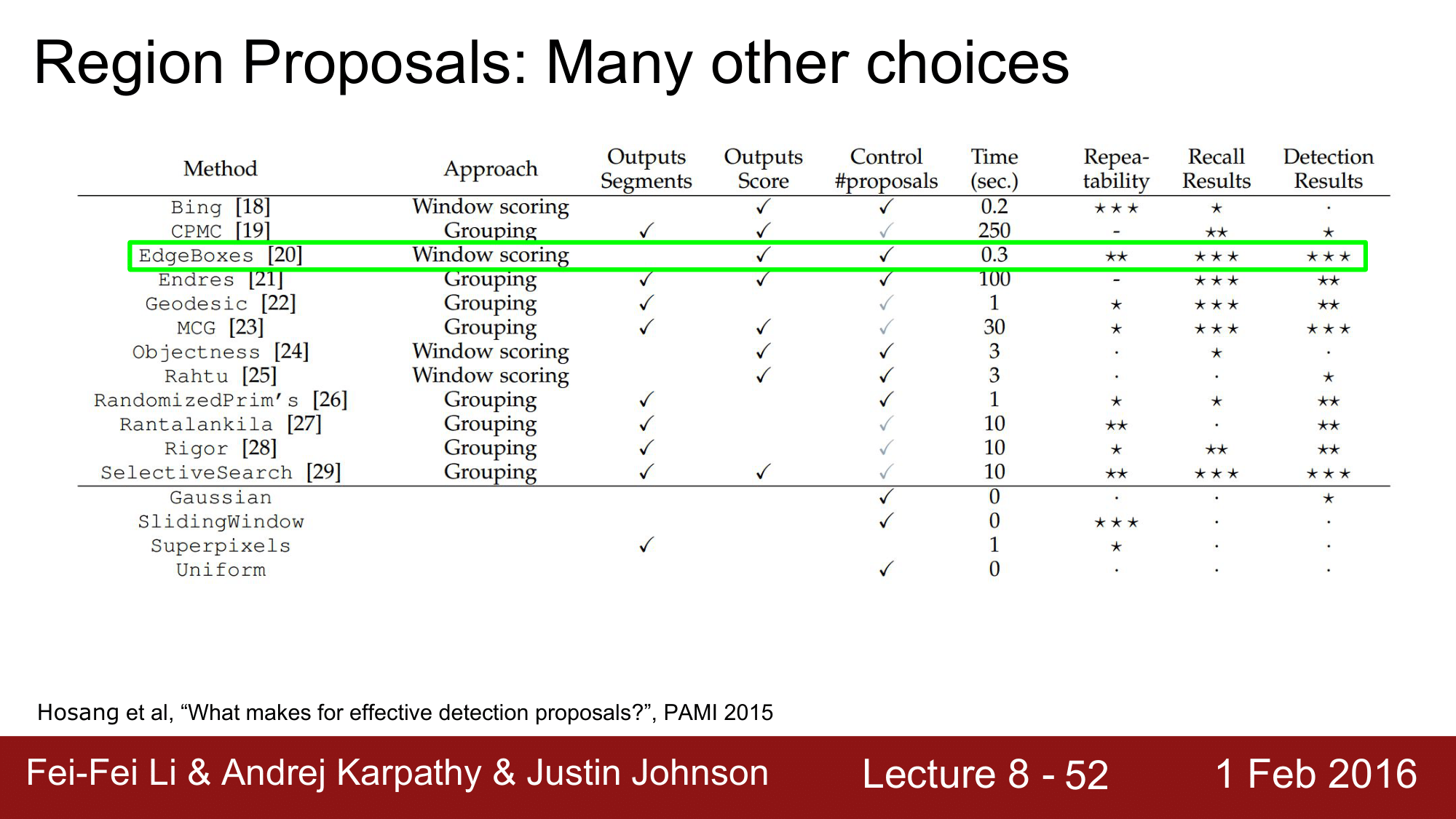
Selective Search 외에도 수 많은 Region proposal 관련한 method 들이 있는데, Justin Johnson 에 의하면 EdgeBoxes 를 사용하는 것도 권장한다고 합니다.
R-CNN
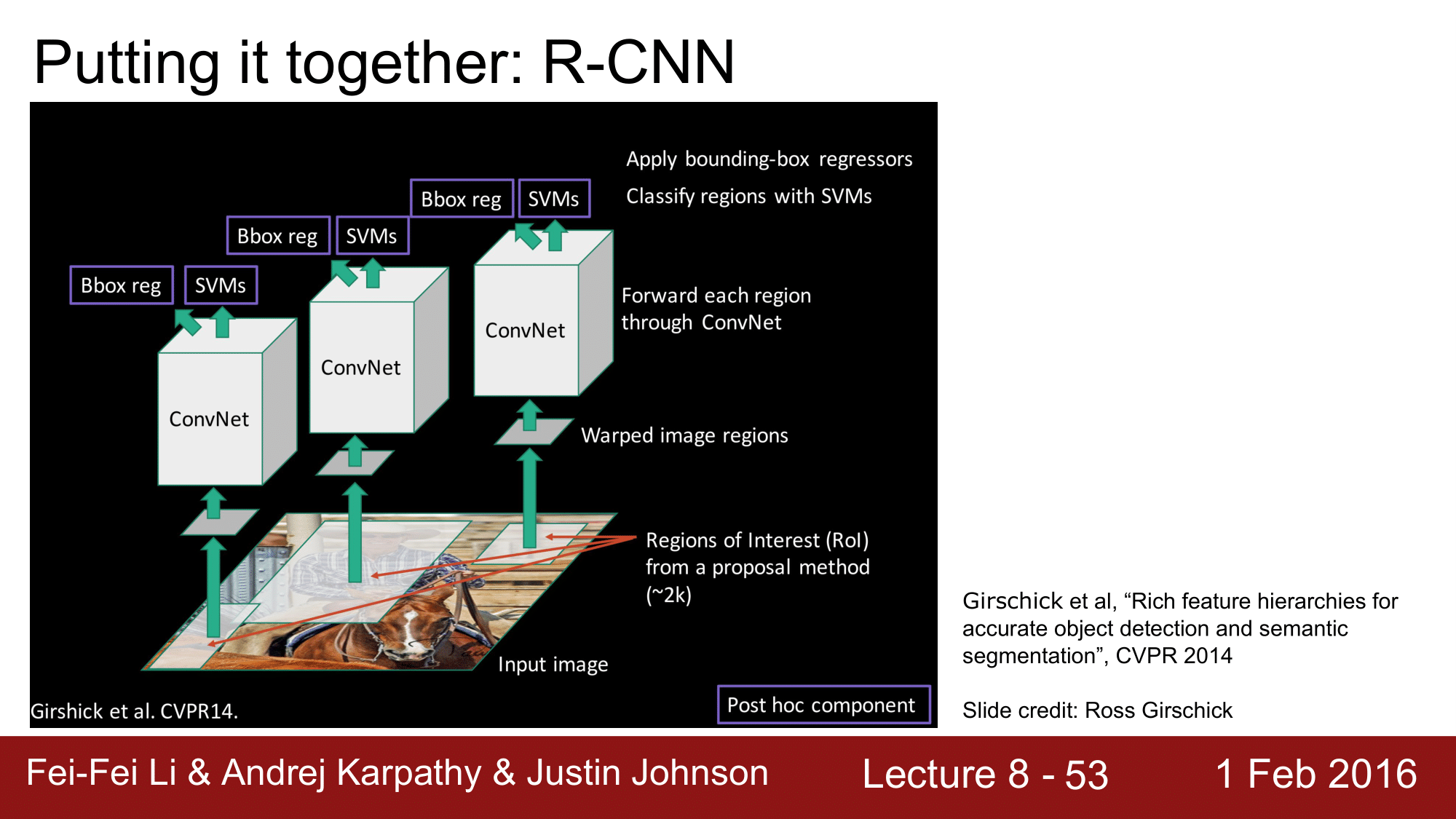
지금까지 봤던 Region proposal과 CNN을 결합하여 사용한 것이 바로 R-CNN(Region based CNN)이 되겠습니다.
R-CNN 은 동작을 잘 하는데, pipeline 이 다소 복잡해 보이긴 합니다. 하나하나 살펴보면 다음과 같스비낟.
먼저, input 이미지를 받아서 proposal method 를 이용해서 우리가 관심이 있는 지역들(RoI; Regions of interest)를 뽑아냅니다. 약 2천개 정도를 뽑아 내는데, 이미지에 수십~수만개의 bounding box 가 있을 수 있는 것들 중에서 region proposal 을 통해서 2천개 정도로 줄이는 것입니다.
2천개도 물론 작은 수는 아니지만, 이미지에서 추출할 수 있는 전체 box 의 수를 생각하면 비교적 작은 숫자입니다.
이렇게 뽑아낸 box 들은 각자가 다른 위치와 크기를 갖게 됩니다. 이 RoI들을 crop 하고 warp 시킵니다. CNN에 들어가는 일반적인 정사각형의 크기로 warp 시켜준 다음, 각각의 RoI 들을 CNN으로 돌려주는 것입니다.
여기에는 물론 두 가지 head 가 존재합니다. classification head, regression head 가 있습니다.
classification head 에서는 SVM을 이용해서 Classify 를 하게 되고, regression head 에서는 bounding box 를 추출하게 되는 것입니다.
이 pipeline 을 좀 더 상세하게 살펴보겠습니다.
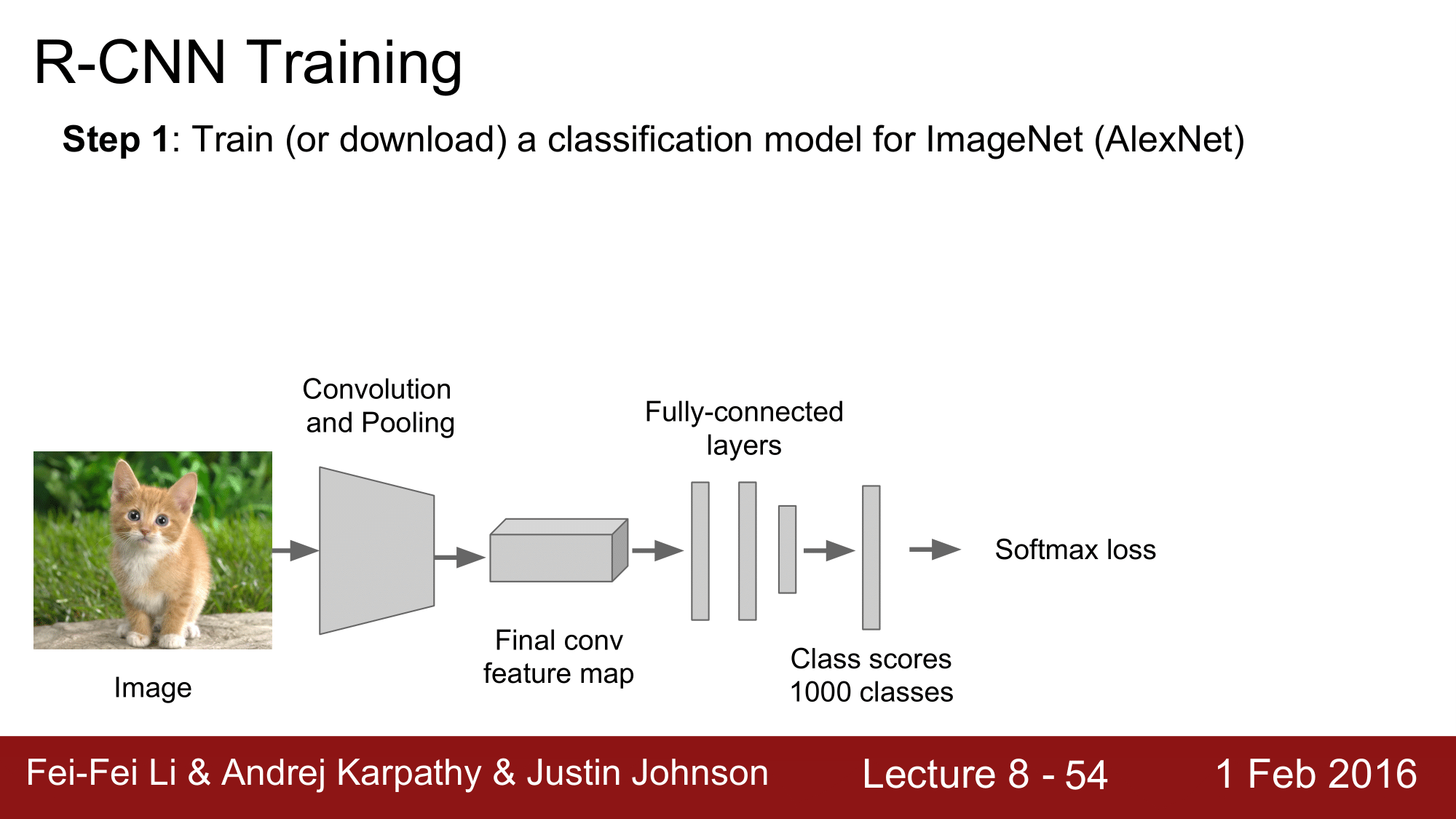
1 단계에서는 처음부터 트레이닝 시키는 것 보다는, ImageNet 과 같은 곳에서 이미 학습이 된 check-point 들을 가지고 오는 식으로 진행하는 것이 좋습니다. 그래서 여기에서는 ImageNet 에서 가져왔기 때문에 1000개의 class 를 갖는 모델이 되겠습니다.
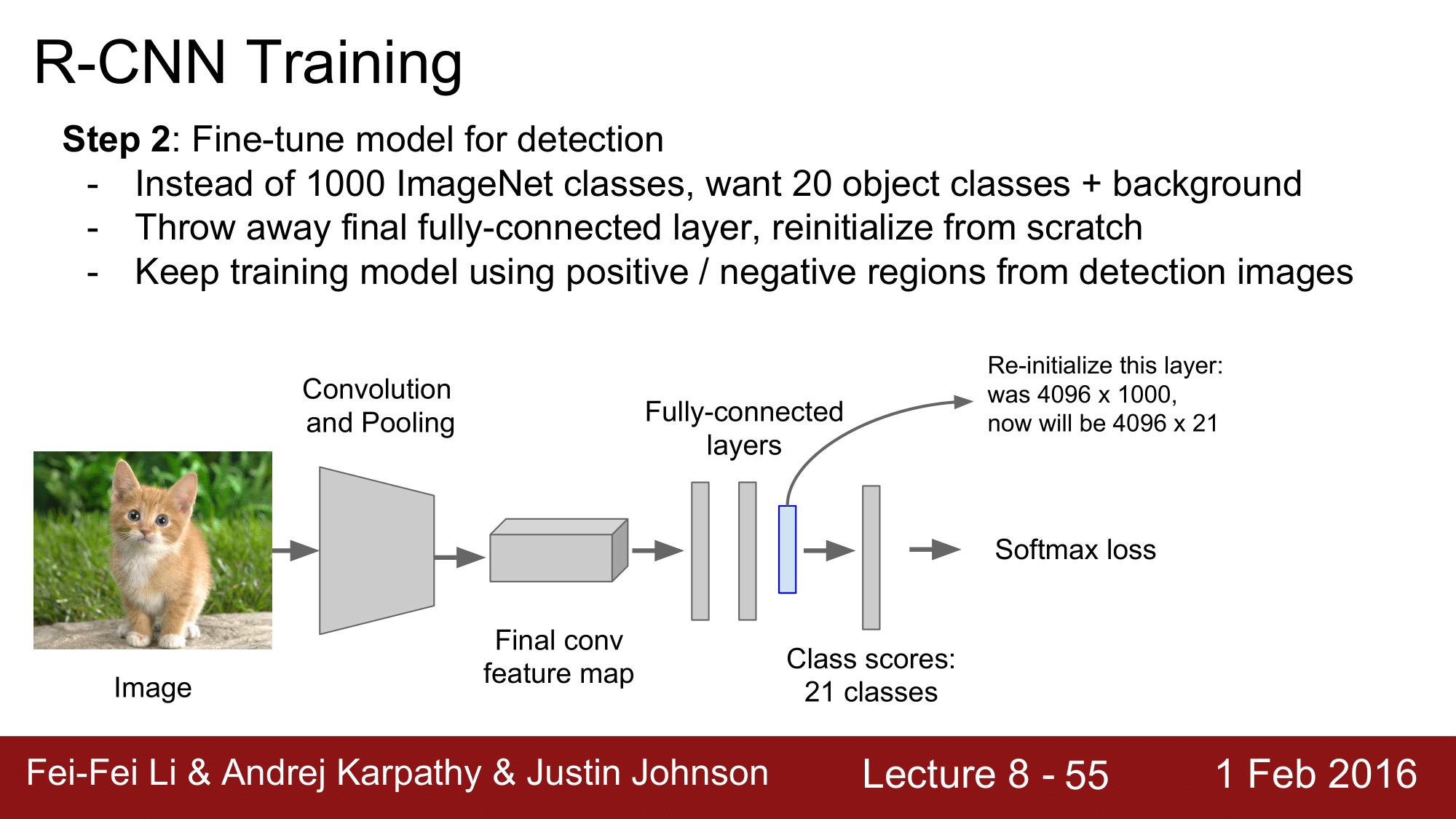
하지만 우리가 찾아야 되는 class 는 20개의 object class 와 background 로 구성된 총 21개의 class 를 원하기 떄문에, 4096 x 1000으로 된 파란색의 layer 를 4096 x 21의 shape 을 가지도록 변형을 해줘야 합니다.
FC Layer 를 제거하고, 변형된 layer로 대체해 주는 것입니다.
그리고 이미지 전체에서 진행하는 것이 아니라, postive / negative region 을 이용해서 trainin model 을 유지해나가는 것 입니다.

다음 단계에서는 feature 을 추출하는데, 우선적으로 region proposal 들을 추출해내고, 각각의 region 에 대해서 CNN 의 input 으로 들어갈 size 에 맞게 crop 과 warp 을 진행합니다. 이후 해당 이미지들을 CNN 을 돌리게 되고 pool5 의 feature(AlexNet 에서의 5번째 pooling layer의 feature)를 disk에 저장합니다. 물론, 이때 disk 의 사이즈가 꽤 커야 합니다.

4단계에서는 class 당 하나의 binary SVM을 이용하여 region feature 들을 classify 합니다.
binary SVM 이기 때문에, 고양이 클래스라면 고양이인지 아닌지, 각 클래스에 대해 맞는지 아닌지를 모든 클래스에 대해서 반복하게 됩니다.

마지막 단계에서는 bbox(bounding box) regression 을 합니다.
bbox regression 은 region proposal 이 항상 정확한 것이 아니기 때문에, cache 해놓은 regression 의 feature 을 이용하여 region proposal 의 정확도를 높혀주는 작업입니다.
뒤에서 보겠지만, 일반적으로 bbox regression 을 하게 되면 mAP(mean Average Precision) 라고 하는 것이 약 3~4% 올라가는 효과를 볼 수 있습니다.
첫 번째, 고양이 이미지를 보게 되면 bbox 가 굉장히 잘 나온 것을 확인할 수 있습니다. proposal 이 잘 된 경우인데, 두 번째 이미지를 보게 되면 왼쪽이 비어 있습니다. 즉, bbox 가 너무 왼쪽으로 나와있는 것입니다. 이 때문에, x 에 -0.25 라는 값을 줌으로써, 이 것을 보정하는 것 입니다. 마지막으로 3번째 이미지를 보게되면, height 는 괜찮은데 width 가 좌우로 너무 넓습니다. 그래서 width 를 줄이기 위해 -0.125 를 주어 고양이에 fit 하게 보정합니다.
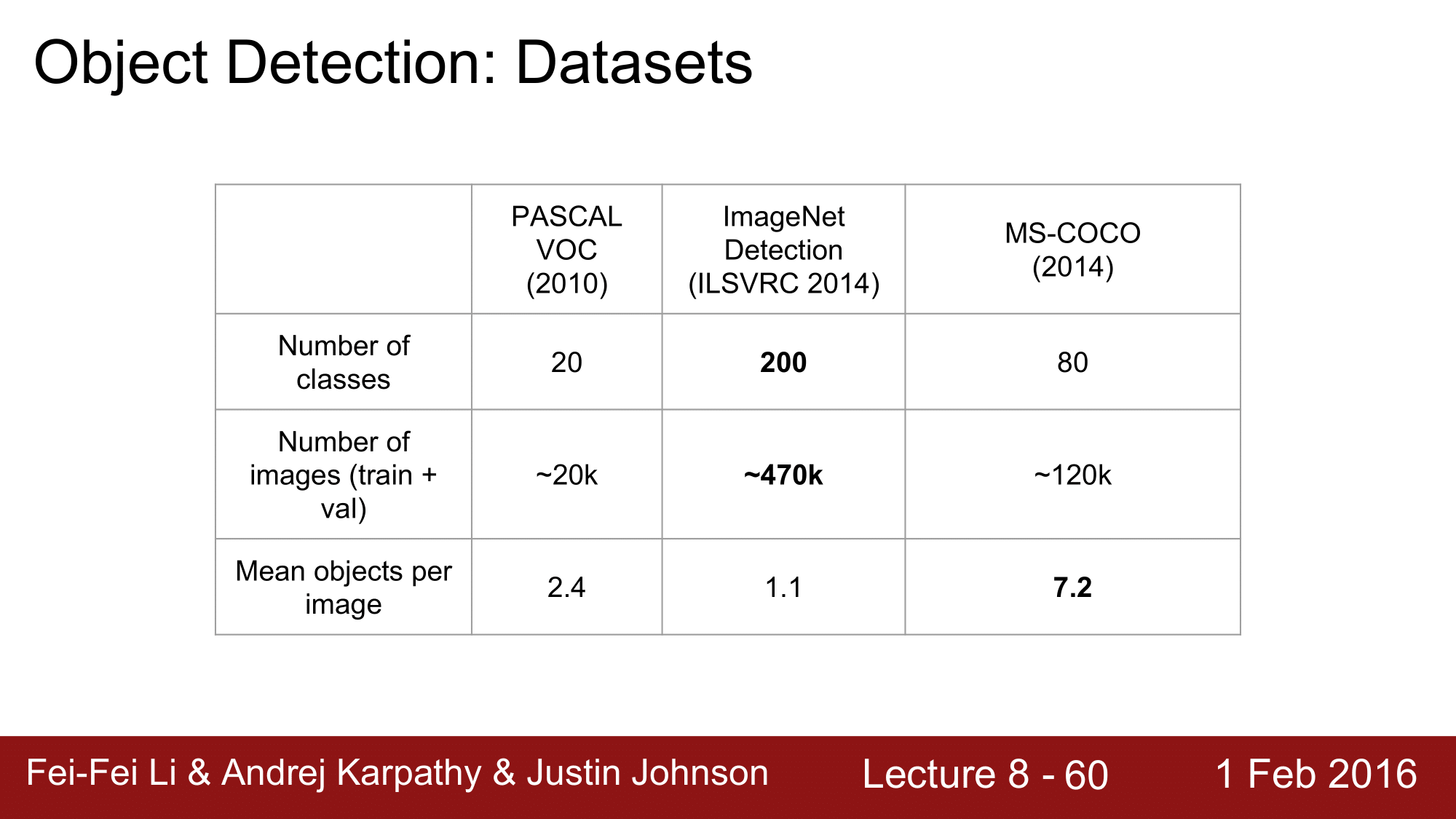
위의 표는 detection 관련 dataset 에 관한 것으로, PASCAL VOC, ImageNet Detection, MS-COCO 가 있습니다.
MS-COCO 의 경우 다른 dataset 들과는 다르게 이미지당 object 수가 더 많기 때문에, 오히려 MS-COCO 가 더 활용되는 경우도 있습니다.
참고로 2016년에 Google 에 Open Images Dataset이 나오기도 했습니다.
Object Detection: Evaluation

Detection 을 평가하는 방법으로 mAP 라는 값이 쓰입니다.
기본적으로 각각의 Class 에 대해서 average precision(AP) 을 따로 따로 구한다음에, 이를 평균내어 구합니다.
detection 이 positive 한 경우에는 IoU(Intersaction of Union) 값이 0.5 를 넘을 경우, 일반적으로 맞췄다고 판정합니다.
모든 테스트 이미지들에 대한 detection 에서 precision 을 recall 로 나눠주어 curve 를 구하고, 이 경우에 AP 는 curve 아래의 넓이로 표현이 됩니다.
물론, mAP 의 값은 0 에서 100 사이의 숫자로 이루어 집니다.
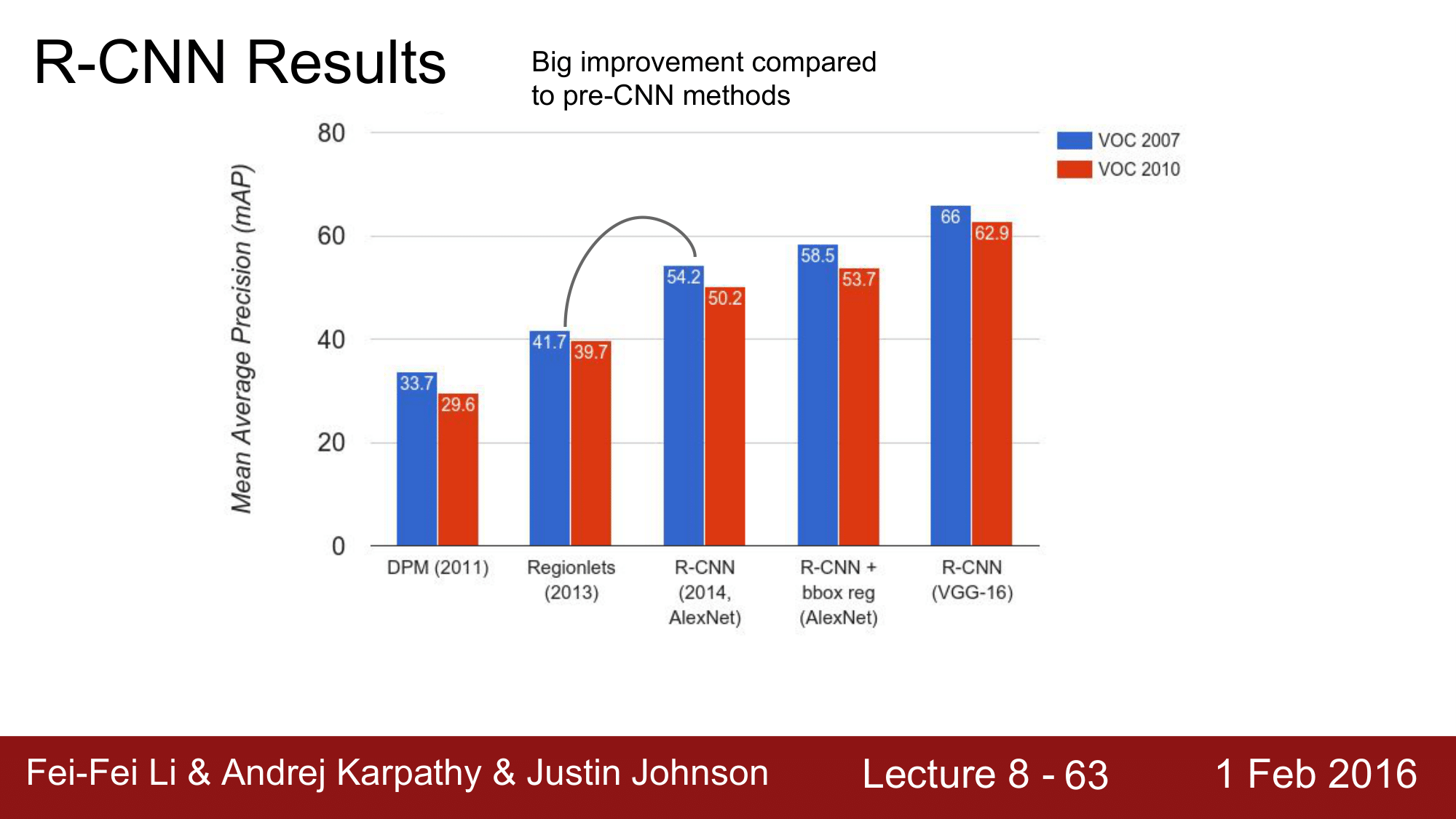
mAP 의 변화는 위 그림처럼 변화해왔습니다.
DPM, Regionlets 까지 가 Pre Deep Learning 의 시대이고, 이 이후가 CNN 이후 시대; Post Deep Learning 의 시대라고 합니다.
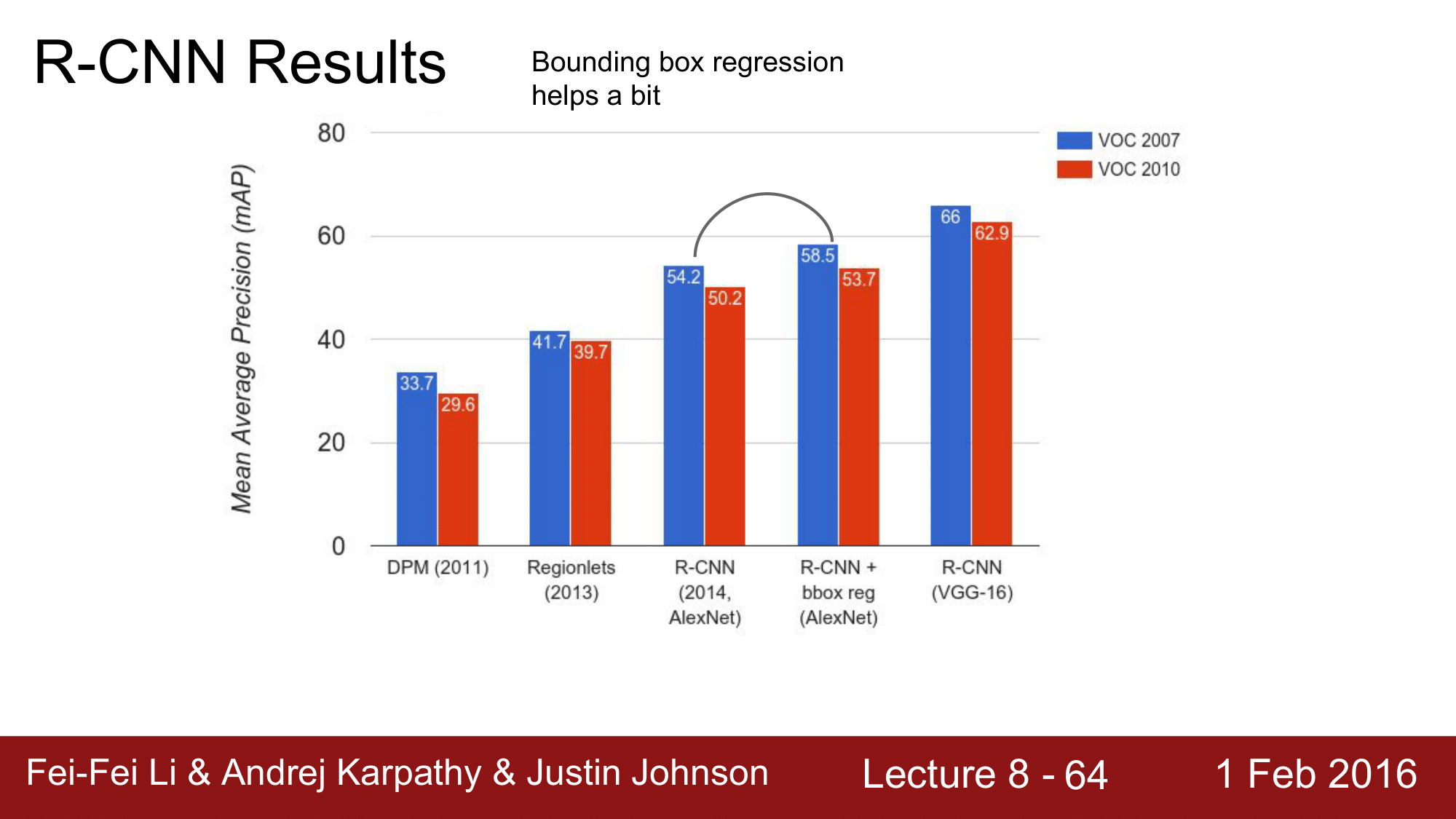
R-CNN 에 bbox reg 를 함으로써 앞에서 3~4% 의 향상이 있다고 했었는데, 실제로도 그렇다는 것을 확인할 수 있습니다.
또한 AlexNet에서 VGG-16으로 변경하는 것만으로도 많은 향상이 이루어짐을 확인할 수 있습니다.
R-CNN 의 문제

지금까지 Region based CNN 을 살펴보았는데, 몇가지의 약점들을 가지고 있습니다.
일단은 test time 시에 느리다는 것으로, 2000개 각각의 region proposal 에 대해서 forward-pass 로 CNN 을 돌려야 하기 떄문에 무겁고 느릴 수 밖에 없다는 것입니다.
다음으로 SVM 과 regressor 가 후행적이라 오프라인으로 training 된다는 것입니다. 즉, SVM 과 regressor 의 반응에 기반하여 CNN feature 가 즉각적으로 update 되지 않는다는 것입니다.
마지막으로, 다단계의 training pipeline 으로 다소 복잡하는 것입니다.

그래서 이런 약점들을 문제에 두고, 2015년에 등장한 모델이 Fast R-CNN 입니다.
이 모델의 아이디어는 CNN을 돌리는 것과 region 을 추출하는 순서를 바꾼 것 입니다.
우리가 지금까지 살펴봤던 R-CNN 에서는 Region Porposals 를 추출한 다음에 CNN 을 수행했지만, Fast R-CNN 에서는 CNN 이후 Region 을 추출한다는 것 입니다.
이는 Overfeat에서의 Sliding Window와 유사한 아이디어로, 이미지가 들어오면 R-CNN에서는 먼저 Region Proposal 을 수행했습니다. 하지만 Fast R-CNN에서는 이미지를 우선 CNN 에 돌립니다. 이렇게 함으로써 고해상도의 conv5 feature map 을 생성하게 되고, 이에 대해 region proposal method 를 활용하여 RoI 를 추출해냅니다. 추출한 RoI들을 조금 후에 설명할 RoI Pooling 을 활용하여 FC. Layer 로 넘겨주고, FC에서는 Classification head 와 Regression head 로 전달하여 R-CNN 에서와 같이 classification 과 bbox 처리를 하게됩니다.
R-CNN의 첫 번째 문제점은 각각의 Region 들이 CNN의 forward pass 를 거쳐야 하기 때문에 test-time 때에 느리다는 것이었습니다.
그런데, Fast R-CNN에서는 Region Proposals를 수행하기 전에 Convolution 을 수행함으로써 연산을 공유하게 됩니다. 이 때문에 test-time 에 빠르게 동작할 수 있다는 것입니다.
여기까지가 test-time 때의 경우입니다.
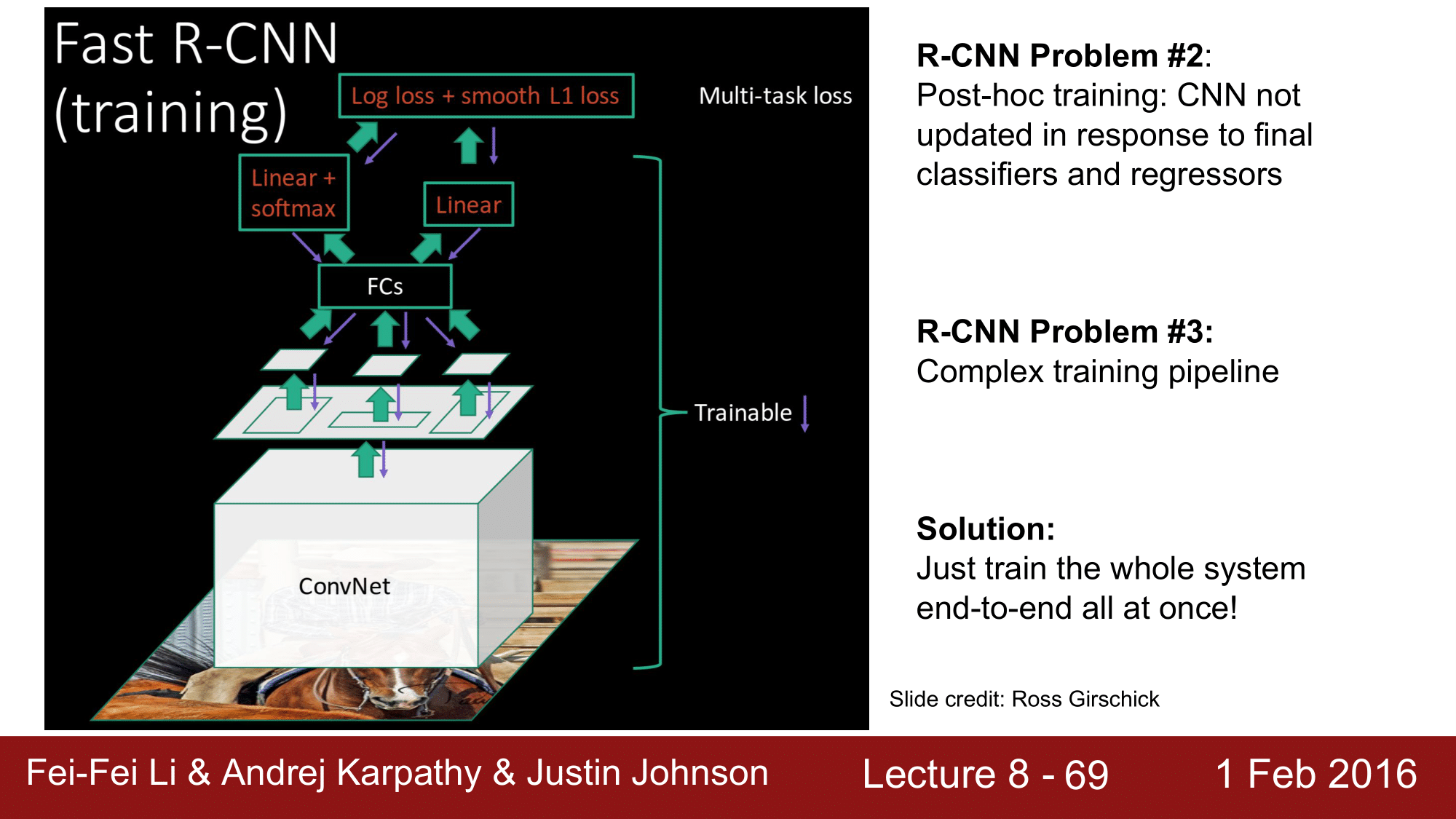
다음으로 training-time 때 입니다.
R-CNN의 두 번째 약점은 SVM과 Regressor가 오프라인으로 trainning 되기 떄문에 CNN이 이에 즉각적으로 update 될 수 없다는 것이었고, 세 번째는 training 의 pipeline이 복잡하다라는 것이었습니다.
이것을 Fast R-CNN에서는 전체 시스템을 end-to-end 로 학습을 시킬 수 있기 때문에 매우 효율적이어서 위의 2가지 약점들을 한번에 해소할 수 있게 됩니다.

앞에서 RoI Pooling이라는 것을 잠깐 언급했었는데, 이에 대해서 상세하게 살펴보도록 하겠습니다.
여기 고해상도의 input 이미지가 selective search 나 edge box 같은 것으로 region proposal 이 되어 있습니다. 이 이미지를 Convolution 과 Pooling 을 거쳐서 High Resolution Convolution Feature Map 을 생성하게 됩니다.
그런데 CNN에서 FC. Layer 는 Hi-res feature 를 원하는 것이 아니라, low-res conv feature 를 원한다는 것입니다. 그래서 이들간의 상충이 일어나게 되는데, 이를 RoI Pooling이 해결하는 것 입니다.
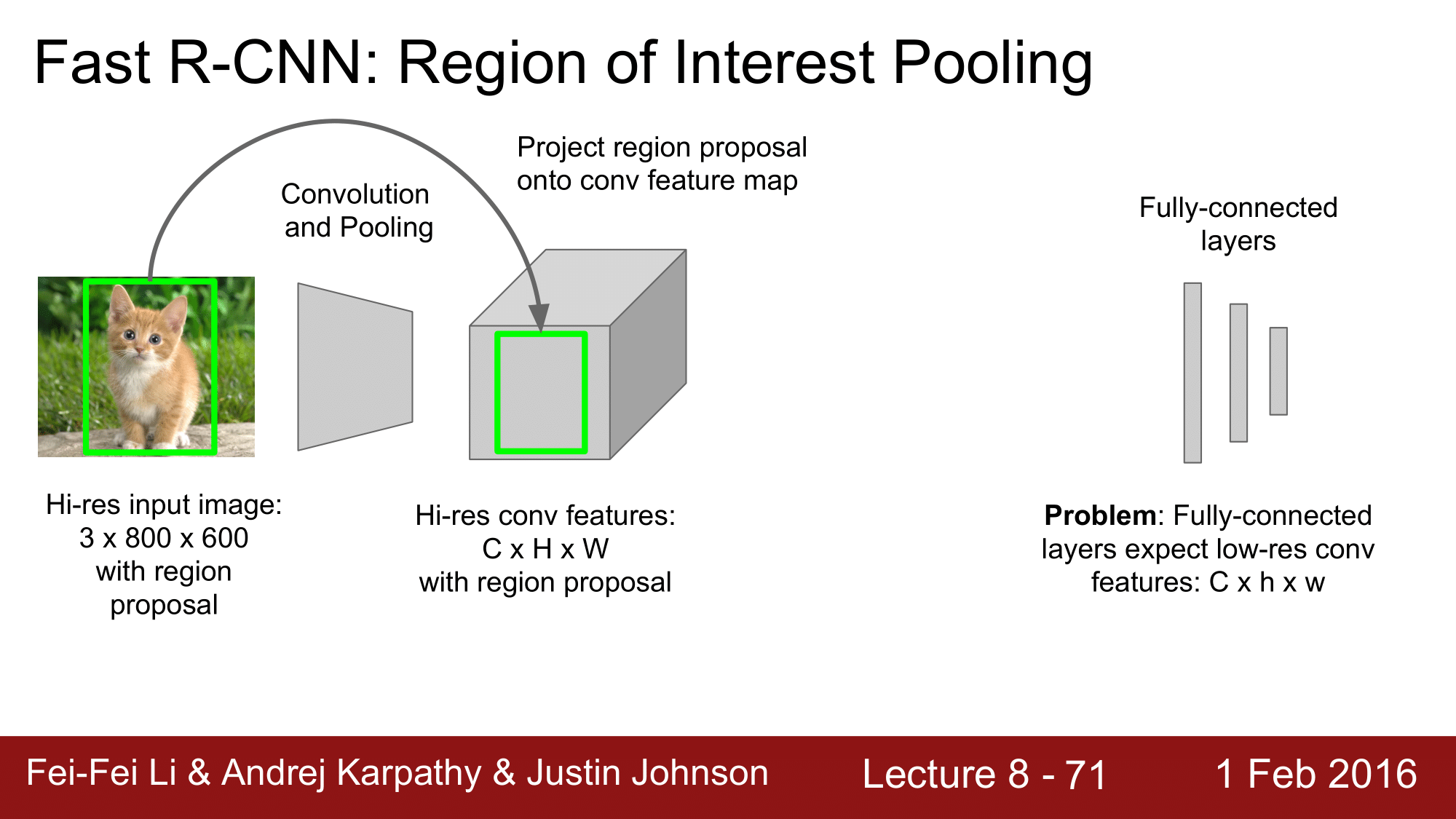
RoI Pooling 은 원본 이미지에 있는 region proposal 을 convolution feature map 으로 projection 합니다.
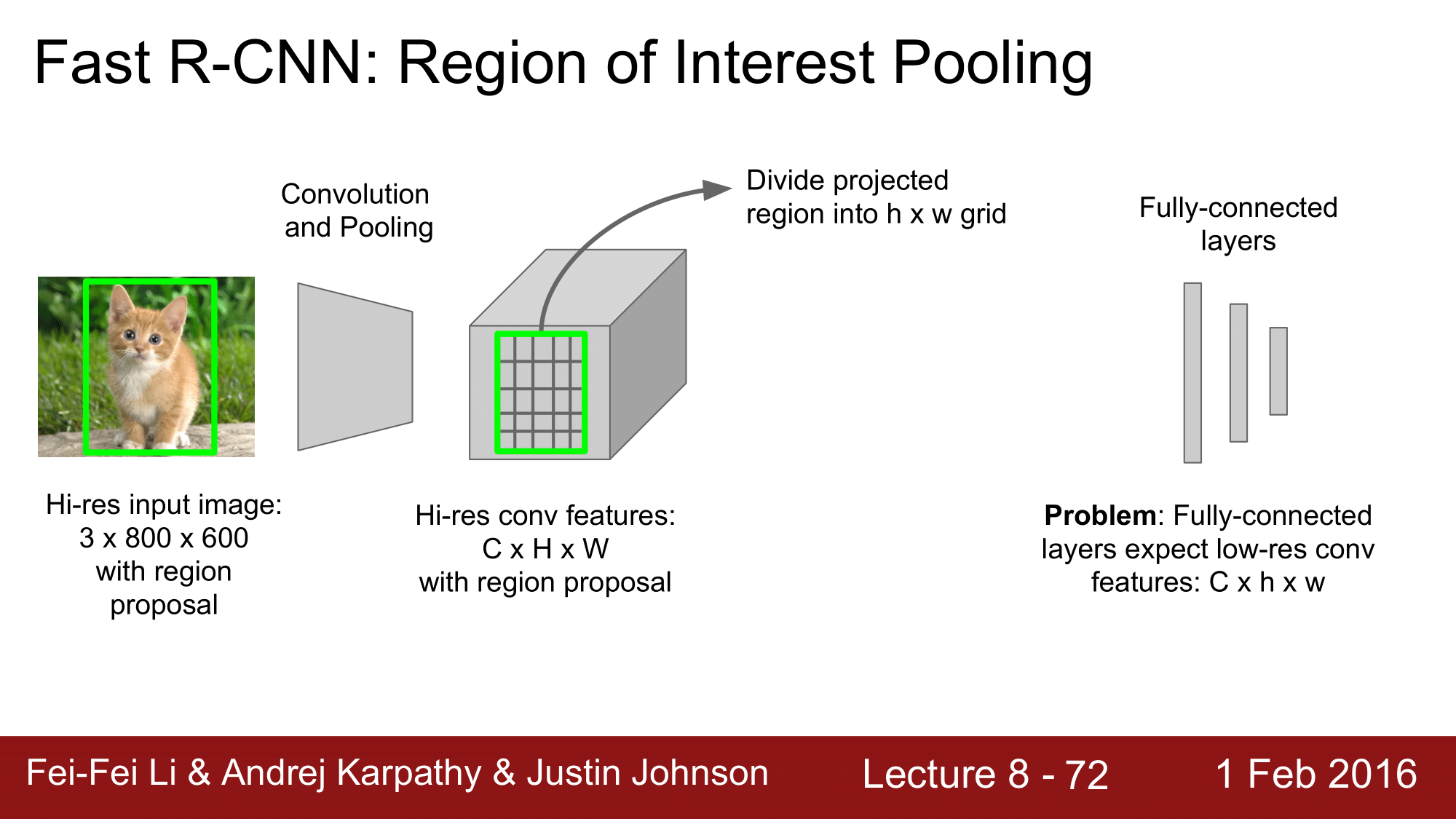
그리고 해당 영역을 h x w 의 grid 로 나눠주게 됩니다.
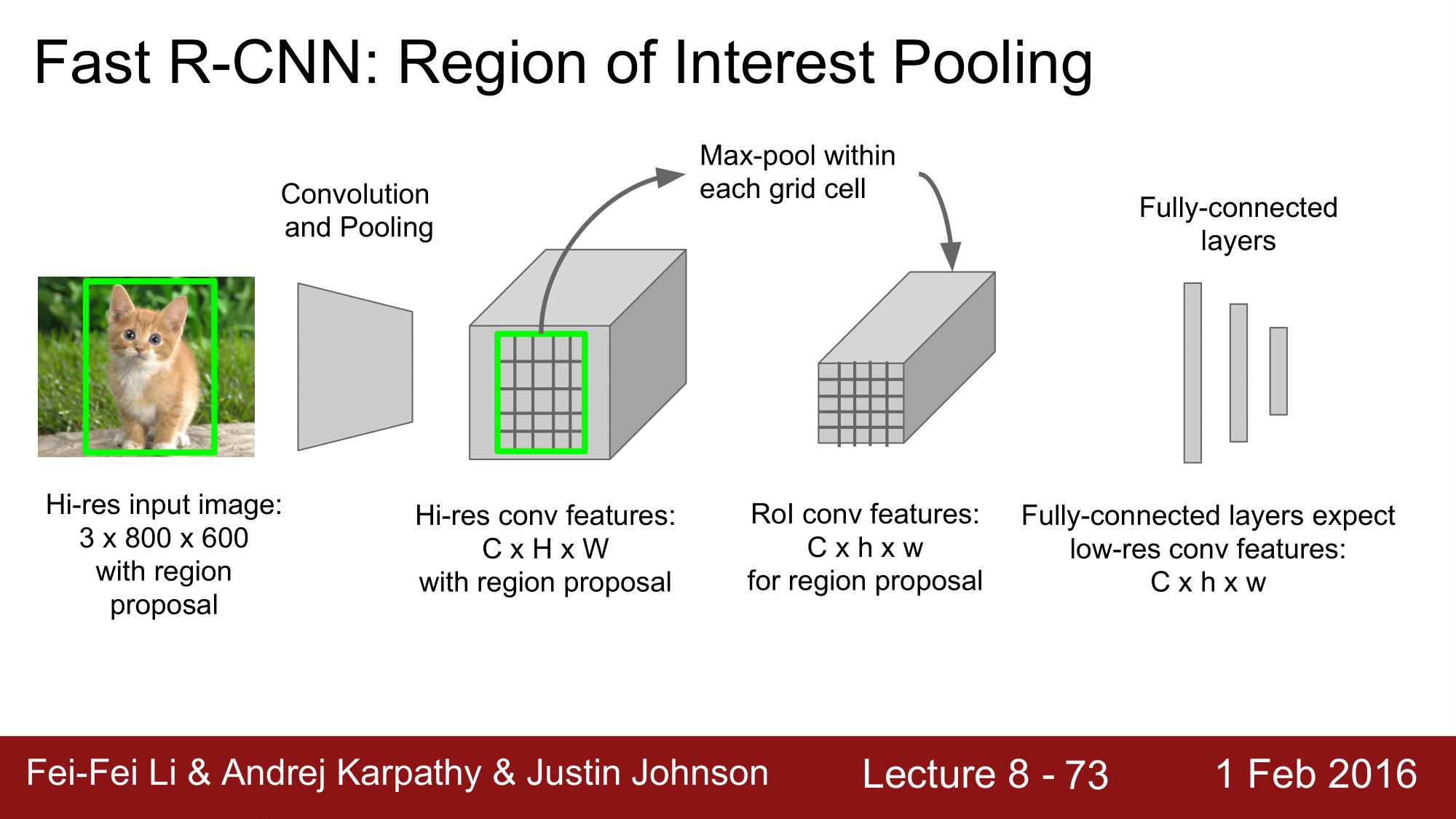
그 다음 이를 Max Pooling 하게 됩니다. 각각의 grid cell 내에서 max-pooling 함으로써, 결과적으로 Hi-res conv feature 가 아니라 RoI conv feature 를 추출해내게 됩니다. 디시말해 R-CNN과는 다르게 covolution 과 crop & warp 의 순서를 바꿔버린 것이라고 할 수 있습니다.
즉, Convolution 을 먼저 진행하고 그 다음에 warp 과 crop 이 일어난다고 생각할 수 있습니다.

이렇게 max pooling 했을 때의 장점은 CNN에서 처럼 back propagation 때에 문제가 없기 때문에 end2end로 진행하는데 있어 원활한 진행이 가능하다라는 장점을 갖게 됩니다.
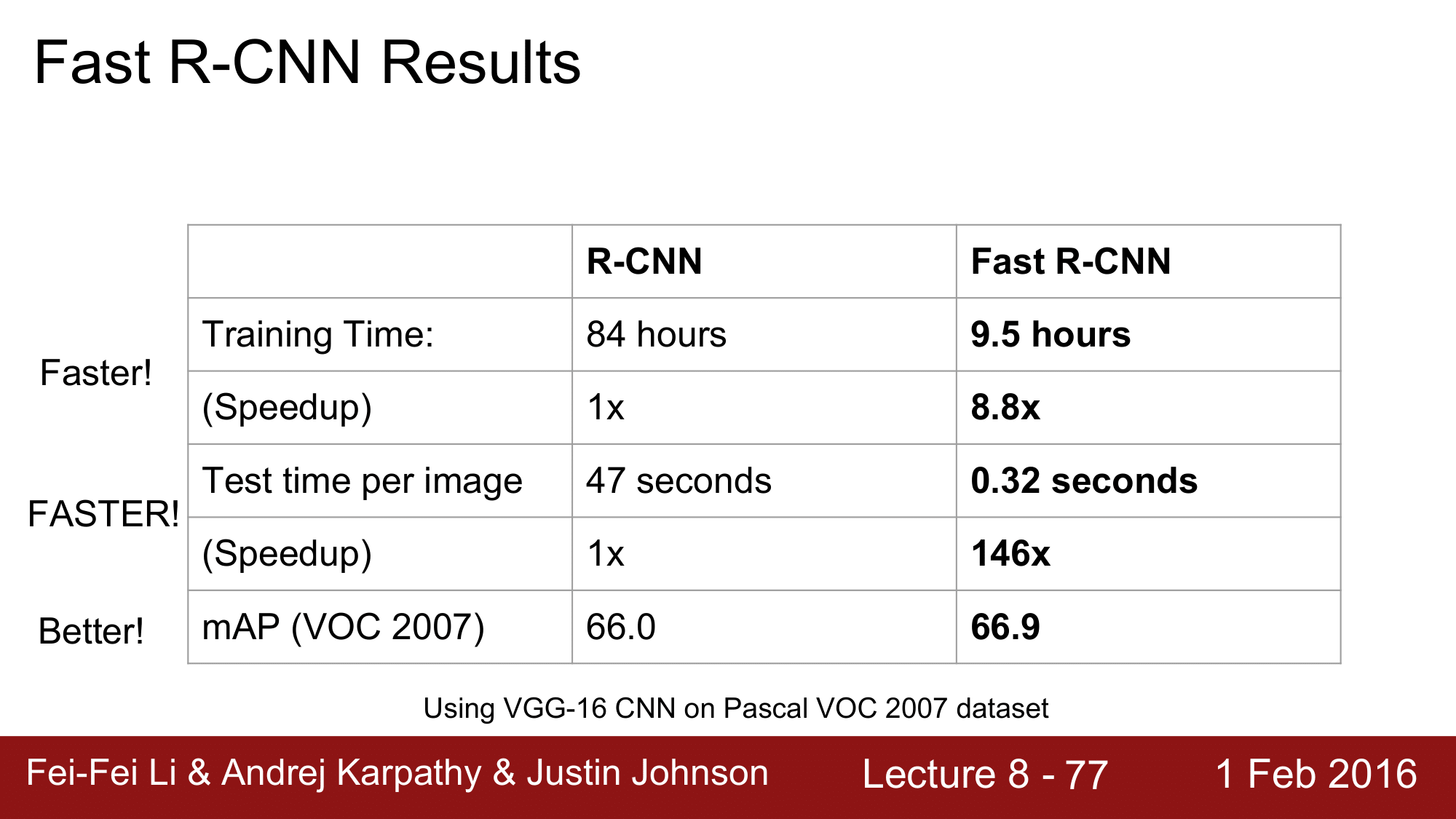
Fast R-CNN의 성능을 보게 되면, trainning-time 은 8.8배, test-time 에는 146배로 빨라진 것을 확인할 수 있습니다.
이렇게 빨라지는 이유를 다시 한번 짚고 넘어가자면, R-CNN의 경우 각각의 Region Proposal 에 대해 별개로 forward pass 을 돌리기 때문에 매우 느린 것이고, Fast R-CNN의 경우 Region Proposal 간의 Convolutino layer 의 compuatation 을 share 하기 때문에 빠른 것이다 라고 정리할 수 있겠습니다.
정확도 역시 Fast R-CNN이 더 나은 것을 볼 수 있습니다.
Fast R-CNN 의 문제점

그런데 Fast R-CNN에도 문제점이 있습니다.
Fast R-CNN 의 이미지당 test-time 경과시간은 region proposal 과정을 포함하고 있지 않은 것이고 selective search 같은 region proposal 을 포함하게 되면 무려 2초나 걸린다는 것입니다. 이렇게 되면 real-time 으로 사용이 어려워지는 결과가 나타납니다.

이에 대한 해결책은 다음과 같습니다.
앞에서 CNN 을 이용해서 Regression, Classification을 했으니 Region Proposal 에도 적용해보면 어떻겠는가 라는 아이디어에서 시작한 것으로, 이를 적용한 것이 다음에 설명할 모델이 됩니다.
Faster R-CNN

지금까지는 Region Proposal 을 외부에서 진행했었는데, 이제는 더 이상 그럴 필요가 없습니다.
위 그림에서 보시다시피 Region Proposal Network 이라는 것을 새로 만듭니다. RPN 이라고 하는데, 이 RPN을 제일 마지막에 있는 Convolution Layer 에 삽입하게 됩니다. 물론 RPN 도 CNN이 될 것입니다.
RPN 이후의 과정들, 즉 RoI Pooling, Classification, Regression은 앞에서 본 바와 같은 Fast R-CNN의 과정과 동일하게 진행하게 됩니다.
Faster R-CNN: RPN(Region Proposal Network)
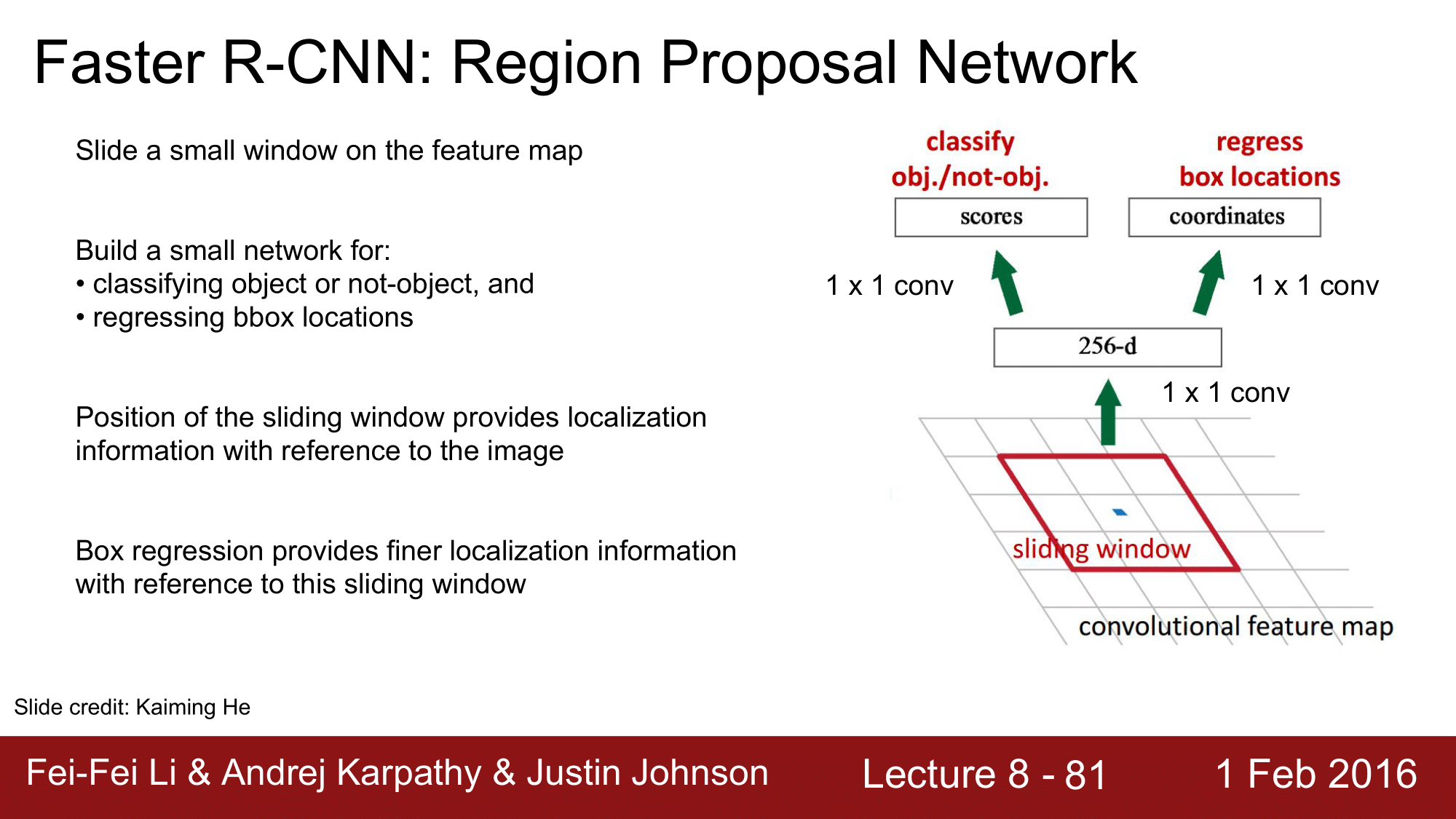
RPN 에 대해서 조금 더 살펴보면, 기본적으로 CNN이고 때문에, 전 단계의 CNN을 거쳐서 나온 feature map 상에서 3 x 3 의 sliding window 를 가지고 slide 를 해주어 region proposal map 을 생성하게 됩니다.
이 RPN은 하나의 작은 CNN 이다 라고 생각하면 됩니다. 그래서 이것이 Object 인지 아닌지를 classify 해주고 object의 location을 bbox로 regression 을 통해 구해준다는 것입니다.
sliding window 의 위치는 이미지에 대한 localization 정보를 제공하고, Box regression 은 sliding window 에 대해서 보정해주는 역할을 하게 됩니다.
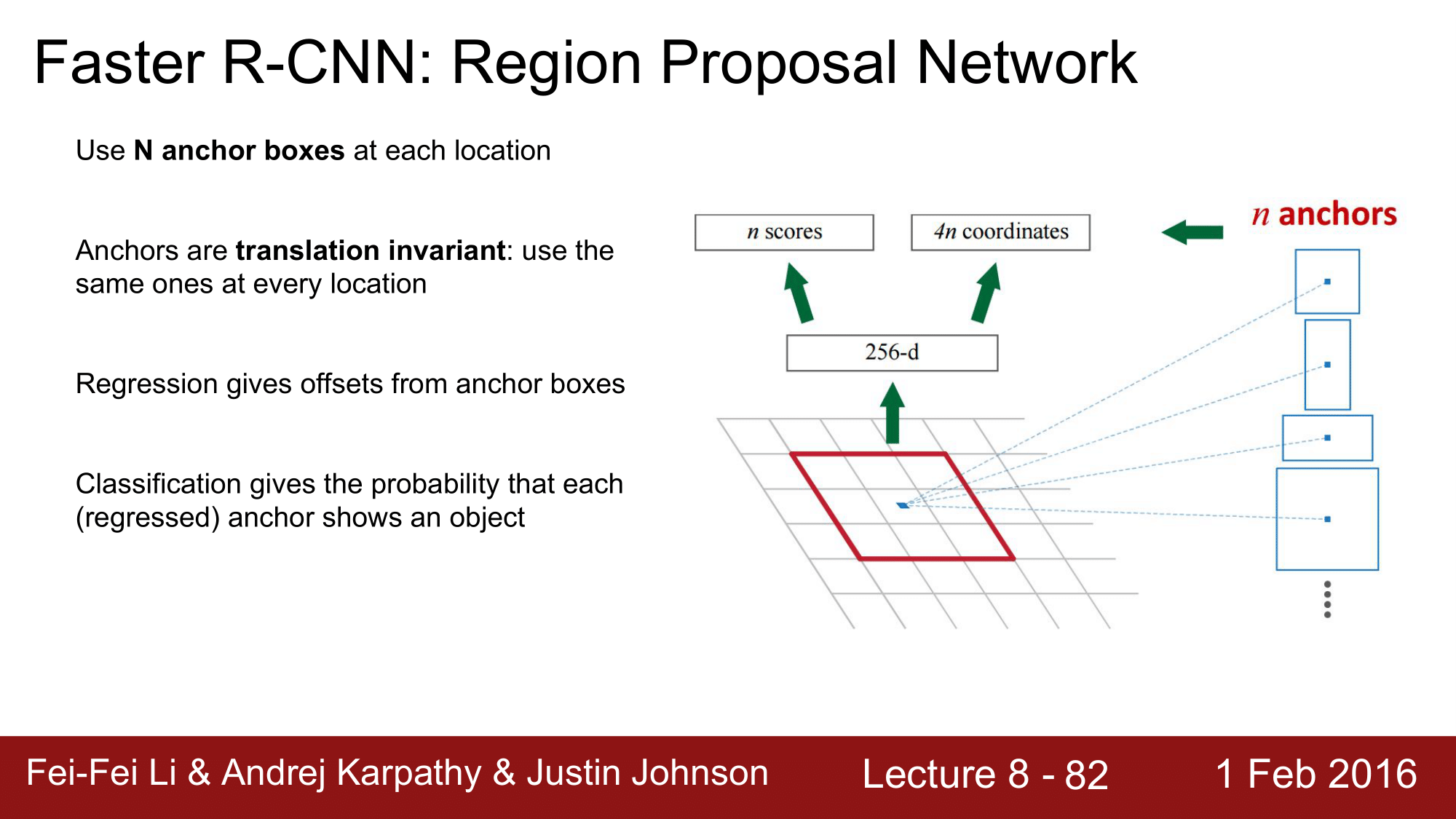
여기에 anchor box 라는 새로운 개념이 나오는데, anchor 라는 것은 슬라이딩 윈도우 내에 존재하는 local window 라고 생각하면 됩니다.
논문에 의하면, anchor 는 특정 위치 sliding window 마다 9개가 존재합니다. 9 개의 anchor 는 각각 다른 크기와 가로 세로 비율을 갖게 됩니다.
RPN에서는 각각의 anchor 가 전경인지 배경인지 object 인지 아닌지를 classify 한 다음에 전경인 경우에 해당 anchor 를 ground truth bbox 에 fit 하도록 stretch 해주는 방식으로 진행하게 됩니다.
Regression 은 anchor boxes 로 부터 얼마나 떨어져 있는 지에 대한 값을 제공하고, Classification 에서는 각각의 anchor 가 object를 보이고 있는지의 확률을 제공하게 됩니다.
결과적으로, 각각 다른 크기와 가로 세로 비율을 가지는 9개의 anchor box 들을 original image 에 투영하게 됩니다. 이때 feature map 의 point 에 대응하는 이미지 내의 포인트에 paste 하게 됩니다.
앞에서 살펴봤던 Fast R-CNN에서는 이미지에서 feature map 쪽으로 projection 을 했던 것과는 반대의 개념입니다. 즉, Faster R-CNN에서는 feature map에서 이미지 쪽으로 투영한다라고 생각하면 됩니다.

최초의 Faster R-CNN 논문에서는 학습시의 pipeline 이 굉장히 복잡했었습니다. 그래서 논문을 발표한 다음 이를 다시 정리한 바가 있습니다.
결과적으로는 이와 같이 하나의 거대한 network 내의 4가지 loss 를 갖는 것으로 정리 된 것입니다.
오른쪽 그림을 보면, 먼저 이미지를 받아서 RPN 쪽에서는 Classification Loss 로 각각의 Region Proposal 의 object 여부를 판별해주고 Bounding Box Regression Loss 에서는 Convolution 의 Anchor 상의 regression 을 수행하게 됩니다. 그렇게함으로써 anchor box로 부터의 거리 값을 주게 됩니다.
그리고 RoI Pooling 쪽에서 RoI 를 하면서 Fast R-CNN의 과정을 거치게 되는데, Classification Loss 에서는 해당 object 가 어떤 class 인지를 알려주고, Bounding-box Regression Loss 에서는 region proposal 상에서 보정을 해주게 됩니다.
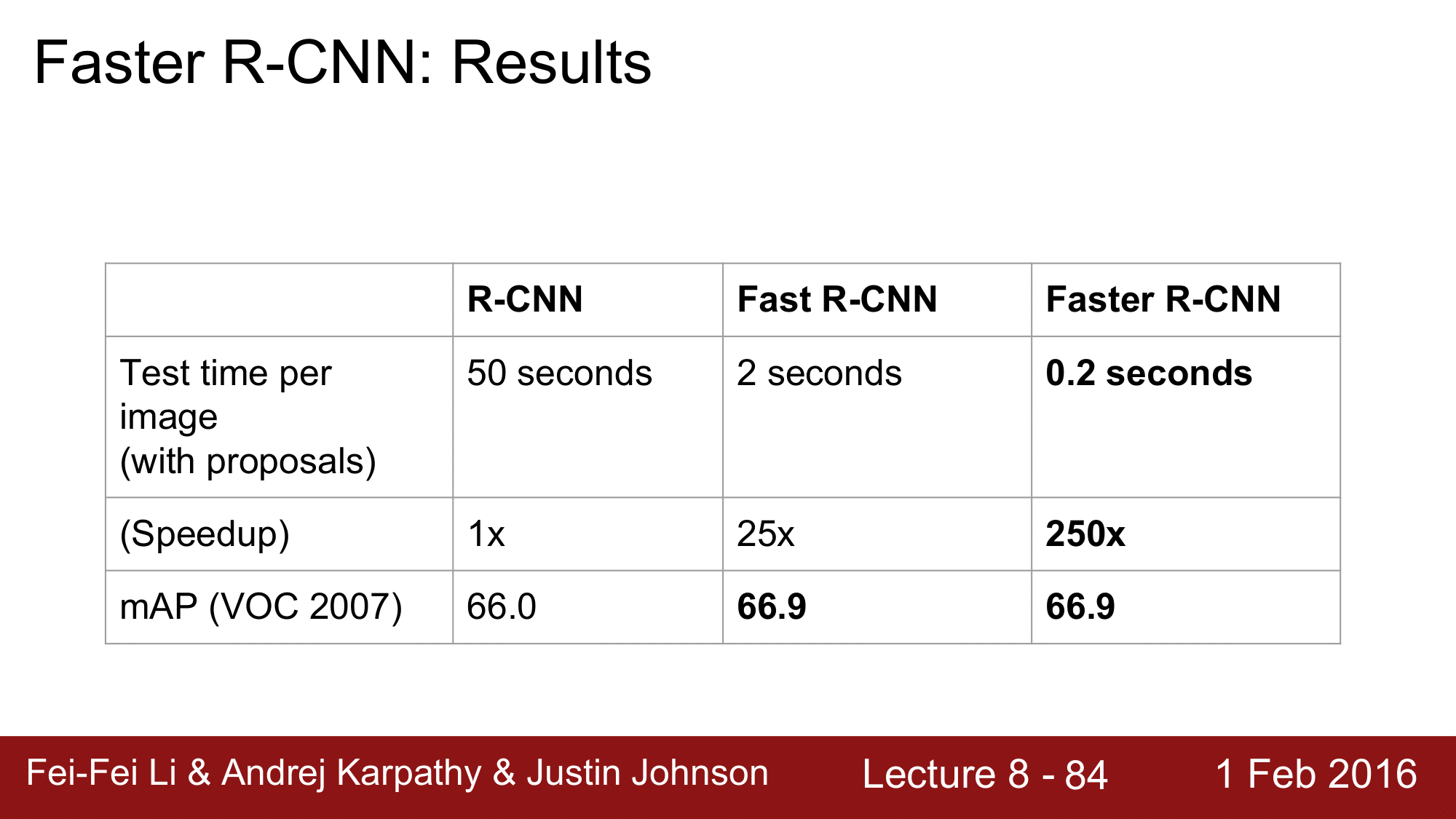
결과를 보게되면, Fast R-CNN 에서 테스트때 Region Proposal 까지 포함해서 2초정도 걸리던 것이 Faster R-CNN에서는 Region Proposal을 pipeline 내에 통합시키고서도 0.2초 밖에 걸리지 않는 성과를 확인할 수 있습니다.
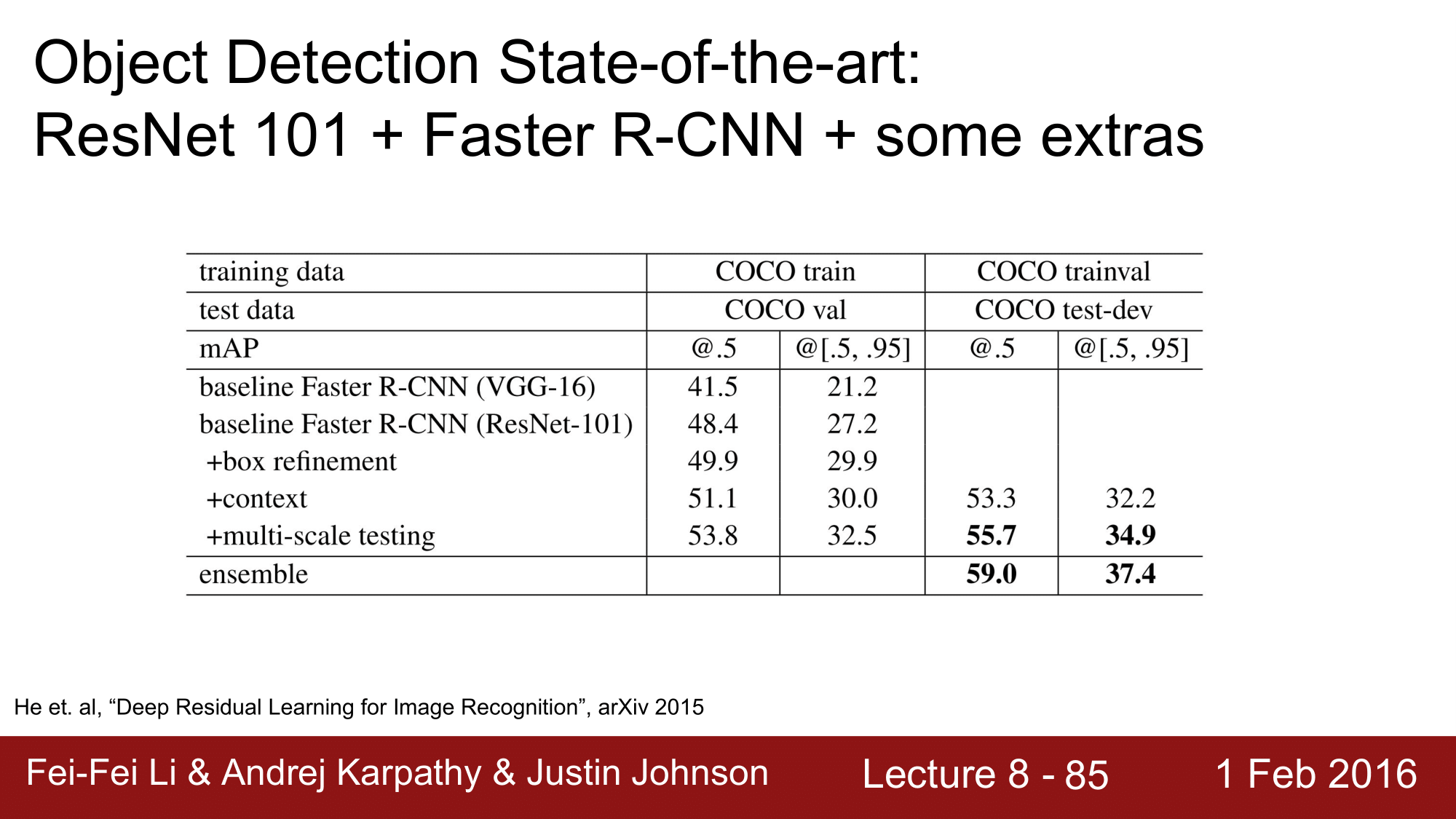
현재 Object Detection 에서 State of the art 는 ResNet + Faster R-CNN 과 몇가지 추가 작업(box refinement; bbox 조정, context, multi-scale testing)을 한 것입니다.
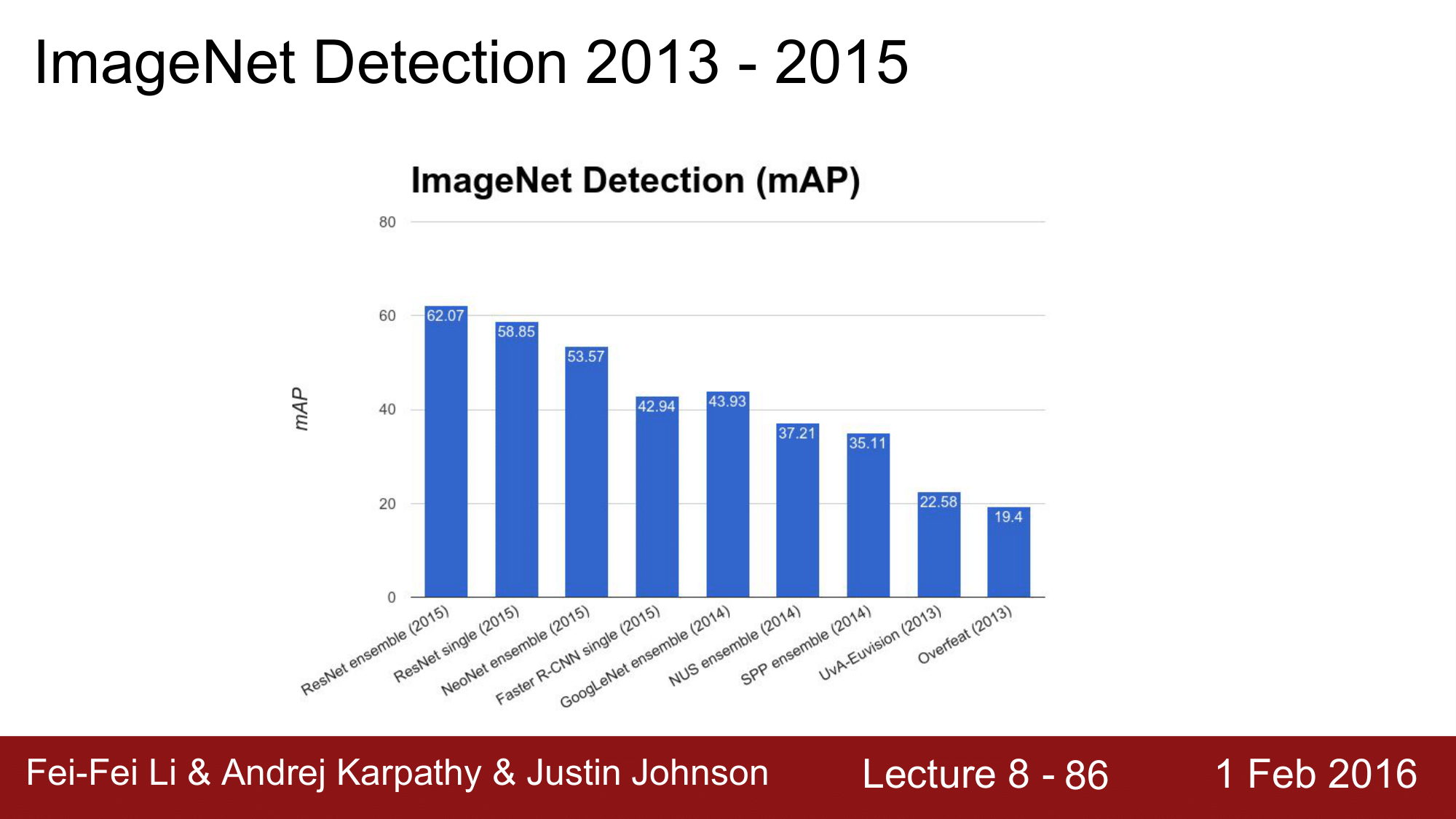
ImageNet에서 Detection 관련 competetion 은 2013년 Overfeat 에서 2015년 ResNet ensemble 까지 19.4% 에서 62%를 넘는 수준까지 발전해왔다는 것을 확인할 수 있습니다.
마지막으로 볼 것은 YOLO 라는 것입니다.
YOLO: You Only Look Once; Detection as Regression

Detection 을 Regression 으로 간주하게 되면, 정해진 수에 대한 detection 만 가능하기 때문에 적절하지 않다라는 것을 설명한 바가 있습니다. 그래서 detection 을 classification 이라고 간주했었는데, YOLO 는 그 부분에 challenge 를 건 것입니다.
그래서 YOLO는 Detection 을 Regression 으로 간주하고 적용하겠다는 모델이 되겠습니다.
일반적으로 이미지를 7 x 7의 grid 로 나누게 되고, 각각의 grid cell 에서 2가지를 예측합니다.
4개의 좌표와 하나의 score 인 confidence 를 가지는 B 개의 박스들, class 개수를 나타내는 C개의 숫자들로 예측하게 하는 것입니다.
이렇게 하게 되면, 이미지로부터의 regression 이 7 x 7 x (5 * B + C)의 tensor 인 regression이 될 수 있는 것입니다. 즉, input 은 이미지이고, output은 7 x 7 x (5 * B + C)인 tensor 인 regression으로 만들어 줄 수 있습니다.

YOLO의 성능은 Faster R-CNN 보다 굉장히 빠릅니다. 하지만 정확도면에서 다소 떨어지는 결과를 보입니다.
오른쪽 표를 보게되면, YOLO 의 정확도가 Faster R-CNN VGG 에 비해 떨어지는 것을 볼 수 있습니다. 하지만 FPS 는 R-CNN 의 경우 최대 18인 반면, YOLO 는 45로 real-time 으로 동작이 가능한 것을 볼 수 있습니다.
실제로 자동차로 이동하면서 차량이나 행인들과 같은 object 를 인식하는 부분에서 YOLO를 많이 활용하는 것을 볼 수 있습니다.

위의 링크들은 Object Detection 관련한 링크들입니다.
정리

이번 포스트의 내용에 대한 정리입니다.
Faster R-CNN에 와서야 region proposals 가 network 내로 완벽하게 통합되었다라는 것을 기억해주면 좋을 것 같습니다.