
해당 포스트는 송교석 님의 유튜브 강의를 정리한 내용입니다. 강의 영상은 여기에서 보실 수 있습니다.
저번 포스트에서 CNN 의 History 에 대해서 알아 보았습니다. 이번 포스트에서는 CNN(Convolutaional Nerual Network)를 좀 더 상세하게 살펴보겠습니다.

1. Convolutional Neural Networks
Convolutinal Layer
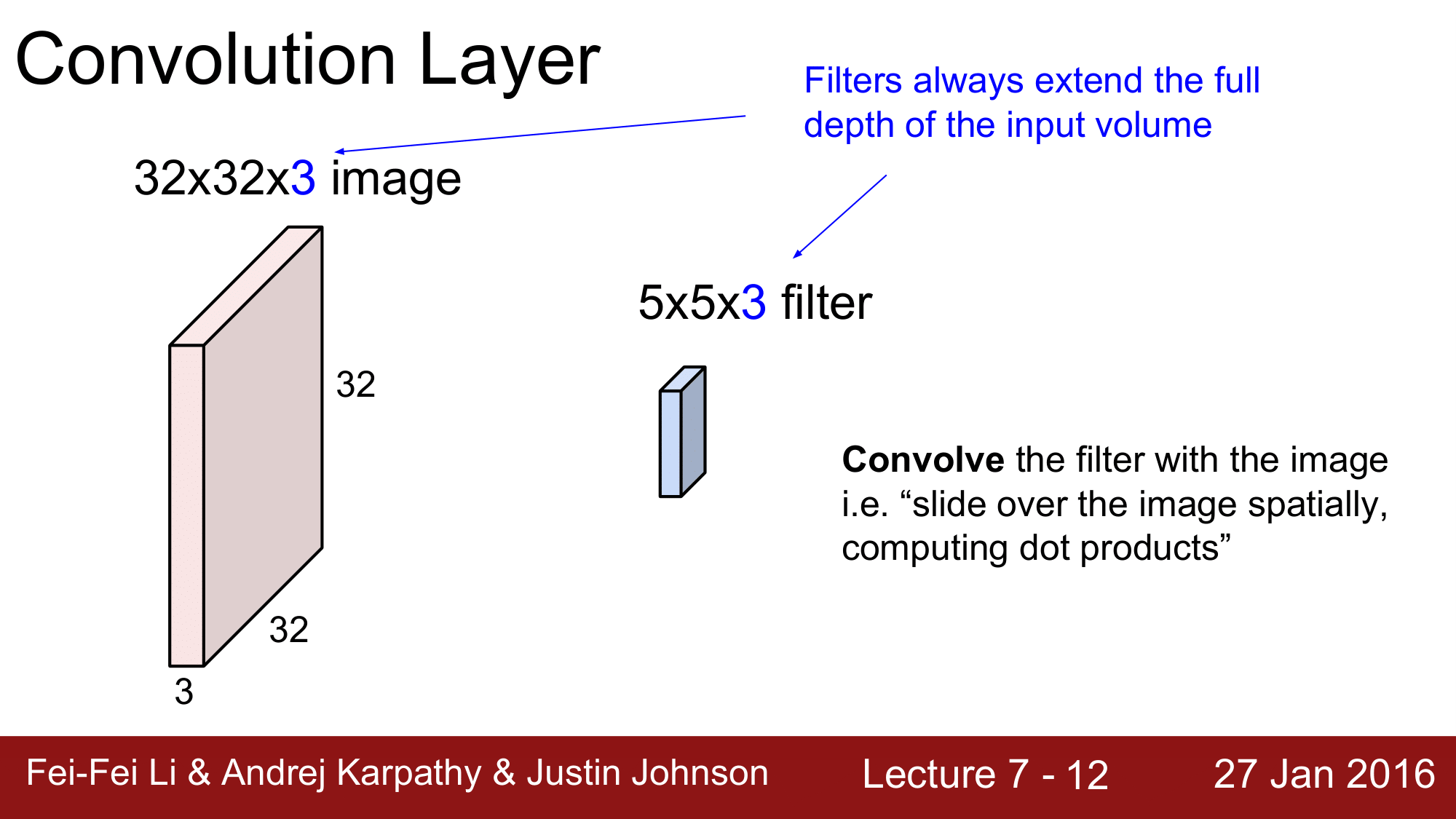
기본적으로 위 그림과 같이 32 x 32 x 3 의 이미지(CFAR-10)가 width x height x depth 로 구성되어있습니다. 그래서 CNN 은 3차원으로 구성된 Volume 위에서 동작을 하는데, 각각의 레이어들은 volumes of activations 을 받아서 이를 다시 재생산하는 식으로 구성이 됩니다.
좀 더 자세히 보면, 5 x 5 x 3의 필터를 이미지 위에서 convolution 을 수행하기 때문에, convolution layer 라고 합니다.
Convolutional Opertaion 의 정의는 필터를 이미지 위에 Convolution 시킨다. 즉, “공간적으로 이미지 속을 slide 하면서 dot product 연산을 해 나간다” 라는 의미가 됩니다.
위 그림에서 주의깊게 보아야 하는 것은 비록 width 와 hegiht 는 32 x 32, 5 x 5로 작은 부분만 cover 하지만 depth 는 3으로 같다는 점입니다.
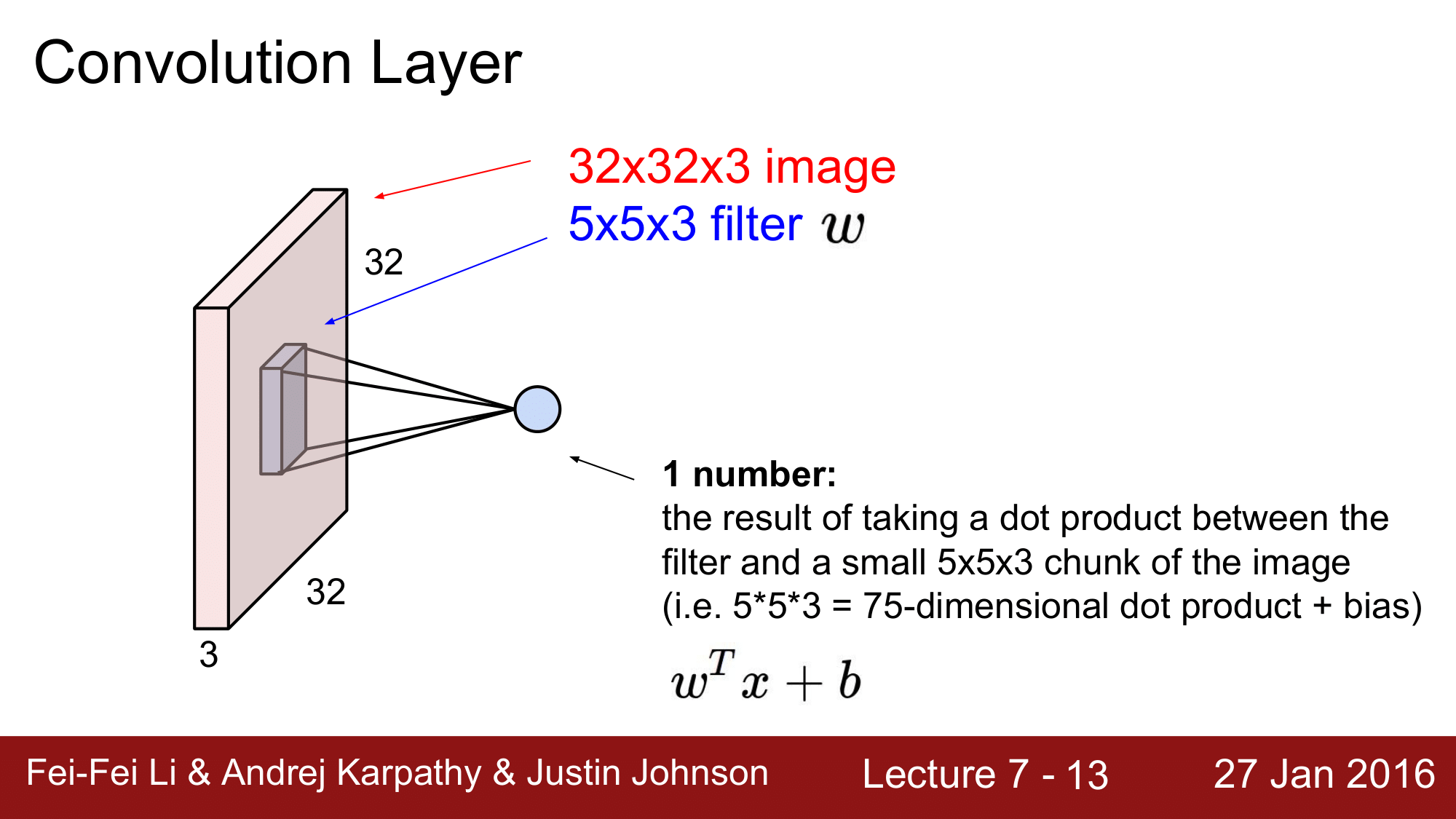
위 그림에서 처럼 필터 $w$ 가 이미지 위를 훑어나가는 식으로 진행하게 됩니다.
필터가 5 x 5 x 3 의 이미지 조각에서 dot product 연산을 하게 되면, 75 번의 dot product 연산을 하고, 그에 대한 결과를 하나의 숫자로 return 합니다. 즉 하나의 location 당 하나의 숫자를 생상하는 것 입니다.
이렇게 필터가 각 location 을 slide 하게 되면 다음 그림과 같이 28 x 28 x 1의 형태의 숫자들을 return 하게 됩니다.
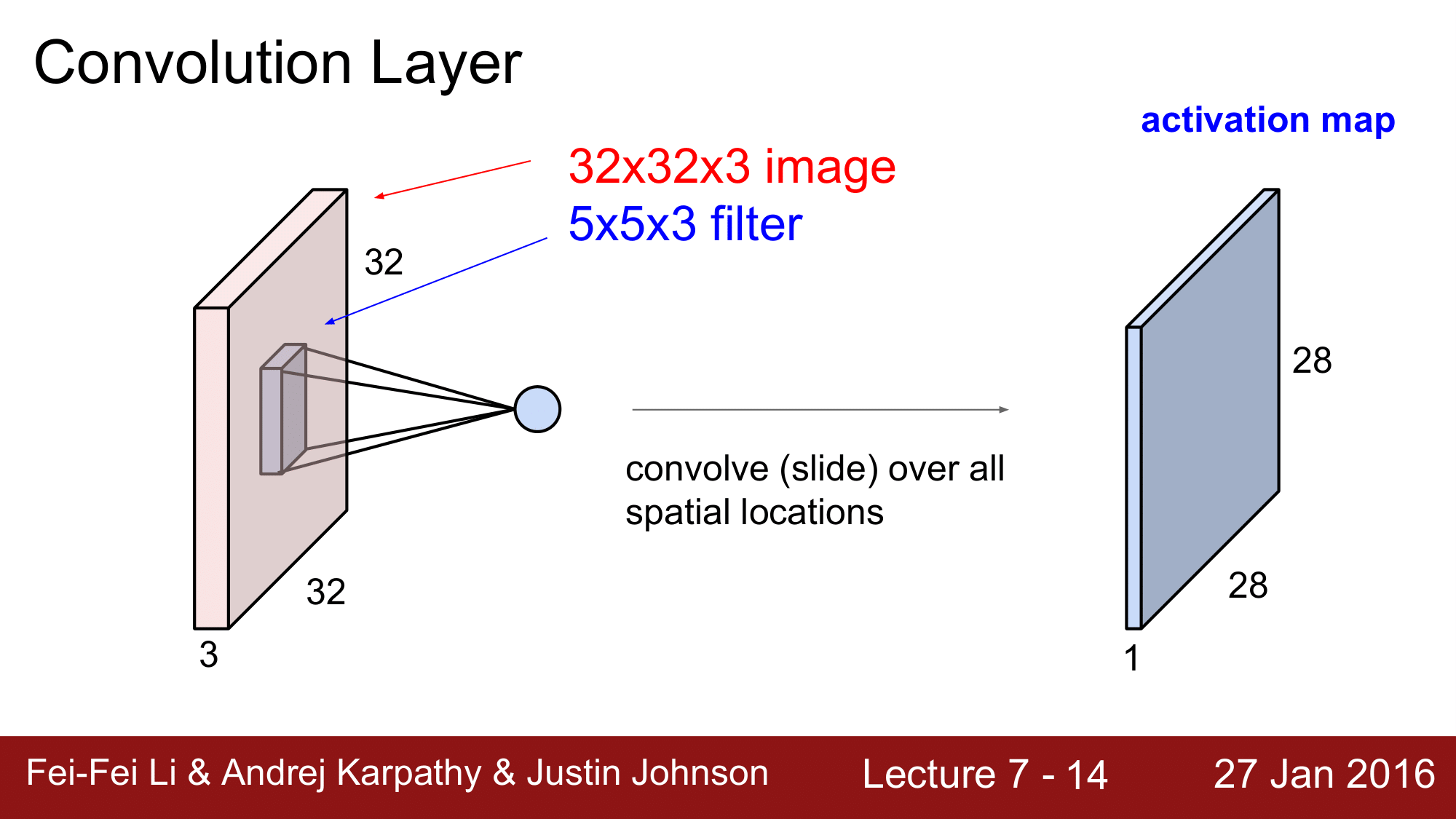
이렇게 새로 생성된 matrix 를 activation map 이라고 합니다.
그래서 하나의 filter 는 하나의 activation map 을 생성한다 라고 기억하면 됩니다.
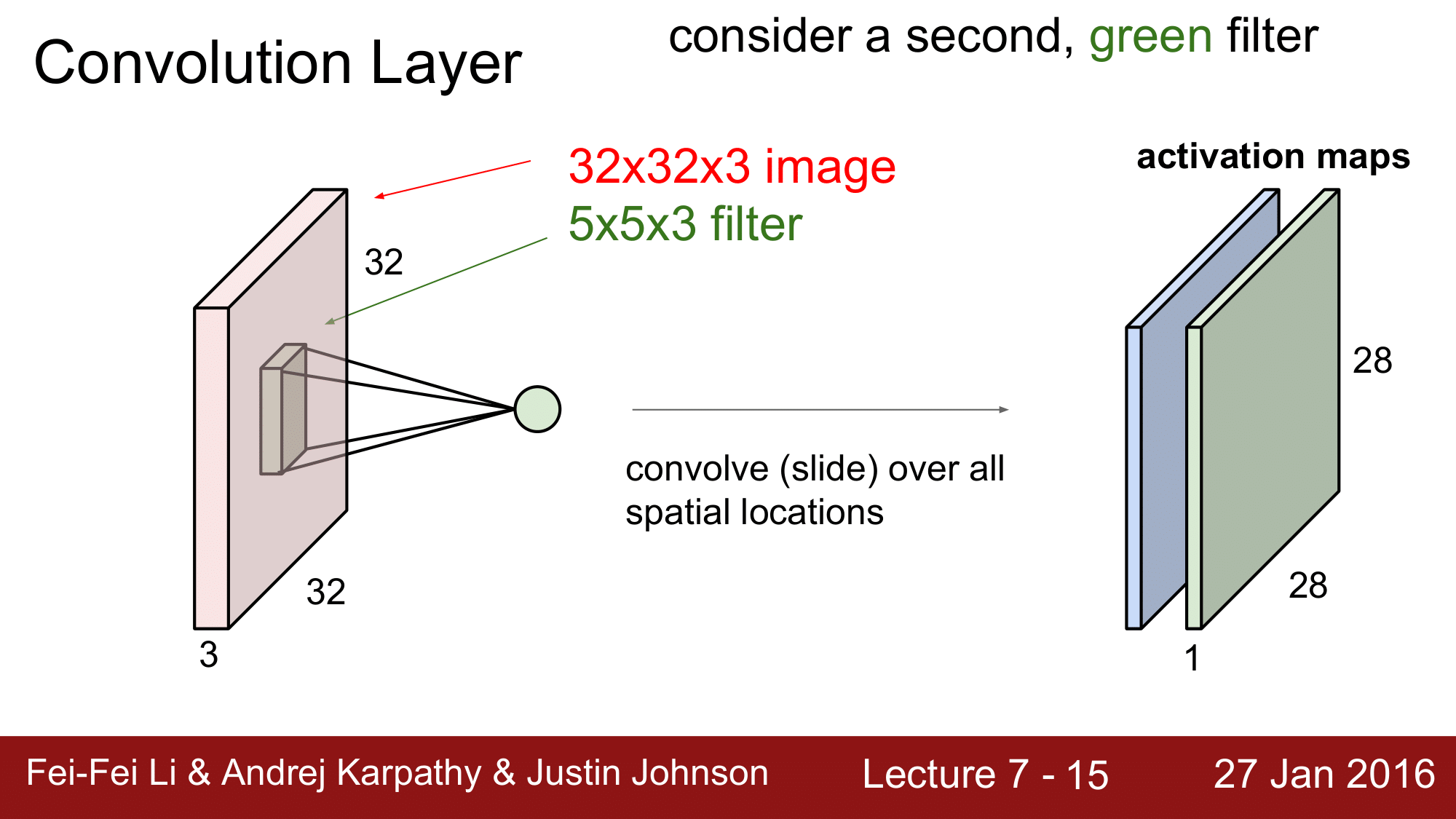
그런데, 여기서 녹색으로 된 두 번째 filter 를 가정해보겠습니다.
이렇게 되면, 녹색 필터가 다시한번 convolution 을 진행하면서 위에서 만든 activation map 과 같은 크기의 새로운 matrix 를 생성하게 됩니다.

one filter, one activation map 이라고 했으므로, 6개의 필터를 갖고 있으면 6개의 activation map을 가지게 되는 것 입니다.
이는 또한, “32 x 32 x 3 의 이미지를 input 으로 받아 이를 어떤 activation 의 관점에서 28 x 28 x 6 이라는 새로운 형태의 이미지로 re-representaion 을 했다” 라고 생각할 수도 있습니다.
아무튼, 이렇게 생성된 결과물이 다음 convolution layer 의 input 으로 전달되는 것 입니다.
그래서 이 과정을 보게 되면 다음과 같습니다.
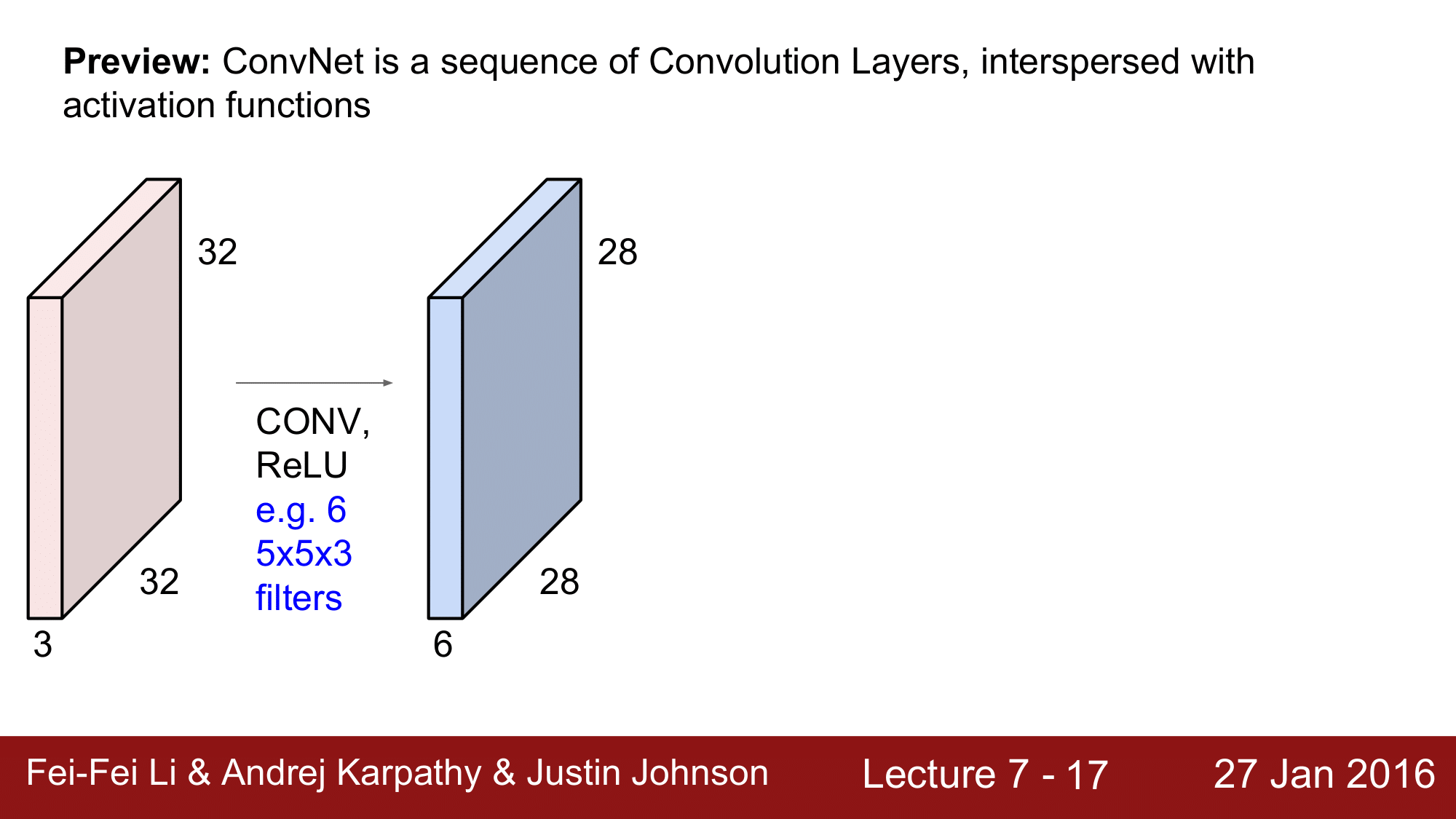
처음 32 x 32 x 3 의 이미지를 input 으로 받아 ReLU를 통해 6개의 5 x 5 x 3 의 필터로 convolution을 하게 되면 28 x 28 x 6 이라는 activation volume 을 하나 얻게 되는 것입니다.
이 상태에서 단계를 하나 더 거쳐보겠습니다.
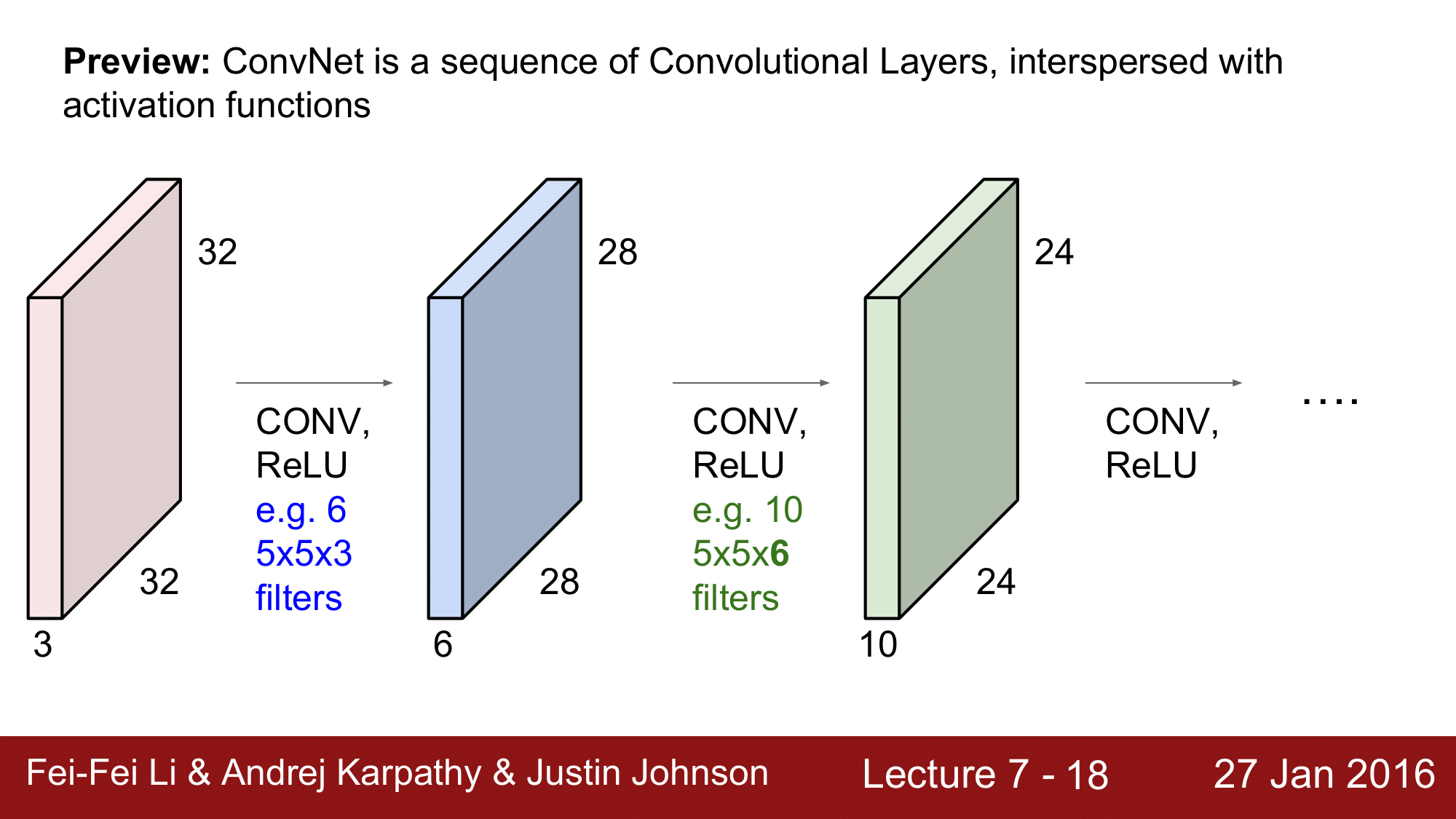
이번에는 10개의 5 x 5 x 6 의 필터(여기에서 6이라는 값은 반드시 적용하는 volume 의 depth와 같아야 합니다.)로 convolution 하여 24 x 24 x 10 으로 계속해서 진행되는 것이 CNN 의 기본적인 형태라고 할 수 있습니다.
물론 여기에서 기억해두어야 할 점은, 우리가 궁극적으로 update 해나가야 하는 parameter는 filter의 값들이라는 것입니다. filter의 초깃값은 당연히 random 하게 시작할 것 입니다.
이렇게 학습된 filter 를 시각화하여 보게 되면 다음과 같이 됩니다.
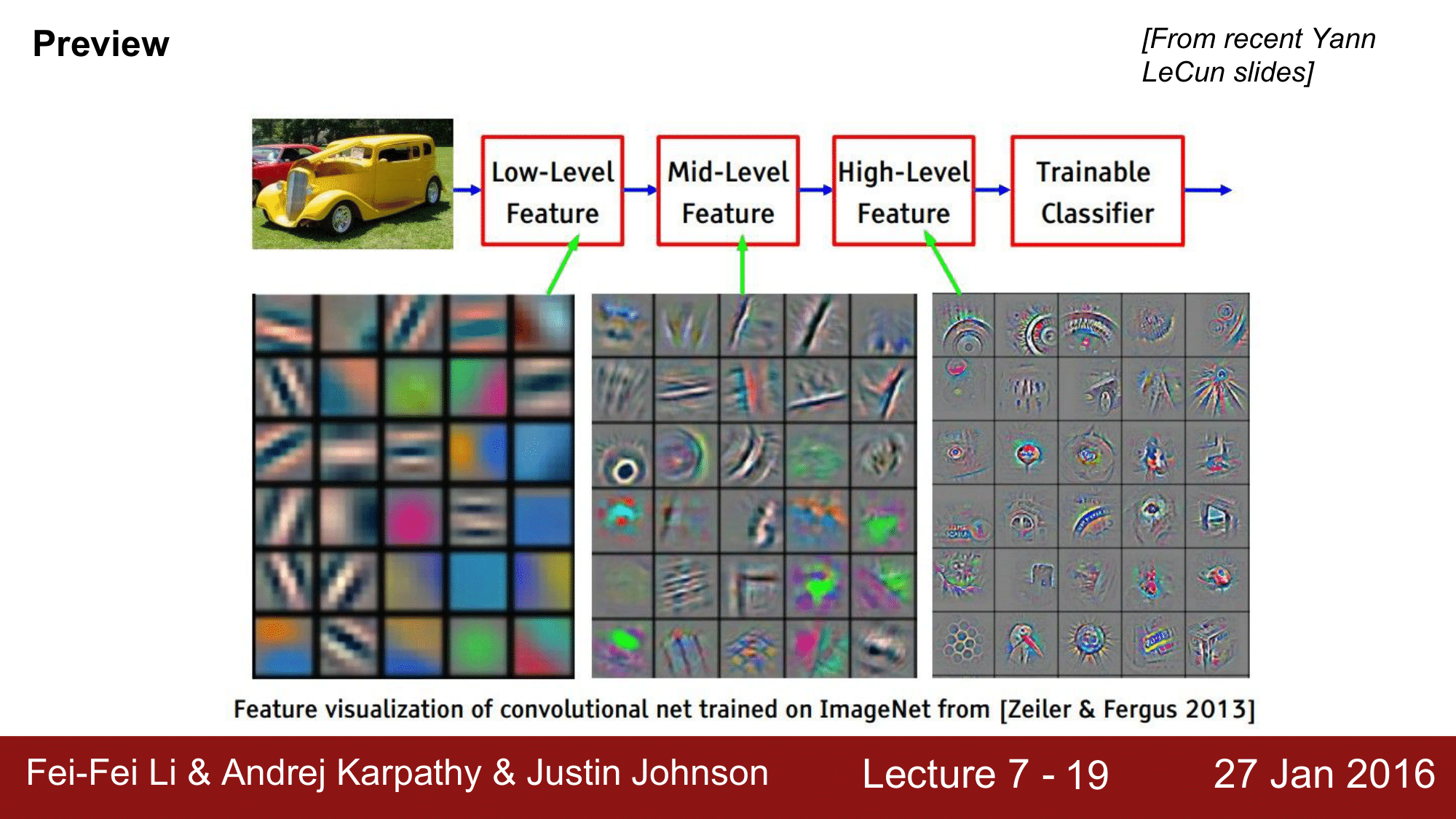
앞에서 진행한 CNN 을 통해 위와 같은 featural hierarchy를 얻게 됩니다.
이미지 바로 다음에 위치하는 첫번째 Convolution Layer 의 필터를 보게 되면 blob 들이 어떤 edge 나 color 로 되어 있는데, 이런 것들이 첫 번째 필터에서 볼 수 있는 것들 입니다.
그 다음 중간 단계로 진행이 되면, 앞 필터에서 나왔던 모양들이 좀 더 통합되는 것을 확인 할 수 있습니다.
깊은 레이어의 필터를 visualize 를 하게 되면 더 상위 level 의 이미지를 볼 수 있게 됩니다.
여기에서 기억해야 하는 것은 다음과 같습니다.
첫번째 필터는 input 이미지의 low weight 를 시각화한 것이고, 뒷부분의 2, 3번 필터는 low weight를 시각화 한것이 아니라 자기 바로 앞단의 filter 를 기반으로 시각화 한 것이라는 것 입니다.
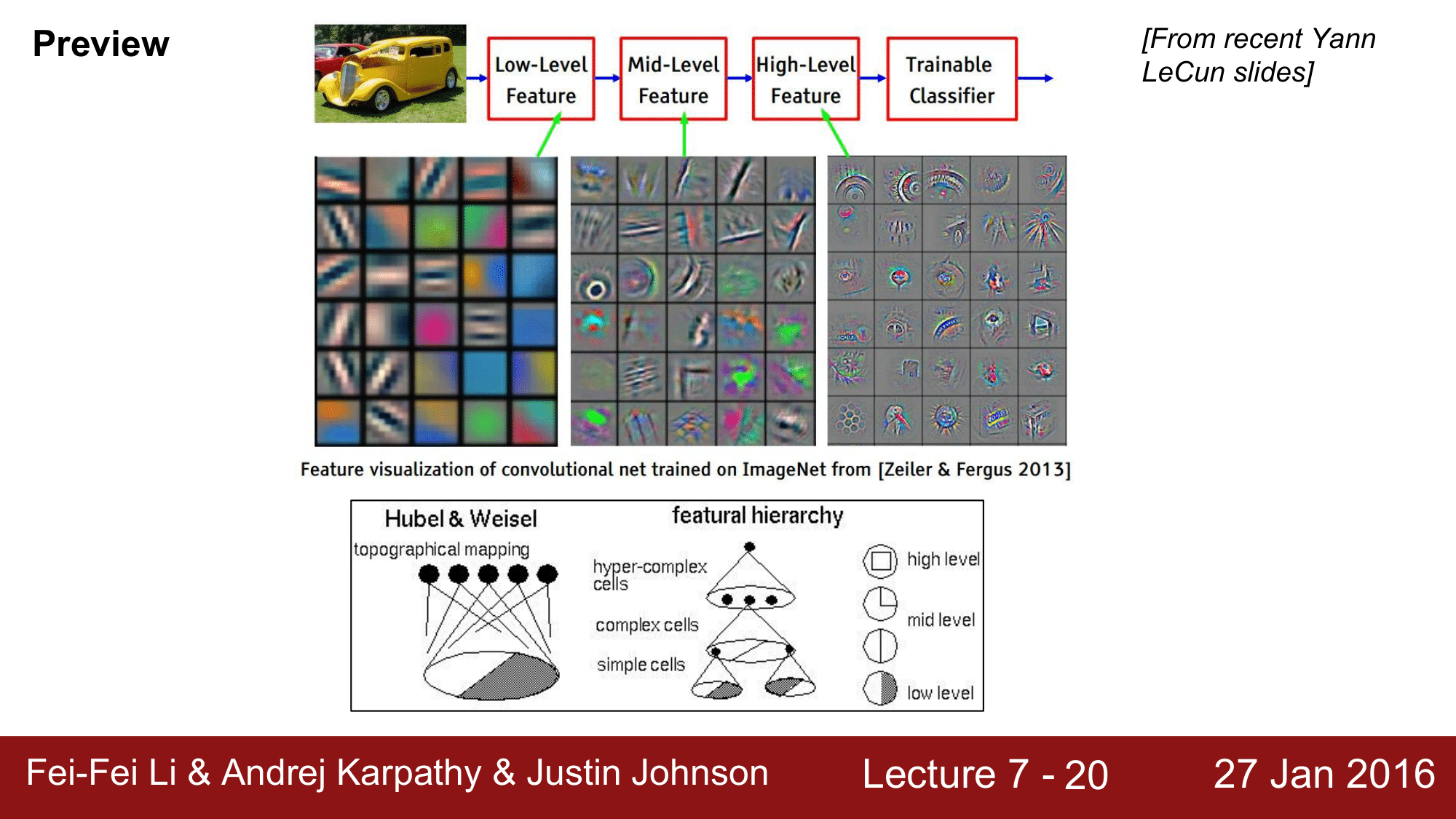
1959년의 Hubel & Weisel 이 상상했던 것과 굉장히 유사하게 나타난다는 것을 확인할 수 있습니다.

5 x 5 filter 가 총 32 개가 있을 때, 각 filter 에 대해 하나의 activation map을 생성하게 되면, 주황색 부분이 filter 를 거쳐 높게 activation 된 것을 확인할 수 있습니다.
하얀색 부분은 activation 이 높은 지점, 검은색 부분은 activation 이 낮은 지점 으로 생각 해 볼 수 있습니다.
그래서 Convolutional 하다라고 하는 것은 filter 와 image 라는 두 개의 시그널이 Convolution 작용을 한다는 것 입니다.

일반적인 CNN 은 위 그림과 같이 CONV, RELU, POOL 을 돌고 마지막에 FC Layer 로 Class의 Score 를 계산하는 식으로 구성이 됩니다.
10개의 filter 에서 10개의 activation map을 생성했고, column 내의 각 row 를 activation map 이라고 생각하면 됩니다.
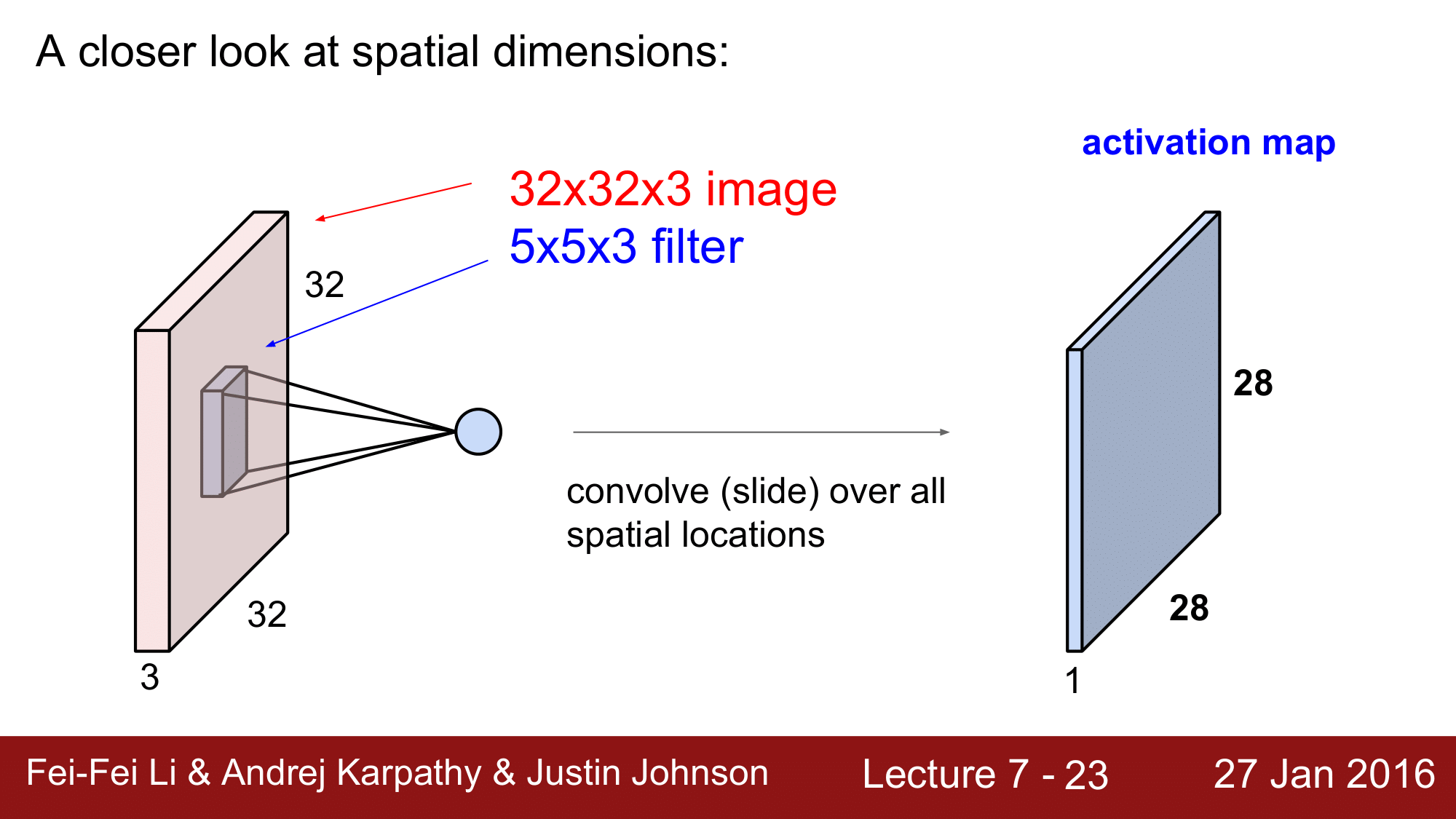
공간의 차원 관점으로 돌아와 좀 더 면밀히 살펴보겠습니다.
32 x 32 x 3 인 이미지에 5 x 5 x 3 의 필터를 convolution 해주어 28 x 28 x 1 의 activation map 을 얻을 때, 이 떄 28이라는 값은 어떻게 나오는 것 일까요?

7 x 7 이미지에 3 x 3 의 필터를 적용시켜 본다고 해보겠습니다.
left top 에서 right top 까지의 가로방향 이동에서 5번의 이동을 하게 됩니다. 이를 세로 방향으로도 적용하게 되면 총 5 x 5 의 이동을 하게 됩니다.
이것은 stride 를 1로 했을 때의 결과입니다.

만약 stride 를 2로 준다면, 2칸씩 이동하기 때문에 3 x 3의 결과를 얻게 됩니다.

만약 stride 를 3으로 주게 된다면, 한번 이동한 뒤 1칸이 남게 되기 때문에, filter 가 이미지에 맞지 않게 됩니다.

이를 일반화 하게 되면 위와 같이 공식화 할 수 있습니다.
\[\text{Output size} = \frac{(N - F)}{\text{stride}} + 1\]
현실적으로는, padding 을 이용합니다.
zero padding 을 이용하는데, 7 x 7 의 이미지가 있을 때, 그 테두리에 0으로 pad를 대주게 됩니다.
이렇게 zero padding 을 적용하게 되면, (7 - 3) / stride + 1에서 (9 - 3) / stride + 1이 되어 7 x 7의 결과를 얻을 수 있게 됩니다.
이처럼 padding 을 사용하게 되면, input의 크기를 보존할 수 있습니다.
input 이미지가 7 x 7 이었는데, output 도 7 x 7 로 나오게 되는 것입니다.
이렇게 size 를 보존함으로써 size 에 신경쓰지 않게 해주기 때문에, 매우 편리하게 사용할 수 있습니다.
즉, convenience 가 padding 이 유용한 첫 번째 이유가 되겠습니다.
size 를 유지하기 위해서는 몇개의 padding 을 해주어야 하는지는 다음과 같이 생각할 수 있습니다.
\[\text{P} = \frac{(F - 1)}{2}\]필터의 크기가 3 x 3 이면 패딩의 크기는 1, 5 x 5면 패딩은 2. 이런식으로 패딩을 설정해주면 convolution을 진행하면서도 size 를 유지 할 수 있게 됩니다.
Input 과 Output의 크기를 같게 하려면, Input의 크기가 N이라고 할 때, $N = \frac{(N + 2P - F)}{S} + 1$ 입니다.
이때, $S = 1$이므로 $P$에 대해서 식을 정리하게 되면 위 식을 얻을 수 있습니다.
이렇게 패딩을 이용해서 size 를 유지하는 것이 왜 중요할까요?
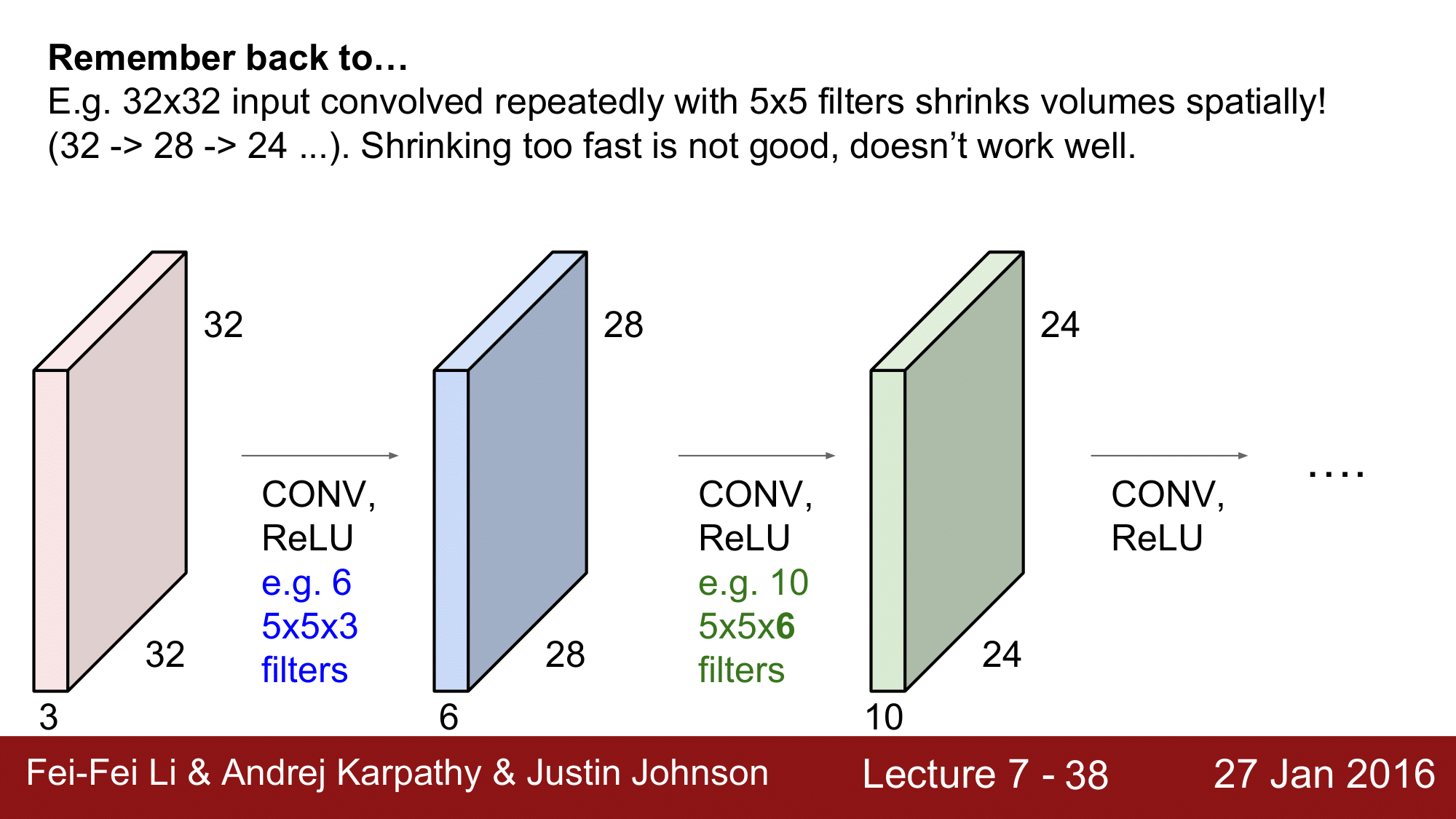
앞에서의 예를 살펴보면 volume 의 크기가 32 -> 28 -> 24 로 계속해서 줄어드는 것을 볼 수 있습니다. 이렇게 계속해서 진행하다보면 0까지 가게 되면 결국 volume 자체가 shrink 해버리게 됩니다.
input 이 굉장히 거대한 신경망을 거친다고 생각을 해보겠습니다. 이러한 거대한 신경만은 수백개에서 수만개의 layer 를 거치게 될텐데, 위의 예에서는 불과 8개의 layer를 통과하면 0이 되어버리게 됩니다.
이렇게 되면 더 이상 convolution을 진행할 수 없게 됩니다.
따라서 위와 같은 문제를 해결하기 위해 padding 이 유용한 것입니다.
정리하자면, padding 은 convenience하고 representation이 가능하기 때문에 매우 유용하다고 할 수 있습니다.
그래서 이런 convolution layer 에서는 padding 을 이용해서 size를 보존해주되, size를 점점 줄여나가는 것(down sampling)이 의미가 있기 때문에, down sampling 은 조금 후에 살펴볼 pooling layer 에서 진행하게 됩니다.
요약

Conv. Layer는 앞단에서 $W_1 \times H_1 \times D_1$의 Volume 을 받아서 다음단의 $W_2 \times H_2 \times D_2$의 Volume 을 생성해주는 역할을 합니다.
이 때, 항상 4가지의 하이퍼파라미터를 필요로합니다.
- 필터의 개수 $K$
- 필터의 크기 $F$
- 스트라이드 $S$
- 패딩 $P$
앞에서 본 대로, $W_2, H_2, D_2$는 다음 공식을 통해 구할 수 있었습니다.
\[\begin{aligned} W_2 &= \frac{(W_1 - F + 2P)}{S} + 1 \\ H_2 &= \frac{(H_1 - F + 2P)}{S} + 1 \\ D_2 &= K \end{aligned}\]여기서 주의해야할 점은, output의 depth $D_2$는 filter의 개수 $K$와 동일하다는 것입니다.
Weight의 총 개수는, 각각의 filter에 대해 $F \cdot F \cdot D_1$ 개의 파라미터를 갖기 때문에 이에 필터의 개수 $K$ 를 곱한 $(F \cdot F \cdot D_1) \cdot K$개가 됩니다.
여기서 $K$는 일반적으로 $2^n$의 형태를 띄게 되는데, 이는 Computation을 하는 과정에서의 편리함과 성능의 이점을 얻기 위함입니다.
마지막으로 패딩 값은 다음 식을 통해 얻을 수 있었습니다.
\[P = \frac{(S - 1)(N - 1) + (F - 1)}{2}\]위의 빨간색으로 표시된 F와 S의 값들을 대입하여 P 값을 구해보면 $N \equiv 0 \mod 2$ 라는 사실을 알 수 있습니다.
그리고 $F = 1, S = 1$ 인 경우에 대해서 좀 더 자세히 살펴보겠습니다.

1 x 1의 필터를 convolution 하는 것은 의미가 없을 것 같지만, 충분의 의미가 있습니다.
만약 2D를 1 x 1 필터로 Conv. 한다면 output이 input과 같아서 의미가 없겠지만, 64라는 depth를 가진 3차원에서 필터가 1 x 1 x 64의 fiber 를 거치면서 dot product 를 수행하기 때문에 충분히 의미가 있다는 것 입니다.
32 개의 필터가 있다고 한다면, 56 x 56 x 32 의 output을 얻게 됩니다.
이런식으로 1 x 1 의 Conv. 도 의미가 있다고 할 수 있습니다.
pyTorch Framework

몇 가지 Framework 들에 대한 실행 예를 한번 살펴 보겠습니다.
- nInputPlane: 채널의 수로 Input 의 Depth 즉 $D$가 됩니다. 이미지에서는 보통 RGB로 3이 됩니다.
- outputPlane: 필터의 개수로 $K$를 의미
- kW, kH: 각각 Width, Height 에 대한 필터의 크기로 $F$를 의미
- dW, dH: 스트라이드 $S$를 의미
- padW, padH: 패딩의 개수 즉 $P$를 의미
Caffe Framework

Caffe Framework 에서는 다음과 같은 방식으로 구성됩니다.
num_output: $K$kernel_size: $F$stride: $S$
Lasagne Framework

- num_filters: $K$
- filter_size: $F$
- stride: $S$
- pad: $P$
이런 식으로, 모든 Framework 은 $K F S P$ 4개의 하이퍼파라미터를 반드시 입력하게 되어 있습니다.
Brain/Neuron 의 관점에서의 CONV
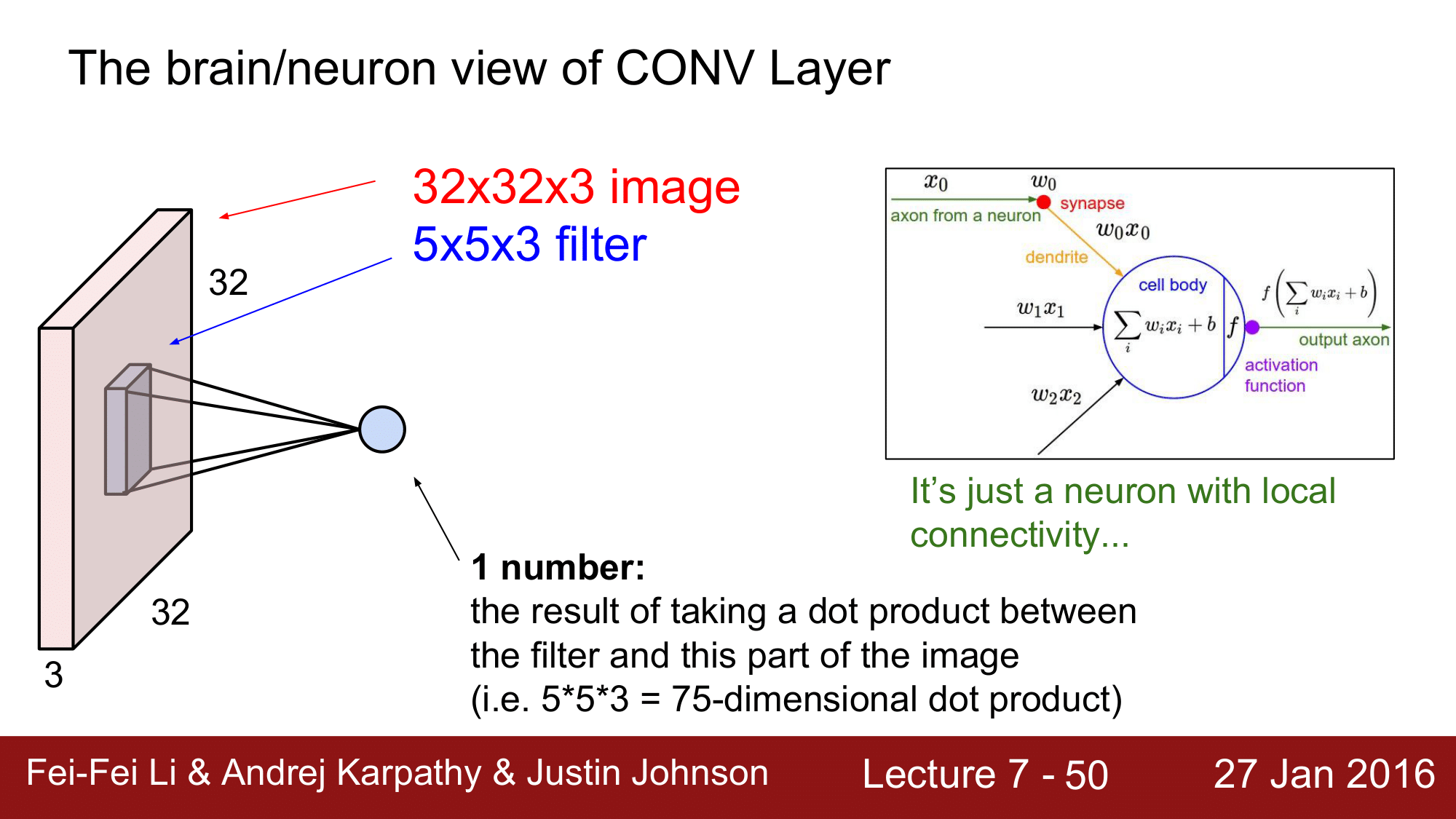
neuron (파란색 원)이 살펴보는 field를 receptive field 라고도 하는데, 이 부분을 neuron으로 표현하게 되면 우측 그림과 같이 됩니다. 이때 $w_1x_1 w_2x_2 w_3x_3$의 합을 구하게 되는데 이런 연결을 뉴런이 local connectivity 를 가진다라고 표현할 수 있게 됩니다.
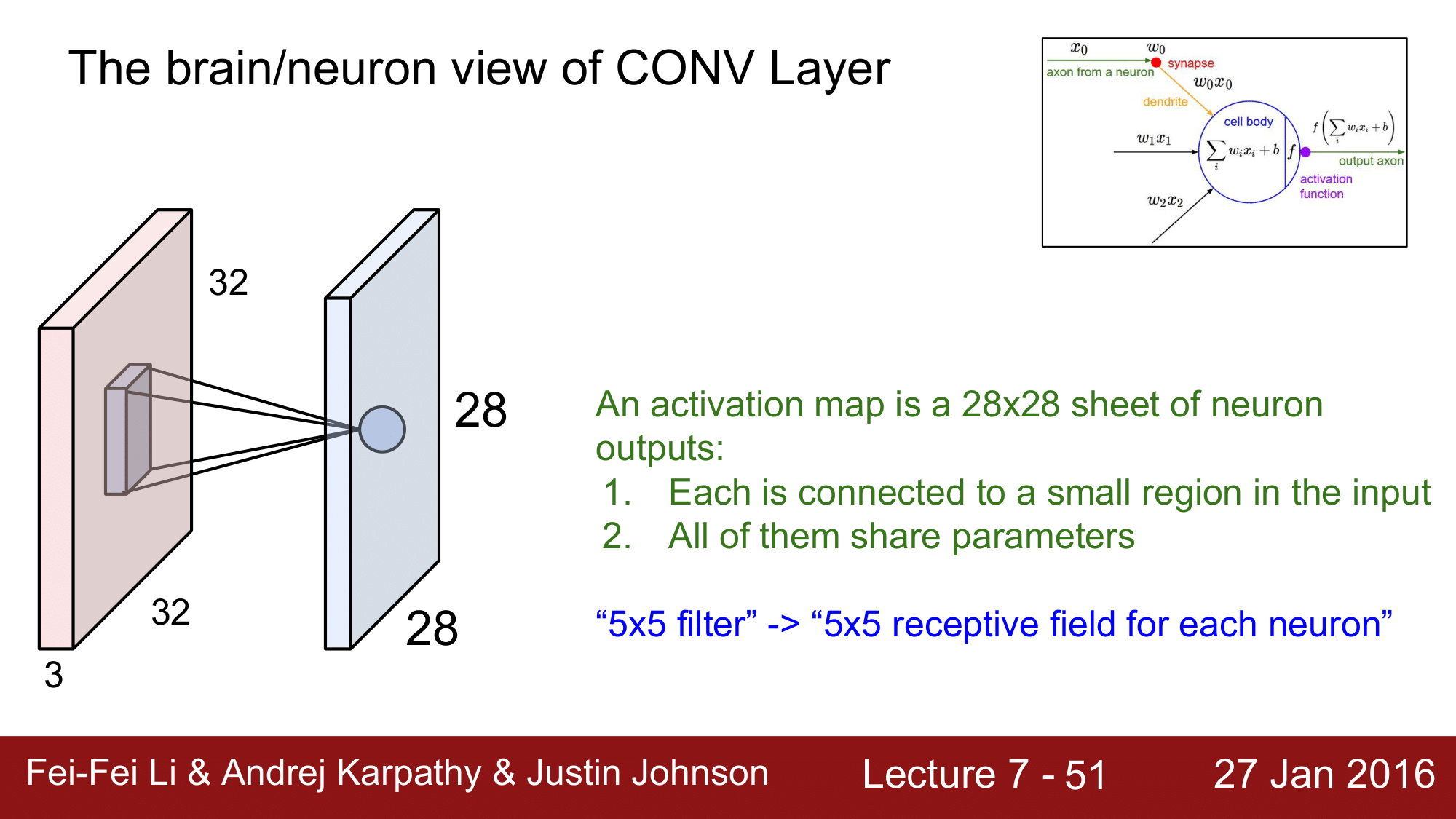
그래서 28 x 28 x 1 의 activation map 이 있을 때, 이 map 에 있는 각각의 neuron 은 작은 receptive field 에 연결이 되어 있습니다. 이런 식으로 각각이 input 의 작은 지역에 연결이 되어있는 것을 보고 local connectivity 를 가진다 라고 합니다.
또 한가지 중요한 사항은, 이 각각의 neuron 들이 동일한 파라미터들을 공유한다는 점입니다.
왜냐하면 activiation map 내의 각각의 neuron 들은 동일한 weight 즉, 동일한 파라미터를 가지는 하나의 filter의 dot 연산의 결과이기 때문입니다. 그래서 이런 면을 parameter sharing 이라고 합니다.
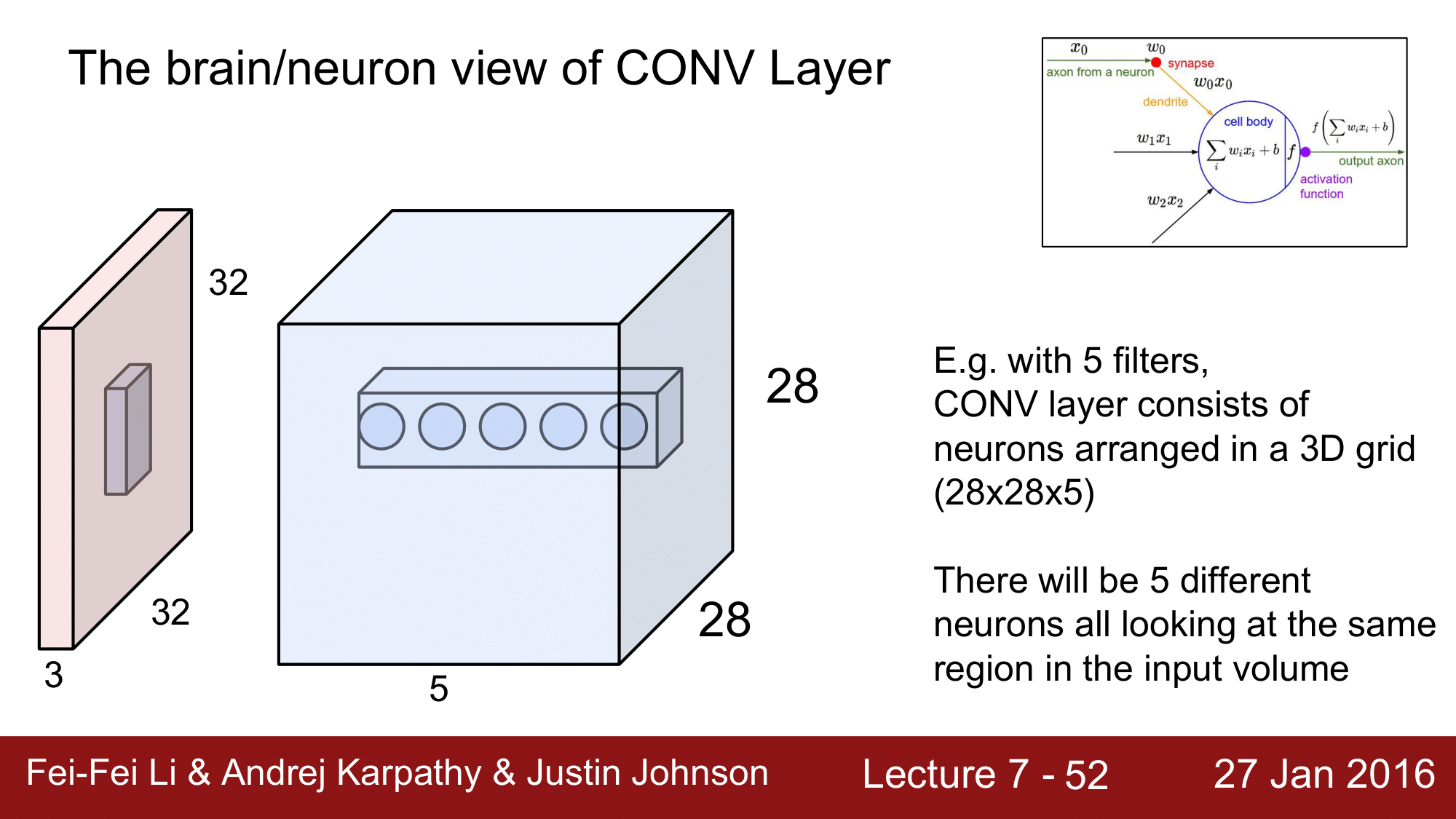
그런데 우리는 filter의 수가 5개라고 한다면, depth 가 5가 되고, Conv. Layer 는 위 그림과 같이 28 x 28 x 5 의 Volume 을 가지게 됩니다. 이렇게 되면 각각의 activation map에서 같은 위치에 있는 neuron 들은 input 이미지의 동일한 부분을 바라보게 됩니다.
하지만 같은 위치에 있는 이 nueron 들은 각각이 다른 activation map 에 속하는 것 이기 때문에, 각각 다른 weight 를 갖게 됩니다. 즉, 이들은 weight 를 공유하지 않는다 라고 할 수 있습니다.
그래서 정리하면, 동일한 depth 내의(같은 activation map 내의) neuron들은 동일한 weight 즉, parameter sharing을 하는 것이고, 별개의 activation map 에 속하는 각각의 neuron 들은 input 이미지의 같은 곳을 바라보는 같은 local connectivity 를 갖는다 라고 할 수 있습니다.
 지금까지 Conv. Layer 에 대해서 살펴보았습니다.
지금까지 Conv. Layer 에 대해서 살펴보았습니다.
Conv. Layer는 계속해서 size를 보존하기 때문에, Pooling layer 라는 것을 도입해서 size를 조정해주게 된다고 했습니다. 지금부터, pooling layer 에 대해서 알아보겠습니다.
Pooling Layer
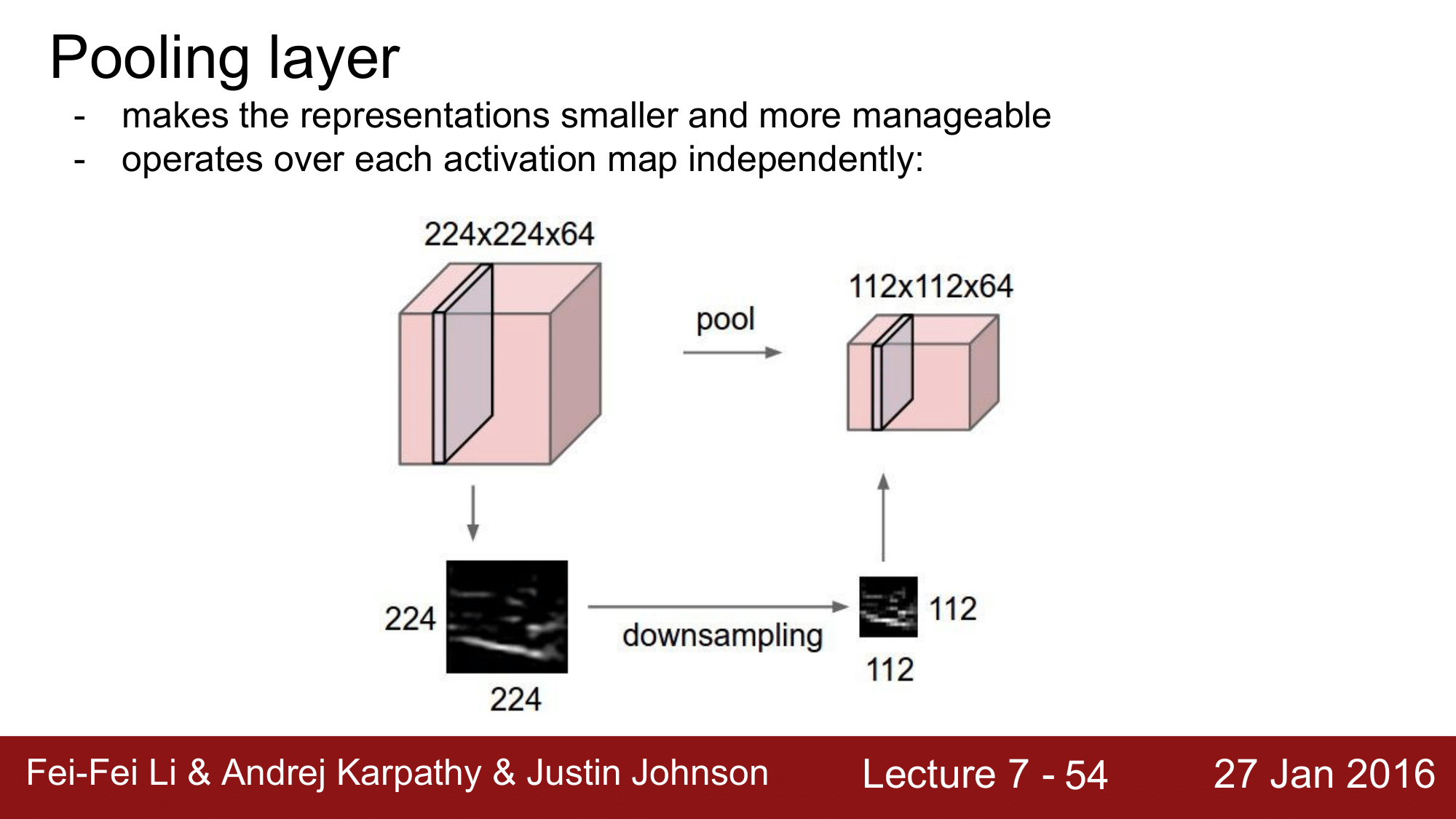
Pooling Layer 가 하는 것은 Volume 의 representation을 좀 더 작게, 좀 더 관리할 수 있게 만들어 주는 역할을 합니다.
이는 각각의 activation map 에 대해 독립적으로 작용을 합니다. 예를 들어, 244 x 244 x 64 의 Volume 이 있다고 해보겠습니다. 그러면 이 볼륨의 64개의 activation map 각각에 대해서 1/2 로 줄여주는 pooling 을 해주게 되는 것이고, 112 x 112 x 64 로 depth 는 그대로 유지가 됩니다. 이차원 형태로 보게되면 downsampling 이 되는 결과를 얻을 수 있게 됩니다.
Conv. Layer 에서는 size 를 유지하고, Pool. Layer 에서는 size 를 downsampling 해주는 역할을 해주는 것 입니다. 즉, size 는 Pool. Layer 에서 관리한다고 생각하면 됩니다.
Pooling Layer 에는 Conv. Layer 와는 다르게 파라미터가 없는 것을 확인할 수 있습니다. weight 도 없고 padding 도 없다는 것을 기억해두면 좋습니다.
MAX Pooling

pooling 방법에는 avg pooling 등 여러가지가 있지만, 가장 많이 사용하는 것은 이번에 설명하는 Max pooling 입니다.
왼쪽 그림과 같은 Volume 이 있을때, stride 를 2로 하는 2x2 필터로 max pooling 을 한다고 하면, 2x2 의 크기별로 나눠주고, 이들 중에서 가장 큰 값을 취하는 방식으로 downsampling을 해주게 됩니다.
이렇게 1/2 로 줄어드는 것은 앞에서 본 대로, $\text{output size} = \frac{(N - F)}{S} + 1$ 이기 떄문에 2라는 값을 얻게 되는 것 입니다.
그런데, 이렇게 max pooling 을 하게 되면, 정보를 잃는 것이 아닌가 라는 우려를 가질 수 있는데, 어느 정도 이렇게 downsampling 하는 것이 더 좋을 수 있다고 합니다.
역설같지만, 약간의 정보를 손실함으로써 오히려 invariance 한 속성을 얻게 된다라는 것입니다.
만약에 빨간색 6 이 자동차의 stiring wheel 이 된다고 하면, downsamping 을 하면서 6의 위치가 빨간색의 (0, 0), (0, 1), (1, 0), (1, 1) 중 어디인지에 대한 정보를 상실하게 됨으로써 역설적으로 invariance 를 얻을 수 있다라고 생각할 수 있습니다.
그래서 pooling layer 에 대해 다음과 같이 정리할 수 있습니다.

마찬가지로 $W_1 \times H_1 \times D_1$을 받아서 $W_2 \times H_2 \times D_2$를 생성하고, 필터의 크기 $F$ 와 스트라이드 $S$ 2가지를 하이퍼파라미터로 사용합니다. 여기에서는 Conv. 와 다르게 필터의 개수 $K$ 와 패딩의 크기 $P$는 필요하지 않습니다.
여기서도 눈여겨 보아야하는 점은, $D_2 = D_1$ 이라는 점입니다. 즉, output의 depth 는 변하지 않고 계속 보존이 된다는 것 입니다.
일반적인 setting 으로는 filter의 크기를 2x2 로 하고 stride 를 2로 하는 것이 1/2로 down sampling 을 하는 설정이 되겠습니다. 이외에 $F=2, S=3$ 인 경우도 종종 사용합니다.
Fully Connected Layer (FC Layer)

FC Layer 에 대해서 살펴보겠습니다. 10개의 필터가 있어서 4 x 4 x 10, 160개의 수로 구성이 되는데, 이것을 column vector 화 해서 FC 하게 연결한 다음 matrix multiplication 연산을 하여 결과적으로는 Softmax 에서 10가지 class 를 구분하게 하는 역할을 하는 것이 FC Layer 가 되겠습니다.
지금까지 공부했던 Conv. Pool. FC. 를 예제를 통해 살펴보겠습니다.
[ConvNetJs CIFAR-10 demo](https://cs.stanford.edu/people/karpathy/ convnetjs/demo/cifar10.html)
Case of CNN
지금부터, 주요한 Convolutinal Neural Network 들에 대해서 Case Study를 진행해보겠습니다.
LeNet-5
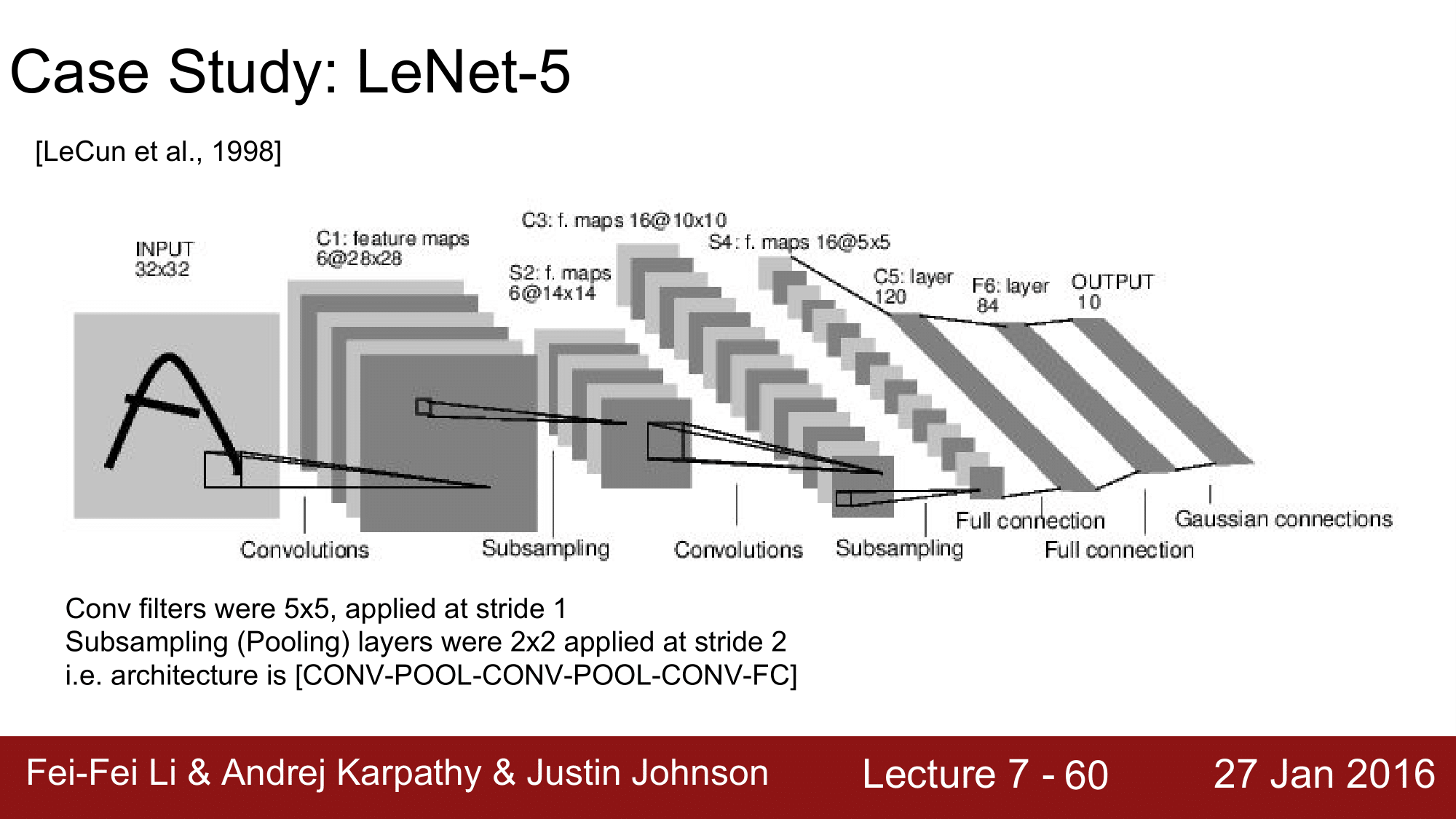
첫 번째로, LeNet 입니다. LeNet은 위와 같이 input을 받아서 C(Convolution), S(Sub-sampling; Pooling)을 반복하여 마지막에 FC 를 거쳐 output을 도출하는 식으로 구성됩니다. Filter 는 Conv. Layer 의 경우 5x5, stride=1로 구성되어 있고, Pooling Layer 의 경우 2x2, stride=2로 구성되어 있습니다.
즉, 처음에 input을 받아서 (32 - 5)/1 + 1 = 28 이므로, 28x28로 구성된 6개의 feature map 들로 구성이 되고, sub sampling을 할 때는 (28 - 2)/2 + 1 = 14 이므로, 14x14 의 feature maps 로 sub sampling 이 됩니다. 이런 식으로 계속 진행을 하여, output을 구하는 식으로 구성되어 있는 것이 LeNet이 되겠습니다.
AlexNet

다음으로는 2012년에 나온 AlexNet 입니다.
우선 input 을 227 x 227 x 3 으로 받아서 진행합니다. 그림에서는 224 로 나와있는데 오타입니다. 또한 그림이 윗 부분이 잘려 있는 것은 논문에 그림이 들어갈 때부터 잘려서 들어가서 그렇습니다.
위 그림을 보게 되면, 2개의 stream 으로 나뉘어서 진행이 되게 되는데, 이렇게 했던 이유는 2012 당시 GPU 의 성능이 좋지 않아서 2개의 GPU를 병렬로 처리하여 convolution을 했기 때문에 그렇습니다. 지금은 GPU 의 성능이 많이 좋아졌기 때문에, 두 개의 stream 으로 나눠서 진행하는 것이아니라 하나의 stream 으로 진행하면 됩니다.
본론으로 돌아와서, 첫 번째 input은 227 x 227 x 3 이고 첫 번째 CONV Layer 가 96개의 11 x 11 크기의 필터, stride=4 로 적용이 되어 있습니다. 이렇게 되면 output 의 volume size 는 (227 - 11)/4 + 1 = 55이므로 55 x 55 x 96 이 됩니다.
layer 에 있는 전체 파라미터의 개수는 필터의 크기 x 필터의 크기 x depth x 필터의 개수를 하게 되어 34,848개가 됩니다.

그 다음으로 Pooling Layer 에서 output Volume size 를 구해보면 다음과 같습니다.
(55 - 3)/2 + 1 = 27이므로 27 x 27 x 96이 output size 가 됩니다.
이 때, pooling layer 에는 파라미터가 없기 때문에 해당 레이어에서는 파라미터의 개수가 0이 됩니다.
이런식으로 계속 진행되다 보면, 다음과 같이 됩니다.

각 layer의 size가 변화하는 과정을 일일히 계산을 해보는 것도 도움이 됩니다.
결과적으로 227 x 227 x 3의 이미지를 받아 1000개의 class 로 분류하는 식으로 구성이 됩니다.
1000 개 라는 것은 ImageNet 의 총 category 수가 1000개이기 때문에 그렇습니다.
참고로, 여기에 Normalization layer 가 있는데, AlexNet 당시에는 사용했지만 현재는 효용이 별로 없다고 하여 더이상 사용되지 않습니다.
또한 각 레이어를 거칠 수록 size가 점점 더 작아지는 반면에 filter의 수는 96 -> 256 -> 384 로 일반적으로 늘어난다는 것을 볼 필요가 있습니다.
FC7 Layer 는 일반적으로 통칭되는 용어로, AlexNet을 예로 들어서 Classification 을 수행하는 레이어 직전의 FC 레이어를 지칭합니다.
AlexNet 을 정리하자면 다음과 같습니다.
- Activation Function 으로
ReLU를 사용함.(모든 CONV, FC 에서 사용이 됨.) - 지금은 더 이상 사용되지 않는 Normalization Layer를 사용함.
- Data augmentataion 을 굉장히 많이 사용함.
- DropOut 을 0.5로 FC에서 사용함.
- batch size = 128
- SGD momentum = 0.8
- lr = 1e-2
- 7개의 CNN 모델 앙상블을 통해 2.8%의 top5 error rate를 줄임
따라서 2012년, ImageNet에서 AlexNet 이 우승을 하게 됩니다.
ZFNet

그리고 2013년에는 Zelier & Fergus의 ZFNet 이 우승을 하게 됩니다.
ZFNet 은 기본적으로 AlexNet과 거의 유사합니다.
AlexNet에서는 CONV1에서 11x11에 stride=4인 filter 를 사용했지만, 여기에서는 11 이 너무 크다고 판단하여 7x7에 stride=2 로 진행하였고, CONV3,4,5 에서 필터의 개수를 더욱 늘려 차이를 주었습니다. 즉, 필터의 크기는 줄이고 개수는 늘리는 방식으로 구성을 한 것입니다.
결과적으로 ImageNet에서 top5 error 는 14.8% 까지 만들었다고 합니다. 나중에 Clarif.ai 에서는 11% 까지 발전했다고 합니다.
VGGNet
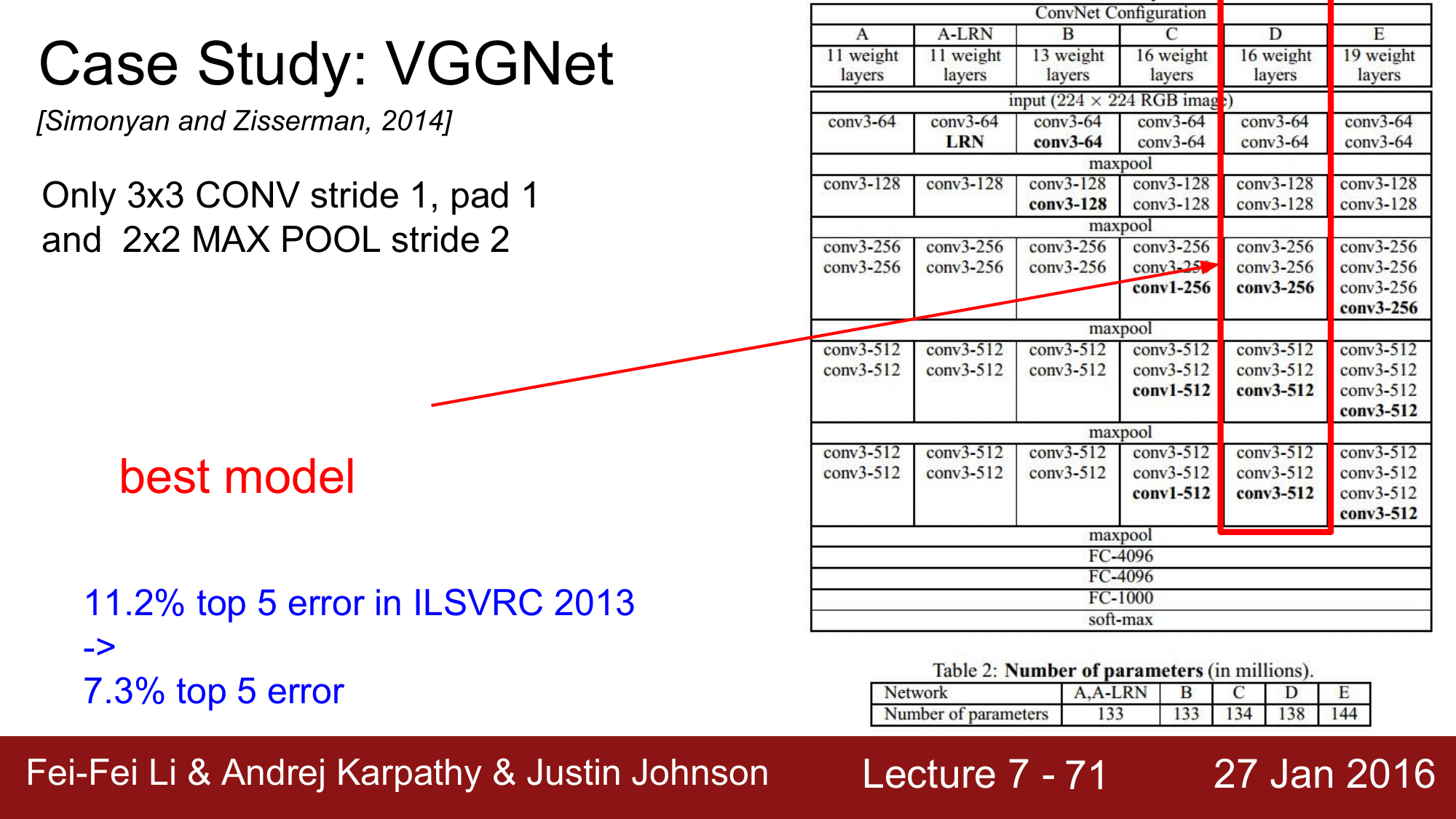
그 다음은, 2014년에 1위를 차지한 VGGNet 입니다.
기존의 AlexNet에서 CONV POOL 에서 계속해서 filter를 변경했던 것을 VGGNet 에서는 오직 CONV 에서는 3 x 3 에 stride=1, pad=1 로, POOL에서는 2 x 2에 stride=2 로 하는 필터만을 모든 레이어에 적용하였습니다. 이렇게 해서 오른쪽 그림에서 보이는 것과 같이 A to E 에서 몇개의 weight 를 가지는 모델이 최적의 구성인지를 찾아 16개의 weight layer를 가지는 configuration D 가 최적의 모델이라고 결론을 내렸습니다.
결과적으로 7.3% 까지 top 5 error 를 줄였습니다.
여기에서 사용된 총 파라미터의 개수는 1억 3천 8백만개가 되겠습니다.
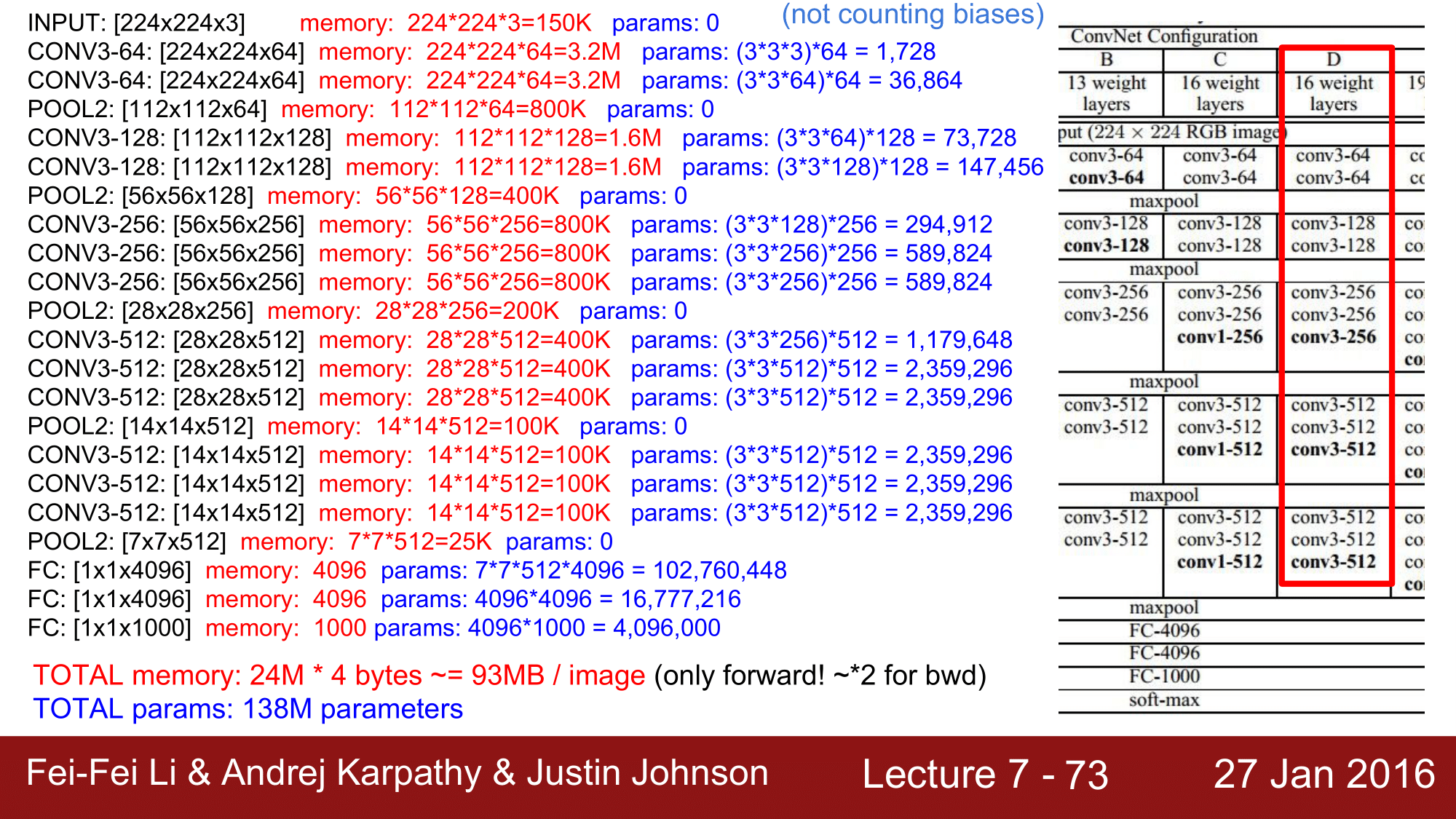
이 layer 들을 전반적으로 분석을 하게 되면, 굉장히 복잡한 것을 볼 수 있습니다.
image size는 224, 112, 56, 28, 14, 7로 계속해서 줄어드는 모습을 볼 수 있고, 반면에 필터의 개수는 64, 128, 256, 512 로 계속 늘어난다는 것을 볼 수 있습니다.
가운데에 사용된 메모리를 주목해서 보게되면, 전체를 합산해보면 약 24M 가 되고 float 이라고 한다면 4byte 이기 때문에 약 93MB 가 됩니다.

한 이미지 당 93MB를 사용한다는 것이고, 이는 forward-pass 에 대한 것이기 때문에, backward-pass 도 고려한다면, 이미지 한 장을 처리하는데 약 200MB의 메모리를 사용한다라고 보면 됩니다.
전체 파라미터는 앞에서 본 것과 같이 138M 개의 파라미터를 사용하고 있다는 것을 확인할 수 있습니다.
메모리 관점으로 다시 보게된다면, 앞쪽에서 대부분의 메모리가 소모되고 있음을 확인할 수 있고, 파라미터쪽을 보게 되면, 파라미터의 수가 점점 늘어나면서 뒤쪽의 FC 의 하나의 레이어에서 무려 1억개의 파라미터가 사용되는 것을 확인해볼 수 있습니다.
이런 이유로 FC를 이용하는 것은 효율적이지 않다라는 생각을 들게 되어 최근에는 FC 대신에 AVG Pooling 을 사용하는 연구가 많이 되고 있습니다.
7 x 7 x 512 의 volume 이 있을 때, 각 7x7 을 avg pooling 을 해줍니다. 그래서 512개의 수를 갖는 단일 column 으로 변환을 해주는 식의 avg pooling 을 진행해주게 되는데, 실제로 FC 처럼 동작을 하면서 파라미터의 수를 대폭으로 줄여주기 때문에 매우 효율적으로 동작하는 것을 확인할 수 있습니다.
이런 동작이 바로 뒤에 소개할 GoogLeNet에서도 활용이 됩니다.
GoogLeNet
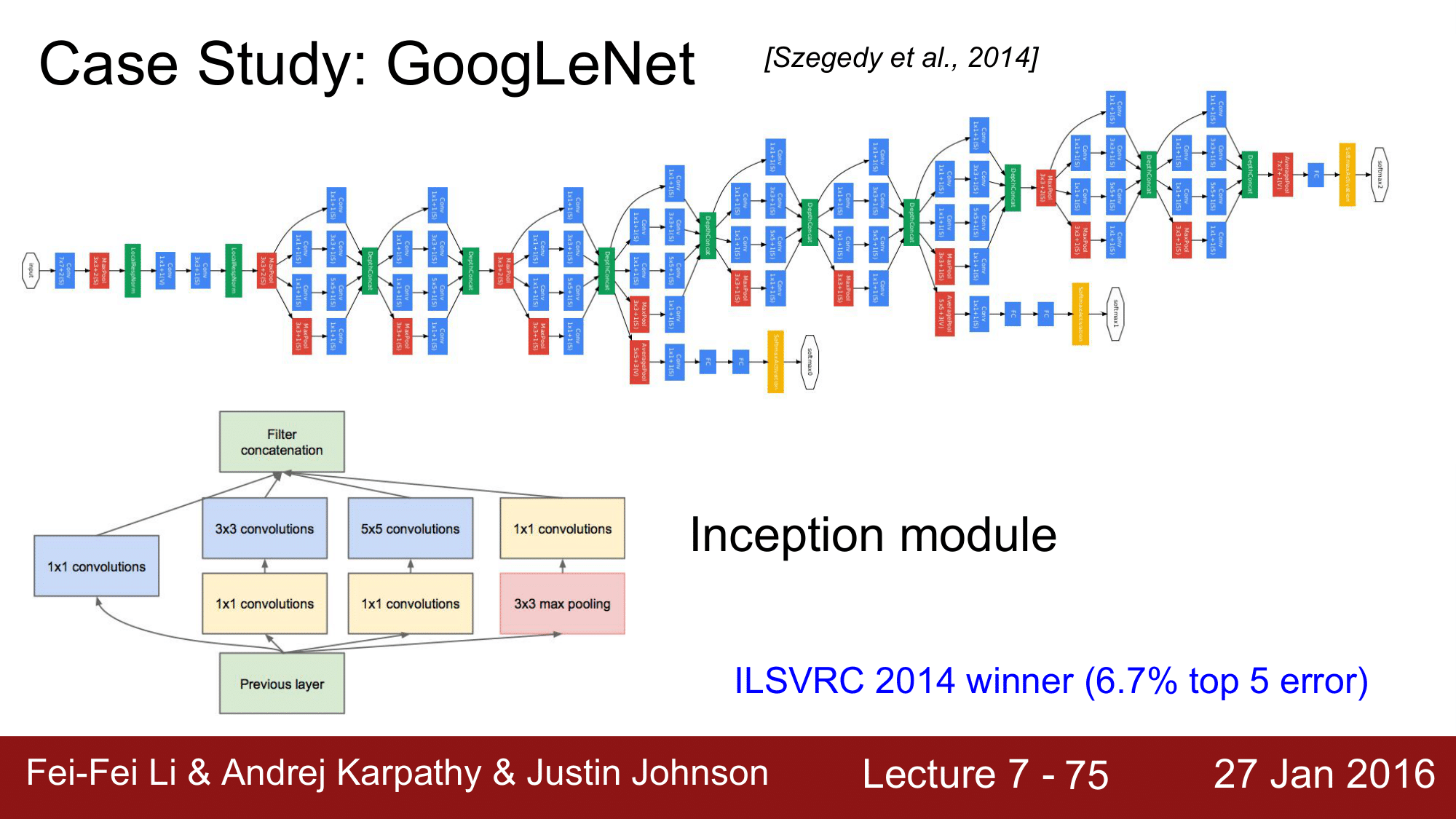
위 그림은 2014년에 우승한 GoogLeNet으로, 이 때 부터 굉장히 복잡해집니다.
기본적으로 아래 그림에 나와있는 Inception module을 연속적으로 연결하여 구성되어 있습니다.
우승 당시에 6.7%의 top5 error 를 기록했습니다.
GoogLeNet은 위와 같이 굉장히 복잡한 구조를 가져 top5 error 가 7.4% 인 VGGNet와 큰 차이가 없어서, 구조가 단순한 VGGNet 을 많은 사람들이 더 사용했었습니다.
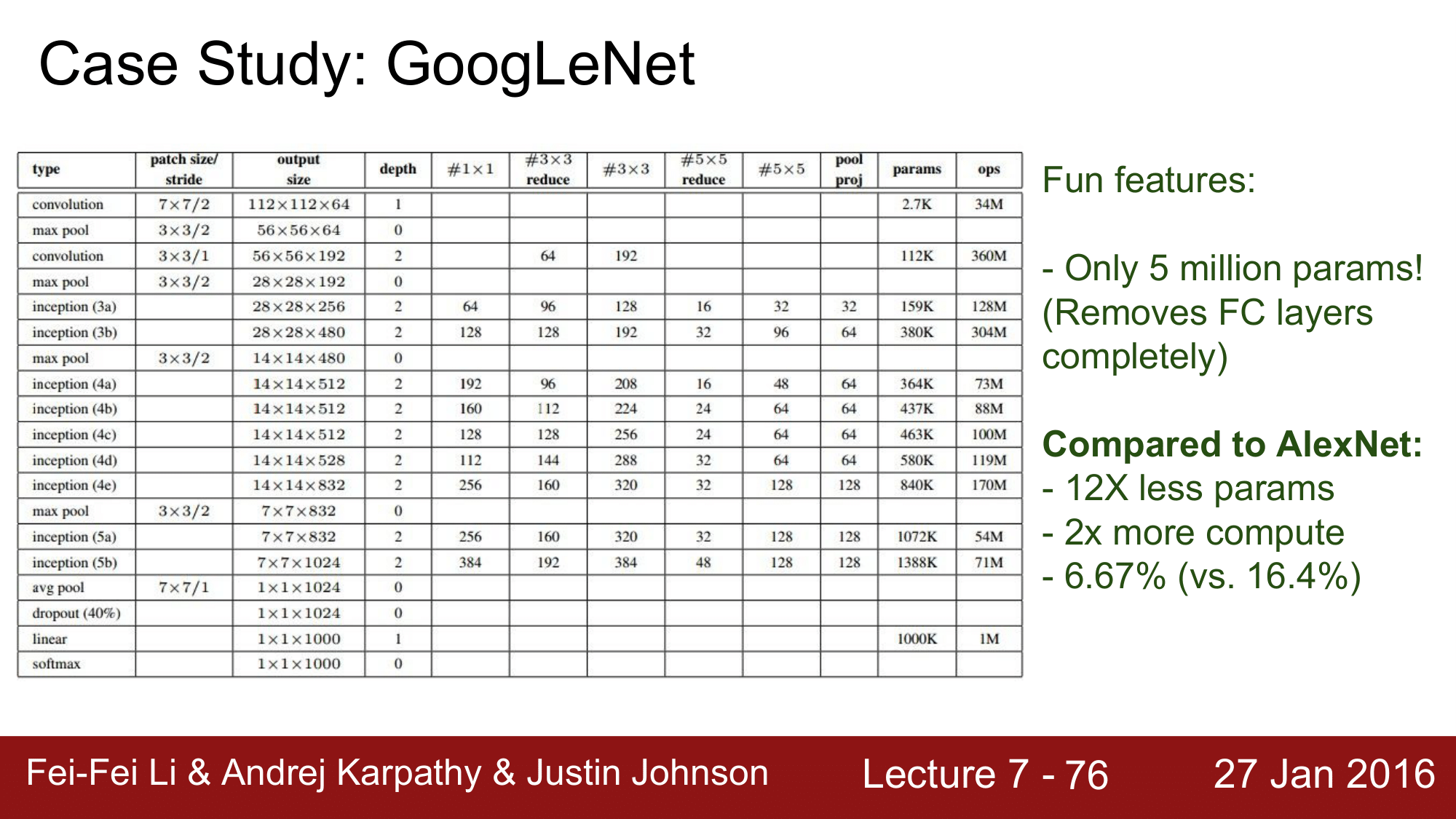
이런식으로 CONV, MAX POOL, INCEPTION 레이어들로 구성이 되는데, 여기서 가장 주목할 부분은 앞서 설명했던 AVG POOL을 FC 대신에 사용을 한 것 입니다.
7 x 7 이었던 레이어를 average pooling 을 통해 1 x 1로 줄여 하나의 단일 column 으로 만들어 파라미터의 개수를 많이 줄일 수 있게 됩니다.
전체 사용된 파라미터 개수를 보면 약 5백만개 정도로 굉장히 적은 것을 볼 수 있는데, 그 이유는 FC 레이어를 AVG POOL 로 대체 했기 때문에 그렇습니다.
파라미터 개수를 비교해보면 다음과 같습니다.
- AlexNet: 60M
- VGGNet: 138M
- GoogLeNet: 5M
결과적으로 AlexNet에 비해서 1/12 수준의 파라미터로 2배이상 빠른 연산과 약 10% 가량 error 가 줄어든 결과를 가져온 것이 GoogLeNet 입니다.
ResNet

다음으로는 2015년에 우승한 ResNet 입니다. ResNet 은 MicroSoft의 Kaiming He 가 만든 것으로 top5 error 가 3.6%로 줄였습니다.
ImageNet의 Classification 뿐만 아니라, Detection, Localization, COCO Detection, COCO Segmentation 의 모든 분야에서 1위를 차지한 Network 입니다.
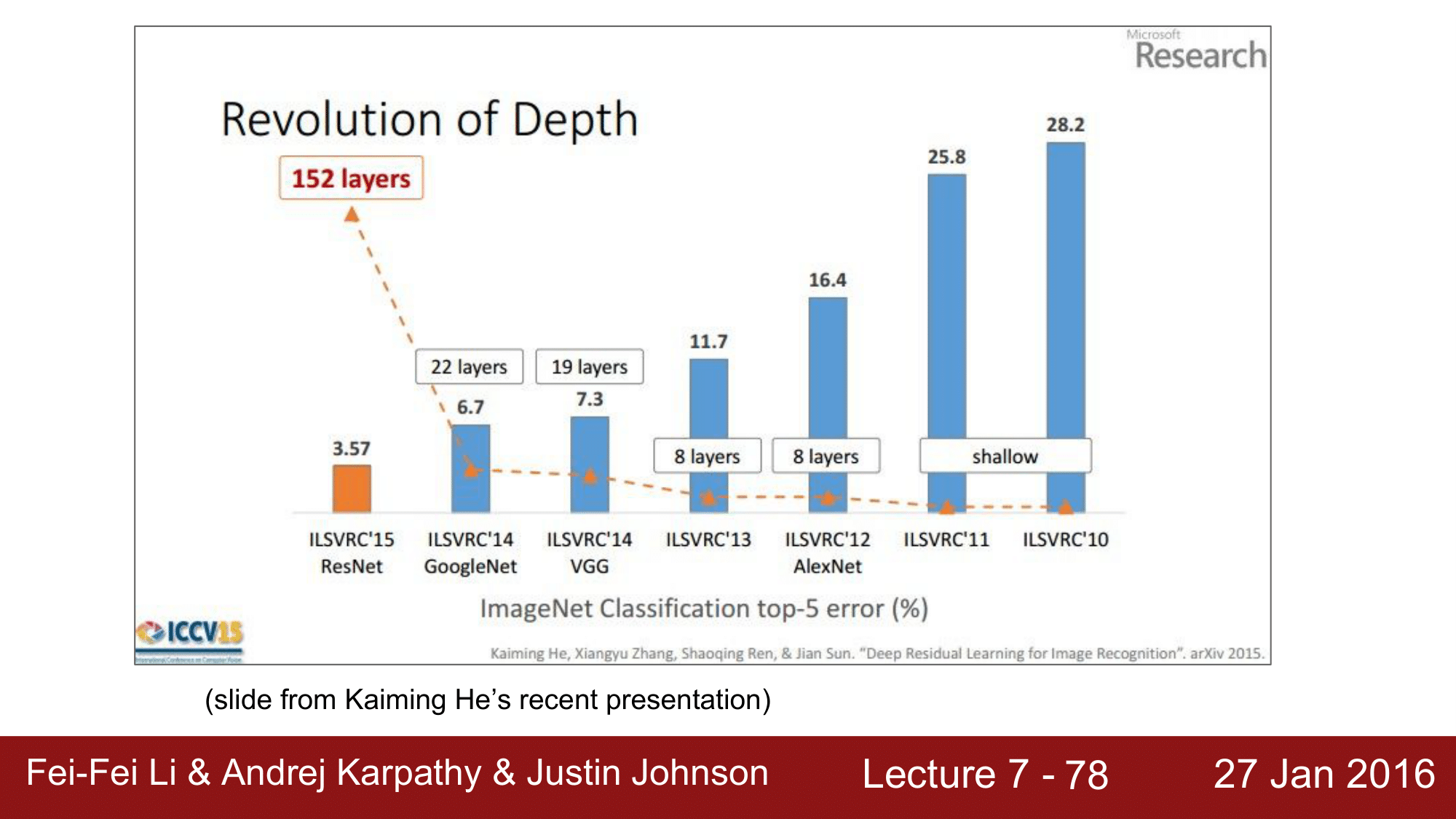
ImageNet에서 network 의 depth 의 변화를 보게되면 위와 같은데, 레이어가 늘어나면서 top5 error가 계속해서 줄어드는 것을 보실 수 있습니다.
기본적으로 레이어가 늘어날 수록 더 좋은 성능을 가져와야 되는데, 여러가지 문제들이 있었습니다.
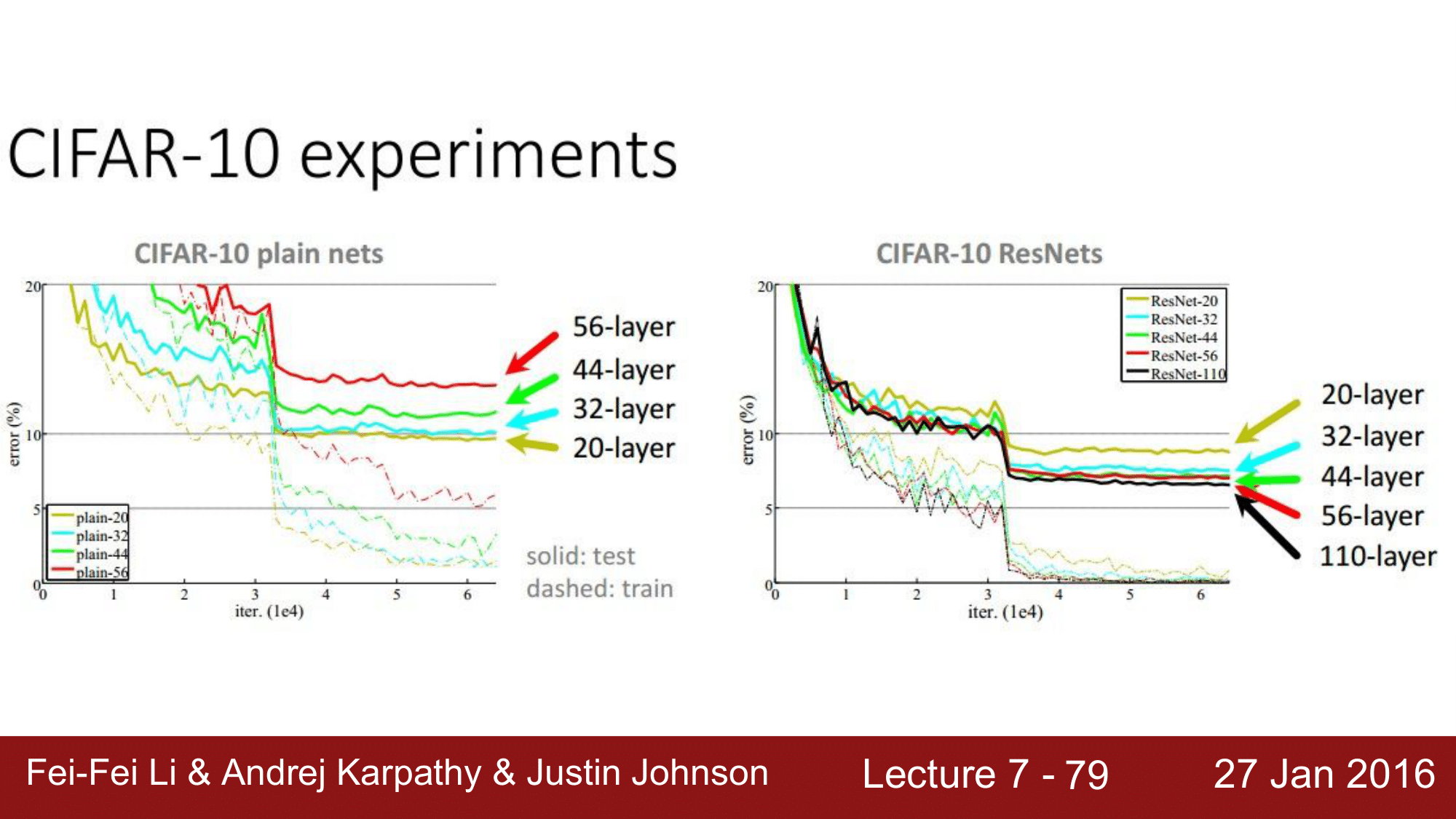
기존의 AlexNet이나 VGGNet 들 같은 경우는 왼쪽그림에서 보이는 것과 같이 layer 가 증가함에 따라 오히려 error rate 가 증가하는 모습을 보이는 것을 확인 할 수 있습니다.
즉, 왼쪽의 network 들 같은 경우는 최적화에 실패한 것들이다라고 하고 있고, ResNet의 경우에는 layer가 늘어날 수록 error rate 가 감소하는 식으로 정상적인 모습을 보이고 있음을 확인 할 수 있습니다.
따라서 ResNet의 동작방식을 따라야 한다라고 주장합니다.
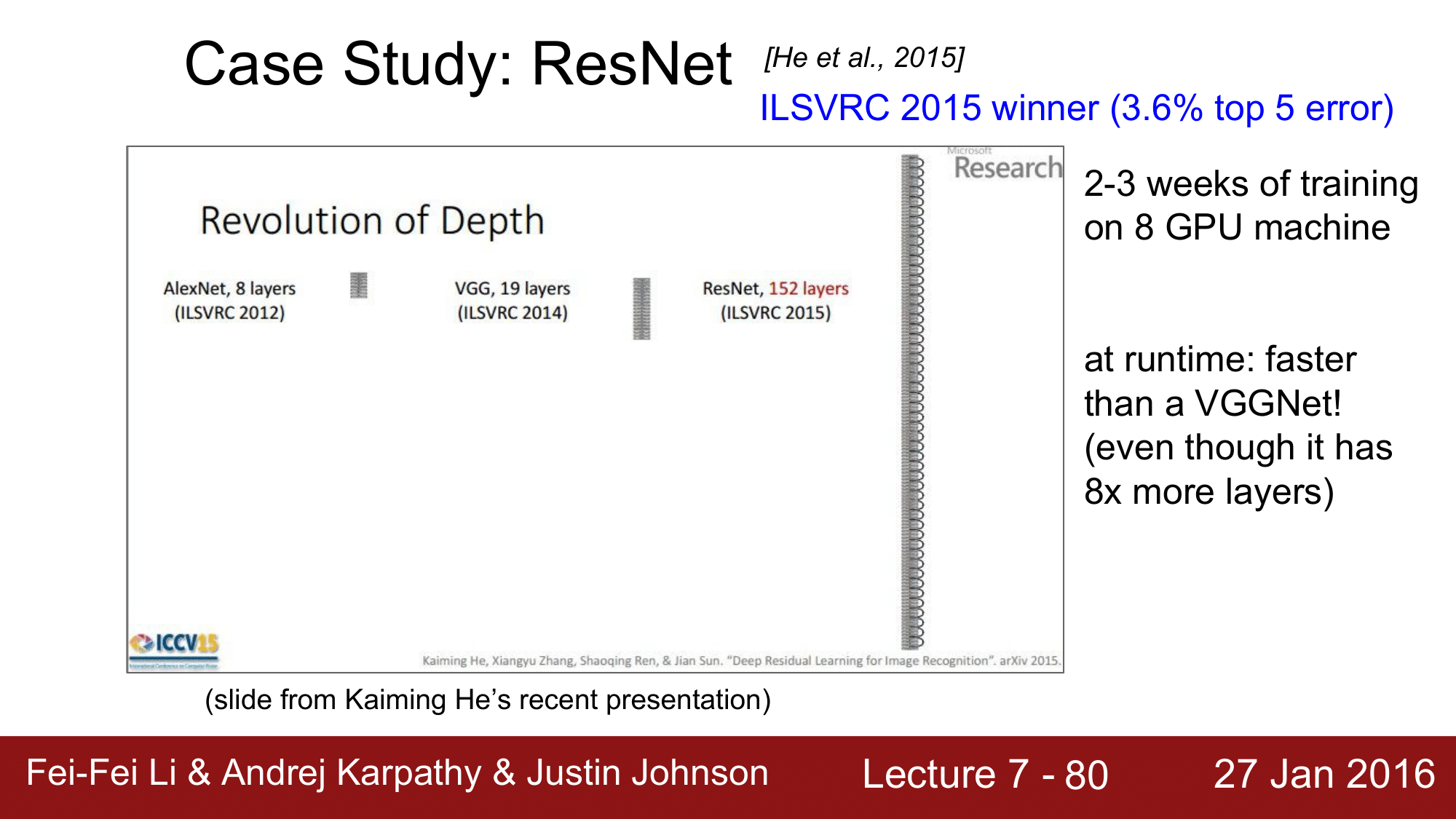
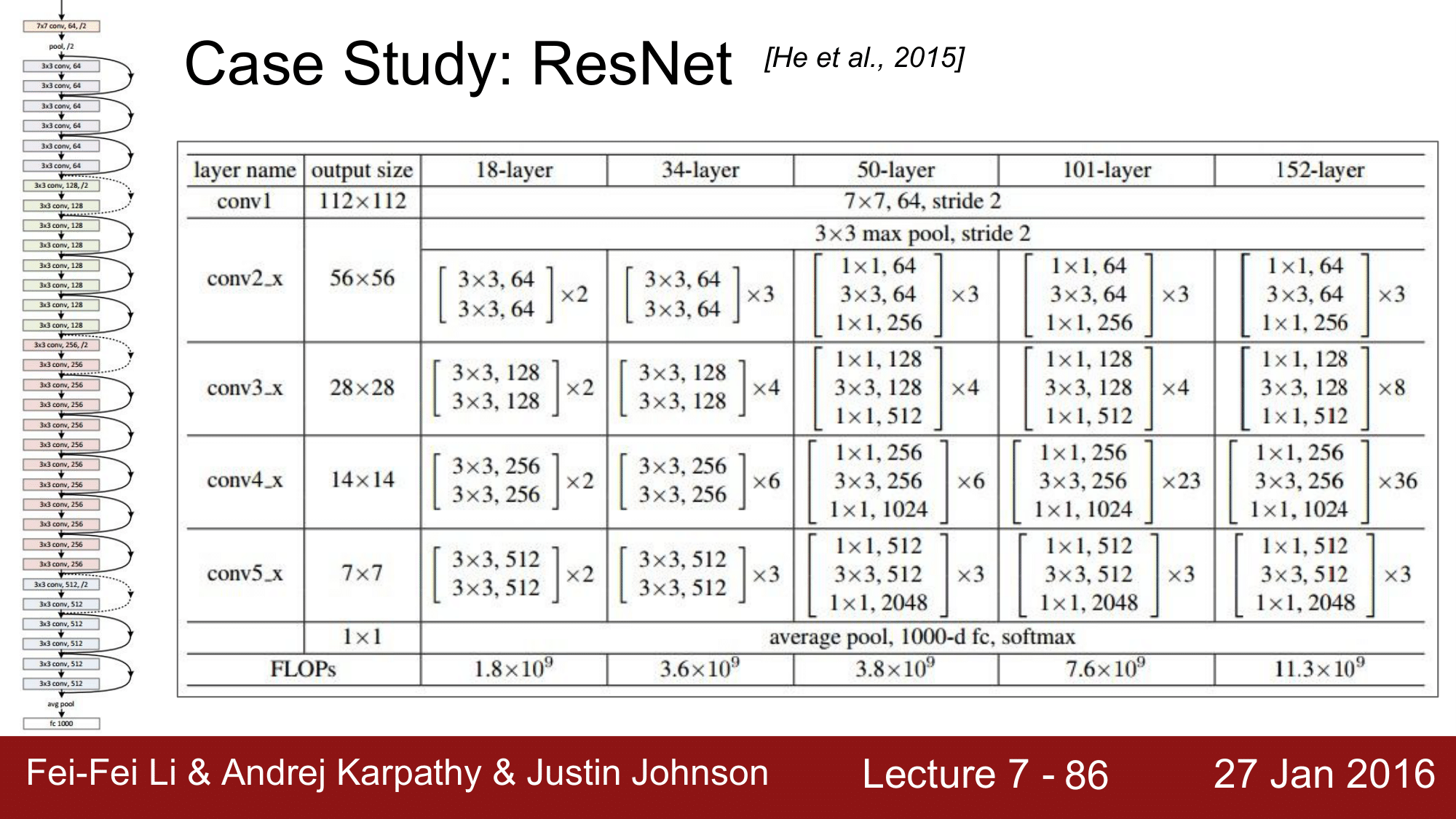
무엇보다 놀라운 점은 ResNet의 layer 개수가 152개라는 점으로 8개의 GPU Machine 으로 2-3주간 학습을 시켜야 하지만, runtime에는 VGGNet 보다 더 빠른 속도로 동작한다고 합니다.
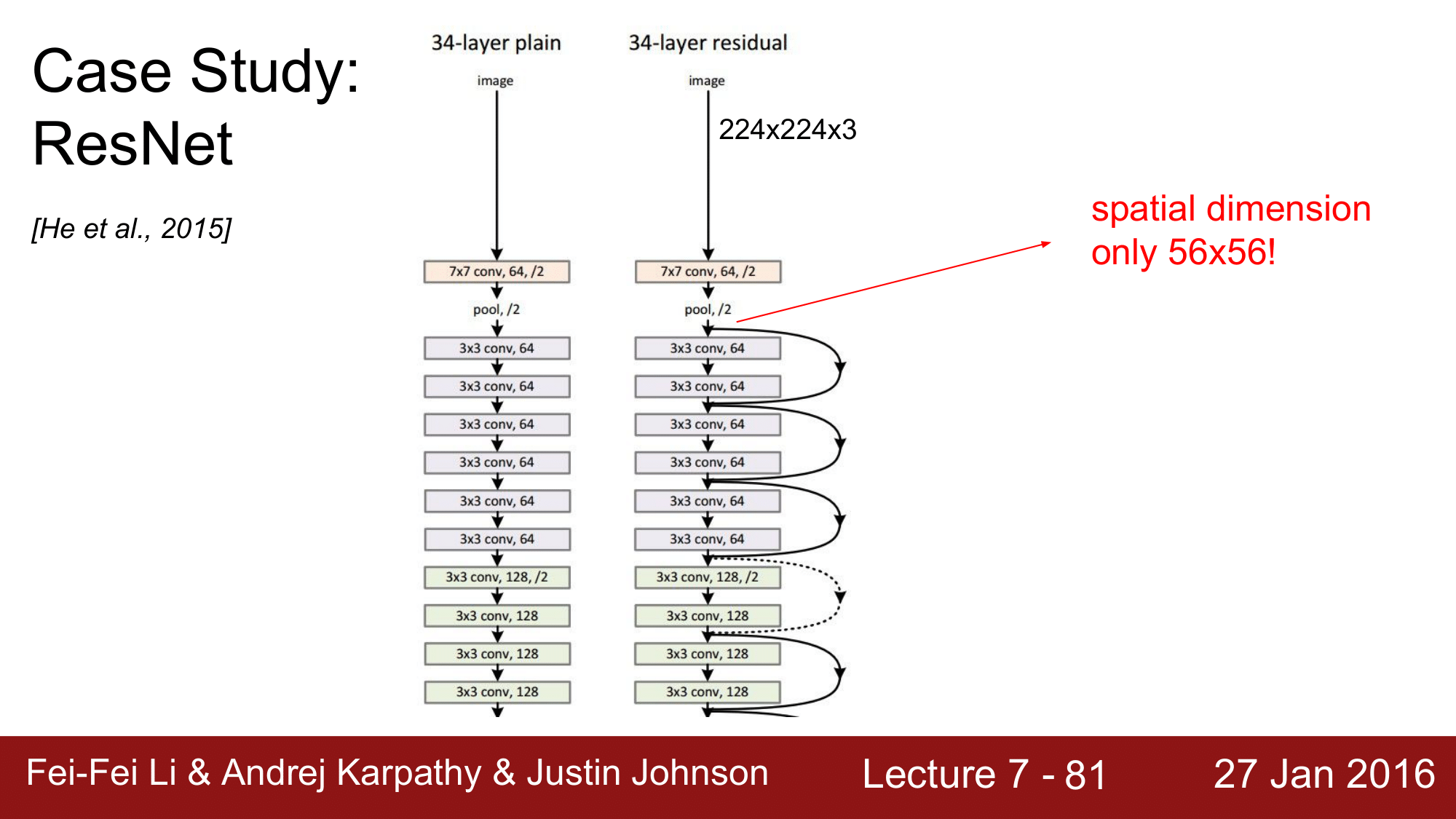
이렇게 좋은 성늘을 보이는 이유를 간단하게 살펴보자면, 먼저 CONV 를 한번 거치고 바로 다음 pooling에 들어갑니다.
이후 약 150개의 layer를 image 가 56 x 56 으로 동작하게 하는 방식으로, 초기에 size를 줄여줌으로써 효율적인 연산이 가능해지고, 또한 skip connection 하는 과정들이 들어가서 매우 효율적으로 진행됩니다.
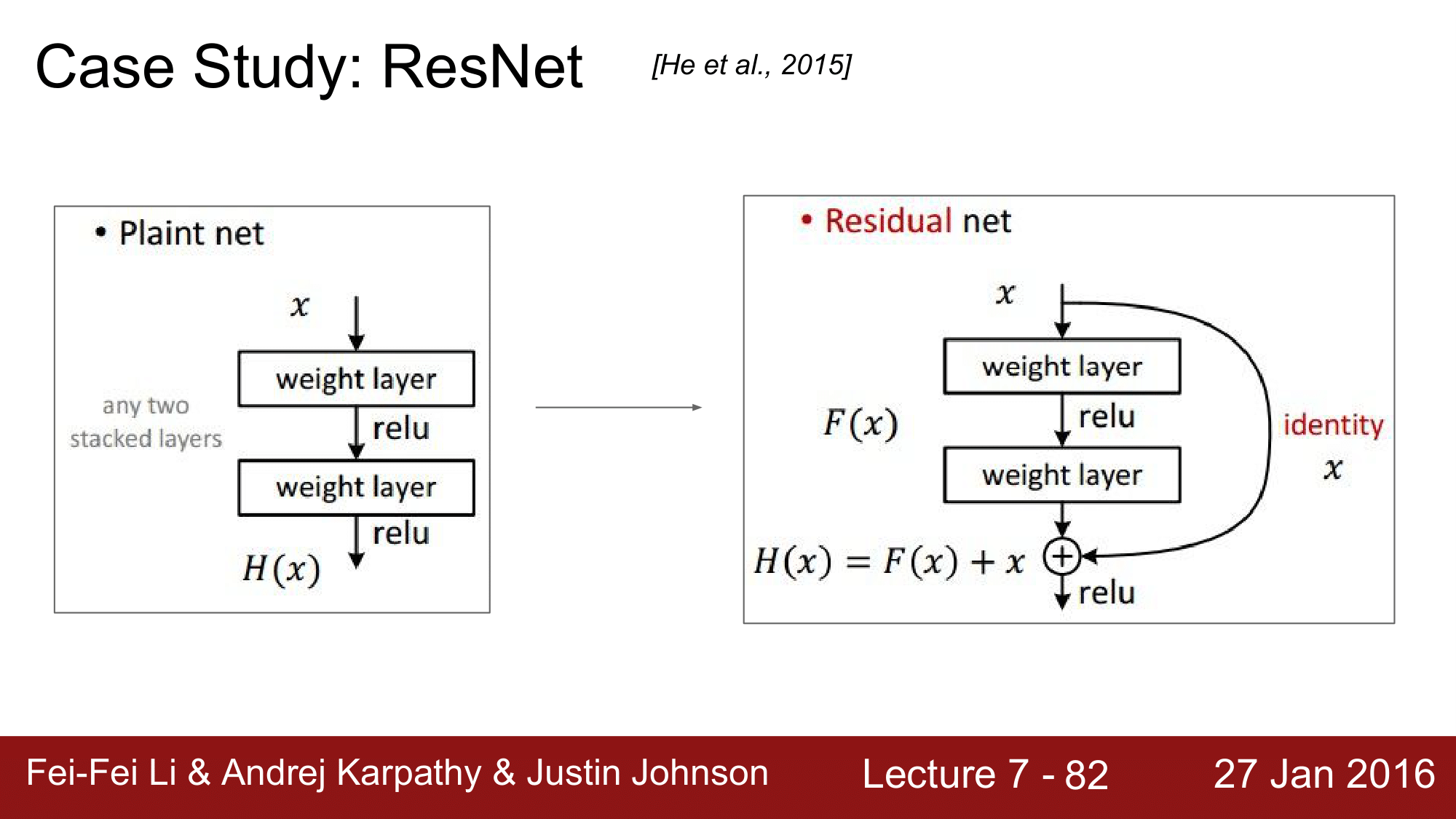
위 그림을 보게되면, ResNet 같은 경우 오른쪽 그림과 같이 Skip Connection 이 있고, 더하기 연산을 추가해줌으로써 backpropagation을 할 때, 더하기 연산이 Distributor 역할을 해서 바로 앞쪽의 CONV Layer 로 넘어갈 수 있게 합니다.
즉, 맨 뒤의 layer에서 순식간에 150개의 레이어를 건너뛰어 처음의 CONV Layer 까지 넘어갈 수 있도록 한 것입니다.

정리하면 다음과 같습니다.
- 모든 레이어에서 Batch Normalization 을 사용함.
- Kaiming He 자신이 만든 Xavier Initialization을 사용함.
- 배치 정규화를 사용했기 때문에 lr=0.1로 AlexNet의 1e-2와 비교됨.
- 에러 정체시에 lr 을 10으로 나눠 줌.
- 배치 정규화를 사용했기 때문에 드롭아웃을 사용하지 않음.
Batch Normalization 논문에 의하면, 배치 정규화를 사용하게 되면 드롭아웃을 사용할 필요가 없다는 식을 나와있는데 이를 따른 것으로 보이는 것을 확인할 수 있습니다.
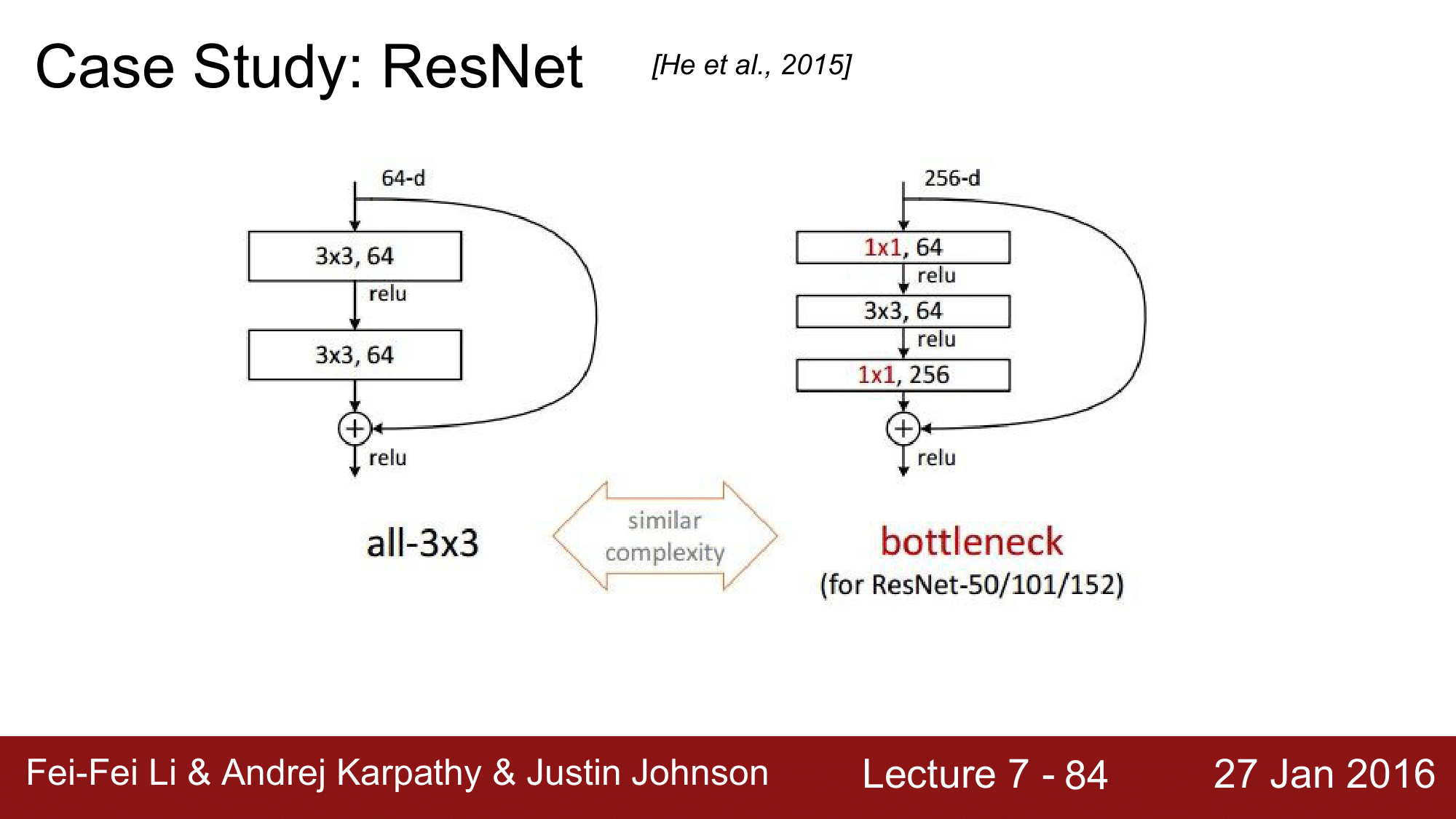
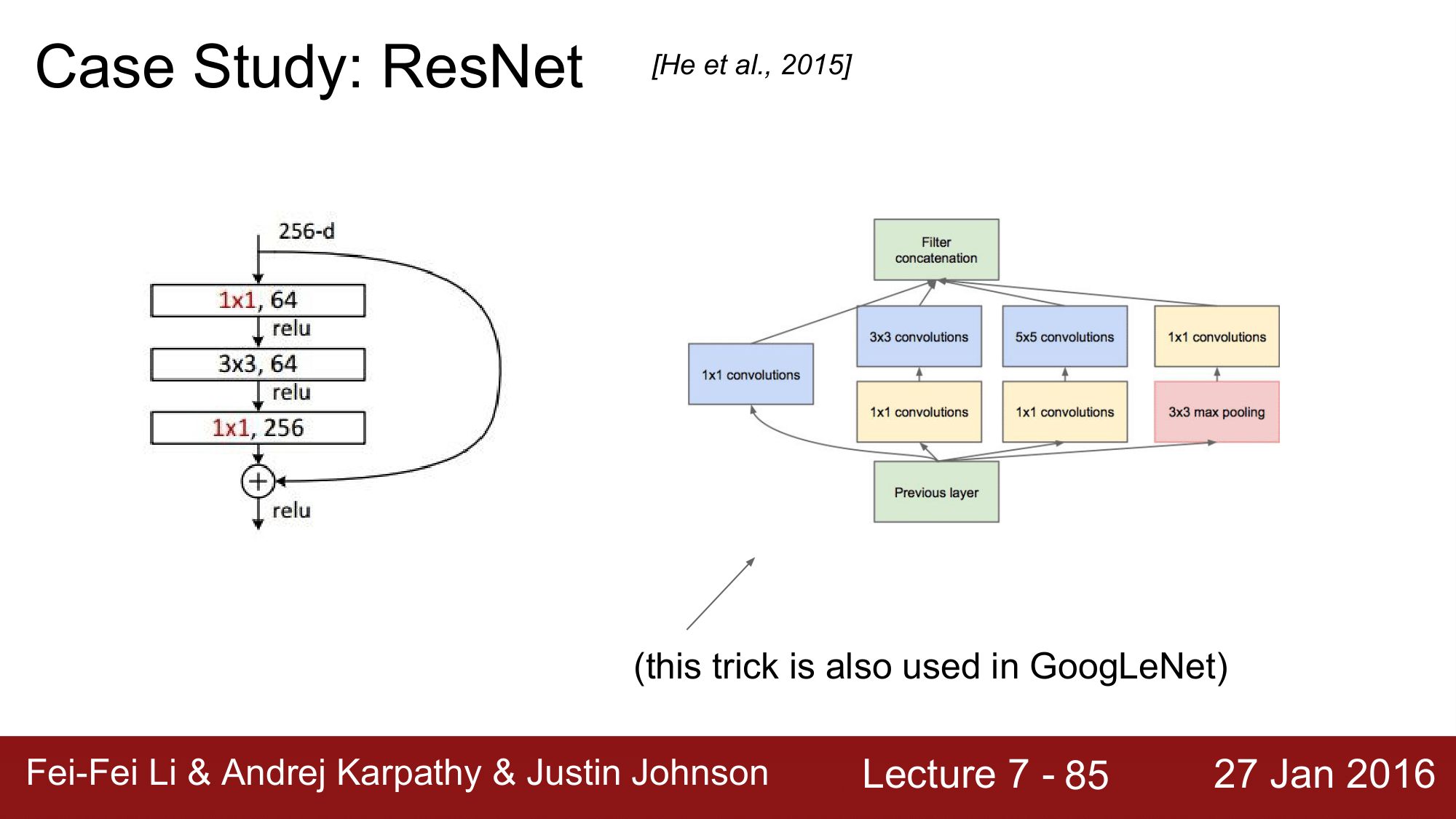
1x1 CONV 를 사용했고, GoogLeNet에서도 이를 사용한 것을 볼 수 있습니다.
Deep Mind’s Alpha Go

이 강의가 진행이 될 때 알파고에 대한 논문이 Nature 에 소개가 되었습니다.

실제로, 위와 같은 내용으로 기재되었습니다.
우리가 공부한 것을 바탕으로 다음과 같이 이해해 볼 수 있습니다.
19 x 19의 반상이 있고 48개의 feature(전략?) 이 있다고 하여 input을 19 x 19 x 48 로 구성하여 CONV 레이어를 통과하여 최종적으로는 19 x 19의 자리에서 어디에 두어야 하는 지를 확률로 표현한 map 을 제시하는 식으로 구성됩니다.
19 x 19라는 size 를 CONV 에서 $P = \frac{(F - 1)}{2}$ 를 이용해 계속 보존하면서 진행하는 것 입니다.
Summary

여기까지 해서 CNN 에 대해서 살펴보았습니다.
최근의 트렌드는 작은 필터를 사용하고, 점점 더 깊은 구조를 사용하는 방향으로 가고 있고, 또한 POOL/FC 를 점차 사용하지 않고 CONV 만 사용하여 stride 를 이용해서 spatial reduction 을 하는 방향으로 가고 있는 것이라고 합니다.
전통적인 architecture 는 위의 bold 된 것과 같이 구성이 되는데, 최근에는 CONV 만을 사용한다는 것 입니다.