
해당 포스트는 송교석 님의 유튜브 강의를 정리한 내용입니다. 강의 영상은 여기에서 보실 수 있습니다.
우선 지난 포스트에서 설명한 내용을 간단하게 살펴보겠습니다.
Mini-batch SGD
Mini-batch SGD는 위와 같은 순서대로 진행됩니다. 먼저 미니배치의 데이터를 샘플링하고, 그 데이터들을 forward pass를 함으로써 loss를 구하고 back propagation을 통해 gradient를 구한 다음에, 해당 기울기를 가지고 파라미터들을 업데이트 해주는 과정을 거칩니다.
Activation Functions

SGD 외에도 다양한 활성화 함수들이 있는 것을 설명했습니다. 이러한 활성화 함수들을 왜 사용해야 하는 지에 대해 궁금할 수 있는데, 이에 대한 설명은 다음과 같습니다.
Neural Network 에서 활성화 함수가 없으면, 이 Neural Network가 몇개의 layer를 가지든지 간에, 단일의 Linear 한 함수로 표현이 가능해지기 때문입니다.
예를 들어, $y = ax$ 라는 함수를 활성화 함수로 사용한다고 가정해봅시다. 이렇게 했을 때, 2계층에서는 $y = a(ax)$가 되고, 3계층에서는 $y = a(a(ax))$ 가 됩니다. 이렇게 되면 결국 3계층의 network 는 $y = a^3x$로 표현이 가능해져서 레이어를 여러개를 두는 의미가 없어집니다. 이는 은닉계층이 없는 단일 네트워크와 동일해진다는 것입니다.
결국 활성화 함수를 사용하지 않으면 Neural Network의 Capacity가 하나의 Linear Classifier 수준이 되어버리기 때문에, 활성화 함수를 사용해서 미세한 변화를 만들어주는 것이 중요하다는 것을 알고 넘어가면 됩니다.
Data preprocessing
데이터 전처리 관련해서는 zero centered 한다고 간단히 언급했습니다.
Weight Initialization
weight가 너무 작은 경우에는 activation이 0이 되버린다는 것이고, weight 가 너무 큰 경우에는 explosion, super saturation이 일어난다는 것.
tanh 함수의 경우 Xavier initialization, Relu의 경우는 분모를 np.sqrt(fan_in)으로 나누어서 사용하면 좋은 결과를 얻을 수 있다는 것에 대해서도 공부했었습니다.
TODO
- Parameter update schemes
- Learning rate schedules
- Dropout
- Gradient checking
- Model ensembles
1. 파라미터 업데이트(Parameter Updates)

우리가 신경망을 training 시킬 떄는 위와 같은 과정을 거치게 됩니다. 지금은 단순한 gradient descent를 이용해서 업데이트를 하고 있는데, 이 부분을 좀 더 다양하게 살펴보겠습니다.
SGD 가 느린 이유
우선 SGD를 다시 한번 보겠습니다.
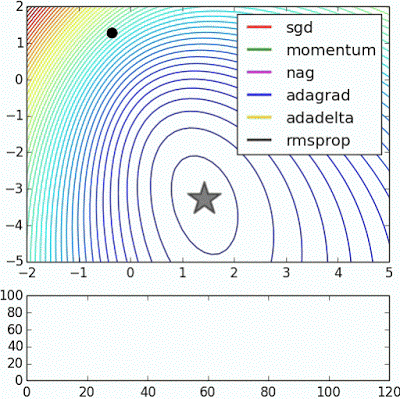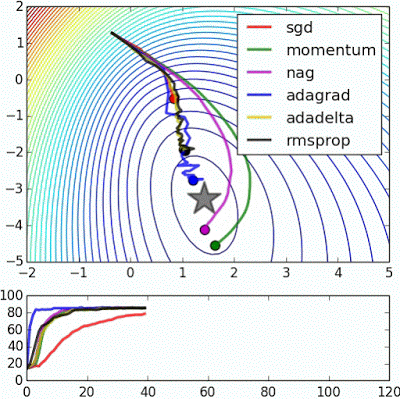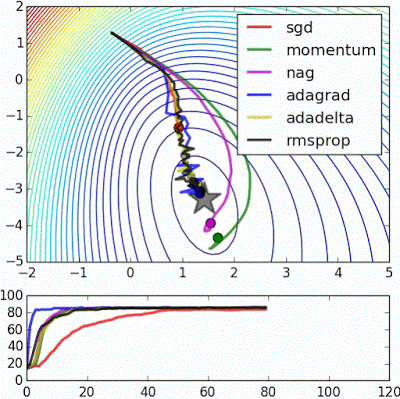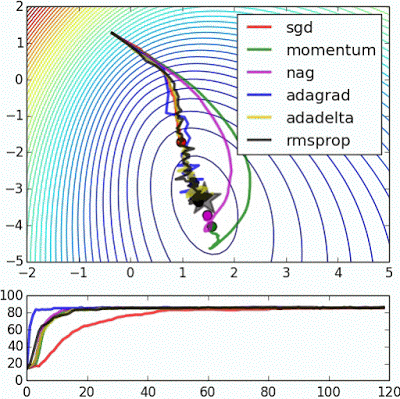
위 이미지를 보게 되면 SGD의 경우 가장 느리게 목표지점에 도달하는 것을 볼 수 있습니다. 때문에 실제 상황에서는 사용하기가 매우 꺼려지는 업데이트 방법이 됩니다.
그렇다면 이 SGD는 왜 이렇게 느린지 한번 알아보겠습니다.
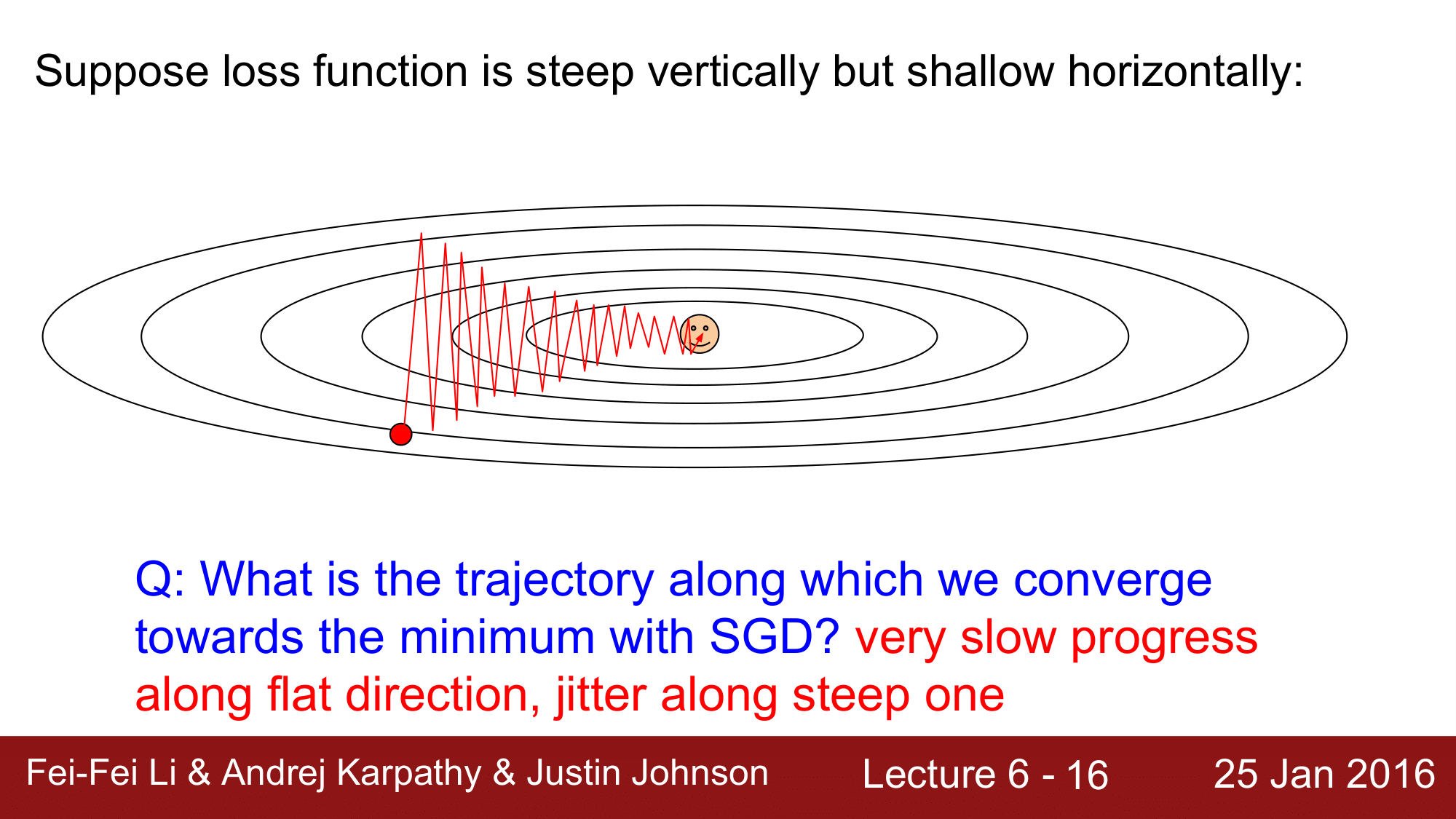
SGD를 진행하게 되면 빨간 점에서 happy point 즉 loss 가 최소가 되는 지점을 향해 움직이게 되는데, 이때 경사가 수직으로는 경사가 깊고 수평으로는 경사가 얕은 것을 볼 수 있습니다.
따라서 해당 지점에서의 벡터를 그려 진행방향을 파악하게 되면 위 그림과 같이 지그재그로 이동하게 됩니다. 이렇게 되면 매우 느리게 진행하게 됩니다. 이렇게 느리게 진행되는 것을 방지하는 방법들에 대해서 지금보터 알아보겠습니다.
Momentum update
첫번째로 살펴볼 방법은 Momentum update방법입니다.

# Gradient descent update
x += - learning_rate * dx
SGD에서는 x 의 위치를 아래와 같이 직접 업데이트를 합니다.
# Momentum update
v = mu * v - learning_rate * dx # integrate velocity
x += v # integrate position
그런데 모멘텀 업데이트에서는 v라는 변수를 도입합니다. 여기서 v는 속도(velocity)를 의미하고, 해당 v를 통해 x를 업데이트 하게 되는 것입니다.
이 방식은 마치 언덕에서 공을 굴리는 상황을 연상하면 되는데, 이때 gradient는 공이 느끼는 힘(force)이 됩니다.
F = ma 이기 때문에, 공이 느끼는 힘(F)는 가속도에 비례하게 되어 결국 가속도를 계산하는 것과 마찬가지가 됩니다.
이떄 위 식에 있는 마찰계수 mu 로 인해 속도가 점차 느려지는 식으로 진행이 됩니다.
mu 라는 것은 보통 0.5, 0.9, 0.99 와 같은 단일 수치로 설정을 해주는 것이 일반적이고, 때에 따라서는 0.5 에서 0.99로 점점 증가하도록 사용을 하기도 합니다.

그래서 SGD 와는 다르게 경사가 낮은 지점에서는 속도가 천천히 build-up 이 되고, 경사가 높은 지점에서는 속도가 더 빠르게 증가하는 식으로 진행이 됩니다.
공이 위에서 내려가면서 속도가 점차 증가해서 반대편 지점에 다다르고, 마치 추가 움직이듯이 되돌아가면서 종점에 도달하게 되는 것 입니다.
위와 같은 방식을 이용해서 convergence를 촉진하게 됩니다.
SGD vs Momentum
모멘텀(녹색)을 보게 되면, velocity 가 build-up 이 되기 때문에, 다른 방식들과는 다르게 처음에 빠르게 튀어 나갑니다. 즉, overshooting 이 일어납니다.
오버슈팅이 발생하긴 하지만, 결과적으로는 SGD 보다 더 빠르게 minimum 지점에 도달하는 것을 볼 수 있습니다.
Nesterov Momentum update

다음으로, 모멘텀의 변형인 Nesterov Momentum update(e.g. 다른말로 NAG(Nesterov Accelerated Gradient)) 에 대해 살펴보겠습니다.
NAG 는 모멘텀보다 항상 convergence rate 가 더 좋다는 것이 이론적으로 증명이 되어 있고 실제로도 그렇습니다.
그 이유는 다음과 같습니다.
일반적으로 모멘텀은 momentum step(mu * v) 과 gradient step(learning_rate * dx) 으로 나누어져 있습니다.
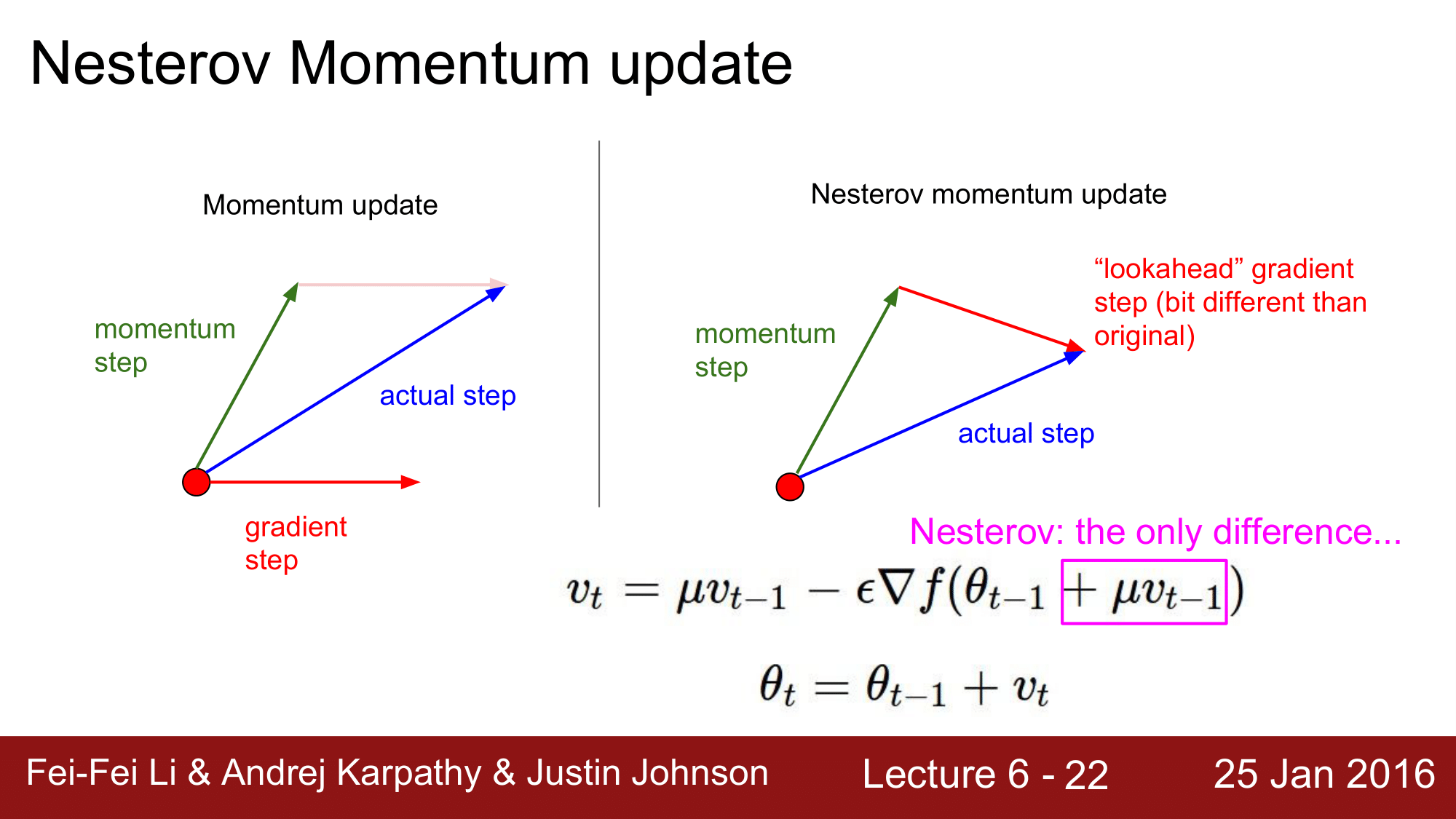
그런데, NAG 에서는 momentum step 의 진행방향은 이미 알고 있는 것이기 때문에, gradient step을 빨간 점에서 취하지 않고, momentum step 의 종점에서 취하게 됩니다.
이렇게 하면, gradient step의 시점이 바뀌기 때문에 해당 백터가 바라보는 방향도 바뀌게 됩니다.
이를 정리하게 되면, gradient step을 계산하기 전에 momentum step을 미리 고려해서, 시작점을 momentum step의 종점으로 변경한 다음에 gradient step을 evaluate 하는 방식으로 진행한다고 할 수 있습니다.
이를 식으로 살펴보게 되면 다음과 같습니다. \(v_t = \mu v_{t-1} - \epsilon\nabla f(\theta_{t-1} + \mu v_{t-1}) \\ \theta_t = \theta_{t-1} + v_t\)
여기서 모멘텀과 다른 점은 $+ \mu v_{t-1}$ 부분으로, momentum step 을 미리 예상을 해서 shift 한 상태에서 gradient를 구해줍니다.
그런데 이렇게 하면 불편한 점이 있습니다.

forward-pass 나 backward-pass 하는 과정에서 파라미터$\theta$ 와 그 위치에서의 기울기$\nabla f(\theta_{t-1})$ 를 구하게 되는 건데, NAG 에서는 $\theta$ 와 다른 위치의 gradient 를 요구한다는 것 입니다. 이렇게 되면, 우리가 일반적으로 학습을 진행할 때 사용하는 코드들과는 호환성이 떨어지는 문제가 생기게 됩니다.
따라서 식을 약간 수정을 해줘야 합니다.
$\phi_{t-1} = \theta_{t-1} + \mu v_{t-1}$ 을 이용해 식을 치환하게 되면 다음 처럼 정리할 수 있습니다.
\[\begin{matrix} \phi_{t-1} &=& \theta_{t-1} + \mu v_{t-1}\\ \theta_t &=& \theta_{t-1} + v_t\\ \phi_t &=& \theta_t + \mu v_t\\ \end{matrix}\] \[\phi_t - \mu v_t = \phi_{t-1} - \mu v_{t-1} + v_t \\ \phi_t = \phi_{t-1} - \mu v_{t-1} + (1 + \mu) v_t\]이렇게 식을 수정하게 되면, 오른쪽 코드와 같이 일반 적인 형태로 값을 update 할 수 있게 됩니다.
다시 위 그림을 보게 되면, nag 의 경우 방향을 예측해서 진행하기 때문에 momentum 에 비해 더 빠르게 convergence 하는 것 을 볼 수 있습니다.
다음으로 살펴볼 내용은 AdaGrad update 입니다.

AdaGrad 는 convex optimization 에서 개발되어 neural network 으로 porting 이 된 개념입니다.
위의 식을 보시게 되면 cache 라는 개념을 도입합니다. learning_rate * dx 부분을 보게 되면 일반적인 SGD 의 update 방법인데, 빨간 박스 안의 식에서 cache에 루트를 씌운것으로 나눠주는 것에 차이가 있다는 것을 볼 수 있습니다.
여기서 cache 는 무조건 양수이고, 계속해서 증가하고, 우리가 가지고 있는 파라미터 벡터와 동일한 사이즈를 갖는 거대한 백터라고 생각하면 됩니다.
이런 cache로 값을 나눠주며 업데이트 하는 방법. 즉, 모든 파라미터들이 동일한 learning rate 을 적용받는 것이 아니라, cache라는 변수를 통해 각각의 파라미터들이 모두 다른 learning rate 를 적용받게 하는 방법을 per-parameter adaptive learning rate method라고 합니다.
1e-7는 Divide zero 를 방지하기 위한 상수

이렇게 AdaGrad 를 사용하게 되면, 수직방향으로는 gradient 가 크기 때문에 cache의 값도 커지게 되어 분모가 커지게 됩니다. 이는 x의 업데이트 속도가 줄어든다는 것입니다.
반대로 수평방향으로는 gradient 가 작아 cache도 작아지고 분모도 작아지게 됩니다. 이렇게 되면 x 의 업데이트 속도가 빨라지게 됩니다.
다시 말헤, 기울기가 큰 수직방향으로는 업데이트를 줄여주고, 기울기가 작은 수평방향으로는 업데이트를 빠르게 해줌으로써 equalize 해주는 effect, 경사에 경도되지 않는 효과를 가져오게 됩니다.
하지만 AdaGrad도 문제점이 있습니다.
시간이 흐르게 되면 cache 값은 building up 이 되고 결국 learning rate 가 0 에 매우 가까운 값이 됩니다. 즉 학습이 종료가 되게 됩니다.
처음에 AdaGrad가 고안됐던 convex problem에서는 optimum 지점까지만 가면 되니까 문제가 아니었습니다만, Neural Net 에서는 학습이 종료되는 문제가 생기게 됩니다. 따라서 학습이 종료되지 않기 위한 에너지를 제공해줘야 하는데, 이렇게 에너지를 제공하는 방식으로 문제점을 개선한 것이 다음으로 소개할 RMSProp 이 되겠습니다.
RMSProp update

RMSProp에서는 decay_rate이라는 개념을 도입합니다.
decay_rate은 하나의 하이퍼파라미터로 일반적으로 0.9, 0.99 와 같은 값으로 설정이 됩니다.
cache 를 구할 때, gradient 제곱의 합을 구하는 것은 동일한데, decay_rate이라는 것을 도입함으로써 cache의 값이 서서히 leaking 하도록 합니다.
이렇게 하여 AdaGrad의 장점인 경사에 경도되지 않는 효과는 그대로 유지하면서, AdaGrad의 단점이었던 step size 가 0이 되어 학습이 종료되는 문제점을 해결한 것입니다.
여기서 파란색이 adagrad 검은색이 rmsprop으로 다른 방법들보다 빠르게 진행이 되는 것을 볼 수 있고, 또한 adagrad가 rmsprop보다 빠르게 진행되는 것을 볼 수 있습니다. 하지만 일반적인 경우 adagrad는 step size 가 0 이 되어 버리는 문제점을 갖고 있기 떄문에 학습이 조기 종료되는 경우가 보통이고, rmsprop이 조금더 빨리 끝까지 학습을 하는 것이 일반적이라고 할 수 있습니다.
Adam update
다음으로 소개할 update 방법은 Adam update로 RMSProp과 Momemtum을 결합한 형태입니다.

위 그림에서 초록색 부분은 momentum과 유사한 형태를 가지고 있고, 빨간색 부분은 RMSProp과 유사한 모습을 가지고 있습니다.
모멘텀은 앞에서 보았듯이 v = mu * v - learning_rate * dx의 형태 였기 떄문에 초록색과 굉장히 유사하고, RMSProp 부분도 원래 식과 비교해 봤을 때 dx 가 m으로 바뀐 것 정도의 차이가 있음을 확인할 수 있습니다.
원래의 RMSProp 에서는 현재의 gradient 인 dx를 사용했는데, Adam 에서는 이 dx를 전 단계 gradient 의 decay 하는 sum 을 구해준 것(m)으로 대체 해 준 것 입니다.
여기서 beta1, beta2는 하이퍼 파라미터로, 0.9, 0.99 와 같은 값으로 설정합니다.
앞에서 살펴본 Adam은 완전한 형태가 아닙니다. 최종적인 형태는 다음과 같습니다.

여기서 추가가 된 것은 bias correction 부분입니다. 이 bias correction 부분은 최초의 m과 v가 0으로 초기화 되었을 떄, 해당 값들을 scale up 해주는 역할을 합니다.
최적의 학습률(Best learning rate)
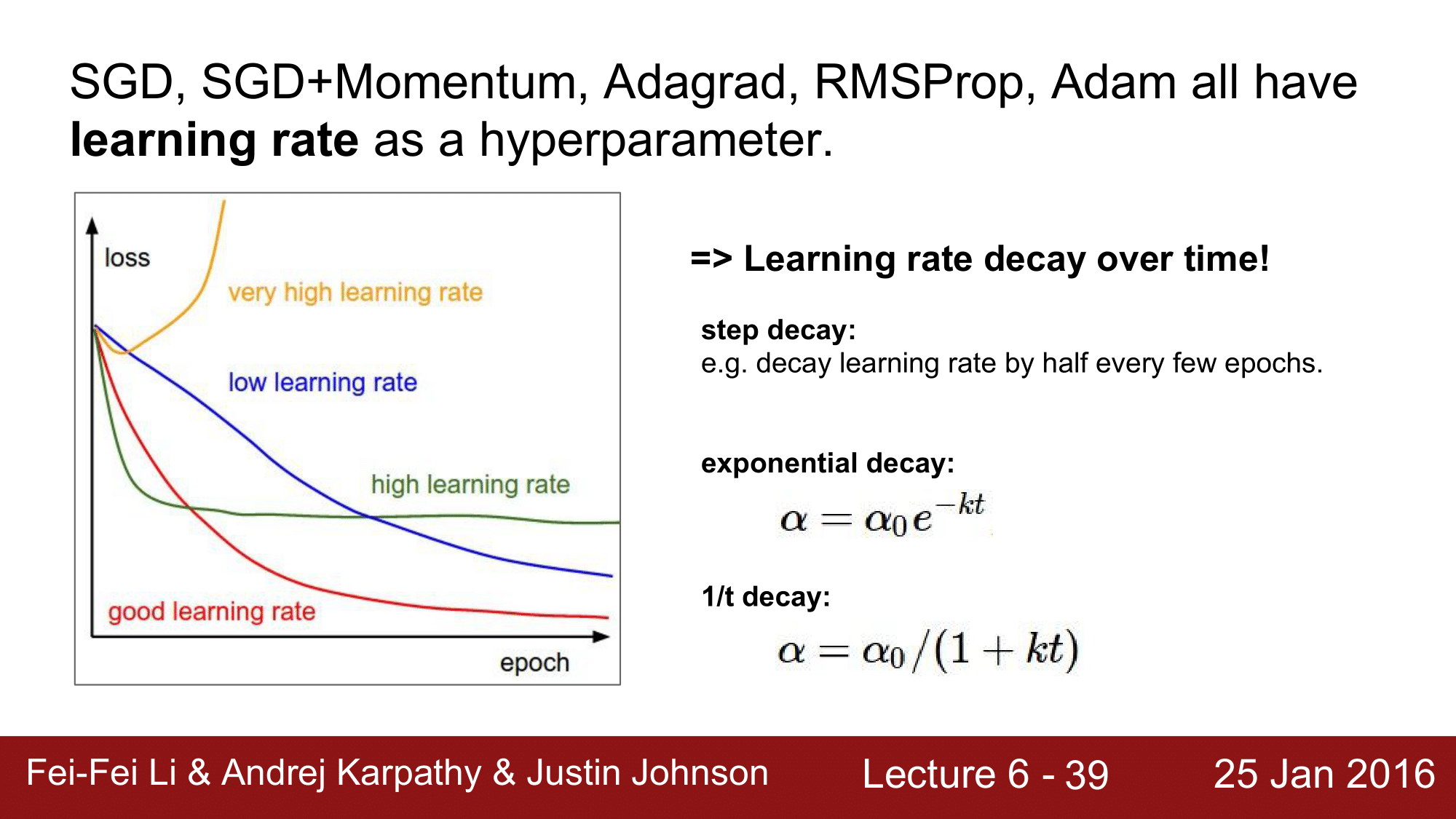
지금까지 SGD, Momentum, Adagrad, RMSProp, Adam 과 같은 update 방법들에 대해 알아보았는데 이들은 모두 learning rate 라는 하이퍼파라미터를 갖고 있습니다. 이때 learning rate 를 정할 떄 어떤 값으로 하는 것이 최적이라고 할 수 있을까요?
learning rate 은 시간의 경과에 따라 decay 시키는 것이 가장 최적입니다.
다시 말해, 초기에는 빠르게 convergence 하기 때문에 다소 큰 learning rate을 적용하고, 서서히 learning rate을 decay 시켜주면서 적용을 하는 것이 가장 최선이라는 것입니다.
이렇게 decay 시키는 방법에는 3가지 방법이 있습니다.
먼저, 가장 간단한 step decay 입니다.
step decay는 에폭을 돌 때마다 learning rate 을 일정한 간격으로 감소시켜주는 방식입니다. 예를 들어, 0.5 나 0.1 만큼 감소시켜 줍니다.
참고로, 에폭(epoch) 이라는 것은 training set의 모든 데이터들을 한바퀴 돌아 학습을 시키는 것을 에폭이라고 합니다.
step decay 외에 exponential decay와 1/t decay가 있는데, 현실적으로 exponential decay가 많이 사용된다고 합니다.
그리고 지금까지 살펴보았던 많은 방법들 중에서 Adam을 선택을 하는 것이 최근의 추이(2016년도 기준)입니다.
지금까지 SGD, Momenum, Adagrad, RMSProp, Adam 에 대해서 살펴보았는데, 이것들은 사실 1st order optimization method로 loss function을 구할 때 gradient 만 사용하는 것을 뜻합니다.
그래서 다음으로 2nd order optimization method에 대해 살펴보겠습니다.
Second order optimization method

지금까지 1st order method에서 gradient를 가지고 경사를 알 수 있었습니다. 그런데 이 2nd order method에서는 $H$(Hessian) 이라는 것을 도입해서, 경사 뿐만이 아니라 이 곡면이 어떻게 구성되어 있는 지를 알 수 있습니다. 곡면의 구성을 알 수 있으면 학습할 필요도 없이 바로 최저점으로 진행할 수 있게 됩니다.
이렇게 되면, learning rate 를 통해 단계적으로 진행하는 것이 아니기 때문에 learnin rate 도 필요가 없게 됩니다.
그래서 2nd order method를 사용하게 되면 장점은 convergence 가 매우 빨라지고, learning rate 와 같은 하이퍼파라미터가 필요가 없다는 것입니다.
하지만 사실 이런 2nd order optimization method는 우리가 사용하는 Neural Net 특히, 매우 Deep 한 Neural Net 에서는 현실적으로 거의 사용이 불가능 합니다.
왜냐하면 파라미터를 1억개를 갖는 neural net 이라고 한다면 $H$는 1억 x 1억 의 행렬아라는 엄청나게 큰 행렬을 가지게 되고, 이를 Inverse 해야 합니다(역행렬). 그래서 이 연산은 상상할 수 없을 정도로 크기 때문에 이를 실질적으로 실행이 불가능한 상황입니다.
그럼에도 불구하고, 다른 접근 방법을 통해 이를 사용해보고자 하는 방법들이 있어서 그 방법들에 대해 한번 알아보겠습니다.
BGFS 와 L-BFGS

BGFS 에서는 $H$를 inverse 하는 대신에 rank 1의 $H$을 inverse 하여 연산의 상당부분을 줄여주는 방식으로 접근합니다. 하지만 여전히 메모리에 저장하기 때문에 결국 큰 네트워크에서는 동작하기가 사실 어렵습니다.
다른 방법으로, L-BFGS 가 있습니다. 이는 Limited BGFS라는 것으로 메모리에 저장을 하지 않아서 가끔 사용이 되긴합니다.
L-BFGS(Limited memory BFGS)

기본적으로 L-BGFS 는 매우 무거운 function 으로, 이를 이용할 때는 모든 소스의 노이즈를 제거하고 사용해야 합니다.
일반적으로 full-batch 일 때는 잘 동작합니다. 하지만 일반적으로 사용하는 mini-batch 환경에서는 잘 동작하지 않습니다. 이 떄문에, 아직도 다양한 연구가 진행되고 있는 분야입니다.
Summary

정리하자면, 대부분의 경우 Adam을 사용하고 풀 배치를 사용할 수 있는 경우 L-BGFS도 시도해 볼 수 있다라고 보면 될 것 같습니다.
2. Evaluation: Model Encsembles

다음으로 앙상블에 대해 간단히 살펴보겠습니다.
먼저, 단일 모델 학습 대신 복수의 독립적인 모델을 학습시킵니다.
그 다음, 테스트 시간에 이들 결과에 평균 결과를 사용합니다.
이렇게 하면 성능이 2% 가량 향상되는 결과를 얻을 수 있다는 것 입니다.
이는 거의 항상 성능향상을 기대할 수 있다는 거라 항상 사용하면 좋다는 것인데, 다음과 같은 단점들이 존재합니다.
학습 시에 여러개의 모델 관리해야되는 이슈와, 테스트 대상이 많아 Linear 하게 테스트 속도가 느려지는 이슈가 있습니다.
이렇게 앙상블은 기본적으로 다른 모델들을 평균을 내는 방식으로 이를 이용한 몇가지 재미있는 방법들이 존재합니다.
Fun Tips/Tricks (1)

첫번째 방법은, 여러개의 모델이 아닌 단일 모델 내에서 체크포인트를 만드는 방법으로, 한 에폭을 돌 때 마다 체크포인트를 생성하도록 한 다음 체크포인트 간의 앙상블하는 것으로 성능향상을 기대할 수 있습니다.
Fun Tips/Tricks (2)

다른 방법으로, 파라미터 백터들간의 앙상블을 하는 방법입니다. x_test라는 것을 도입해서 기존에 가지고 있던 x_test에 0.995 를 곱해주고, 이번에 새로 업데이트 한 x에 0.005를 곱해주는 방식으로 계속 앙상블을 시키는 식으로 진행합니다. 이렇게 하는 것 만으로도 성능향상에 도움을 준다는 것 입니다.
어떤 Bawl Function 을 최적화하려고 할때, minium point 로 이동하는 과정에서 step size가 커서 계속해서 해당 point를 지나치는 경우가 있을 때, 이 step 들을 하나 하나 average 를 하게 되면 minimum에 가장 가까운 값을 얻을 수 있을 것이다 라는 식으로 비유를 하면서 앙상블이 효과가 있다는 것을 설명합니다.
3. Regularization (Dropout)
이번에는 드롭아웃에 대해 알아 봅니다.
Dropout 은 Regularize 를 하는 목적으로도 자주 사용됩니다. 매우 간단하면서도 항상 성능을 높히는 역할을 하기 떄문에 매우 중요한 내용입니다.
최근에 배치정규화를 사용할때 드롭아웃을 사용하지 않기도 하지만 알아 두는 것이 좋습니다.
Concept
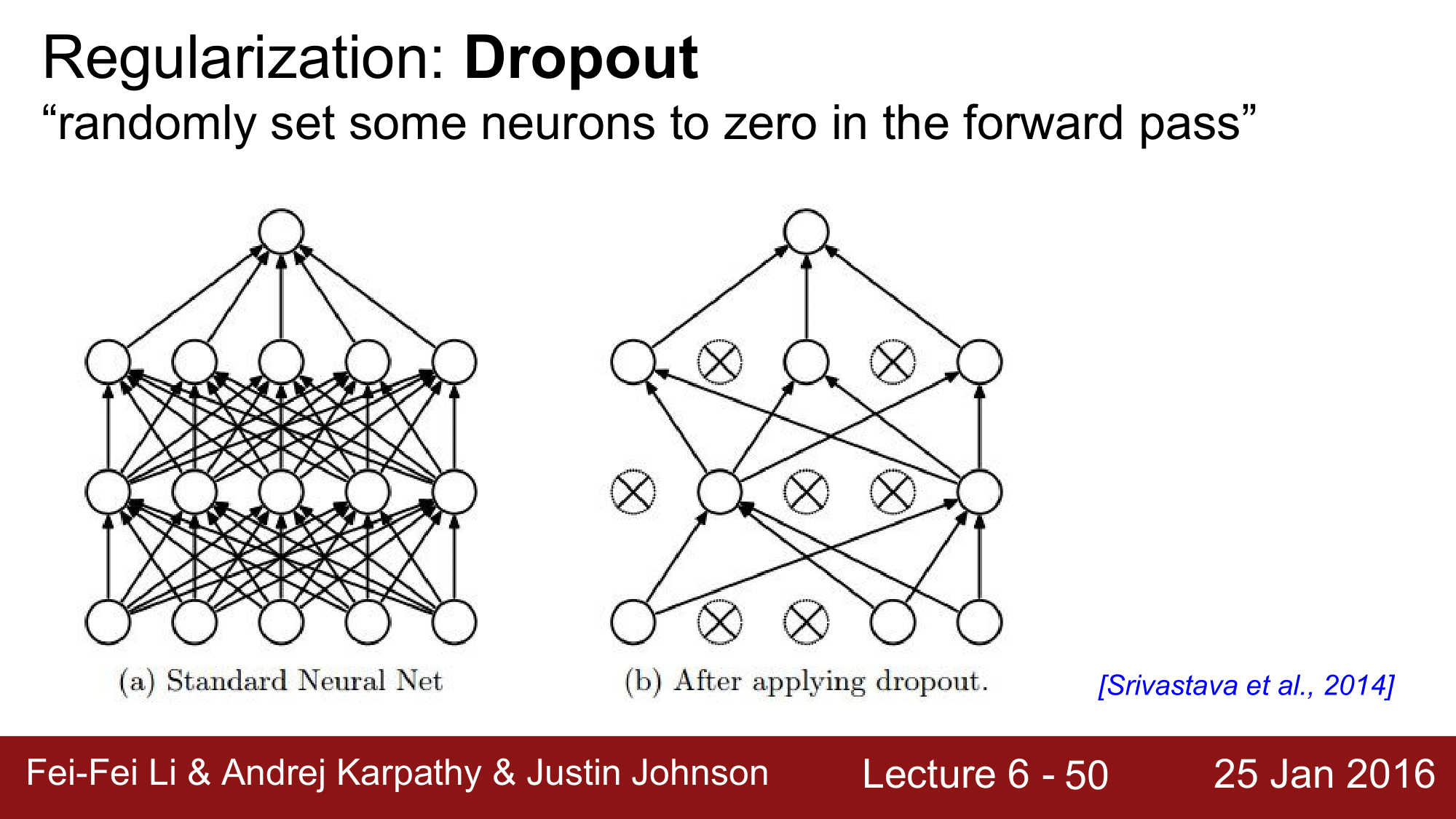
드롭아웃은 왼쪽의 Fully Connected Neural Network 애서 일부 노드들을 랜덤하게 0으로 설정합니다.
이렇게 하면 오른쪽 그림처럼 연결이 끊긴거나 다름없는 상태가 되어버립니다. 노드의 연결이 0 이 되면 해당 노드로는 forward pass 가 일어나지 않는 상황일어나게 됩니다.
코드를 보면 다음과 같습니다.
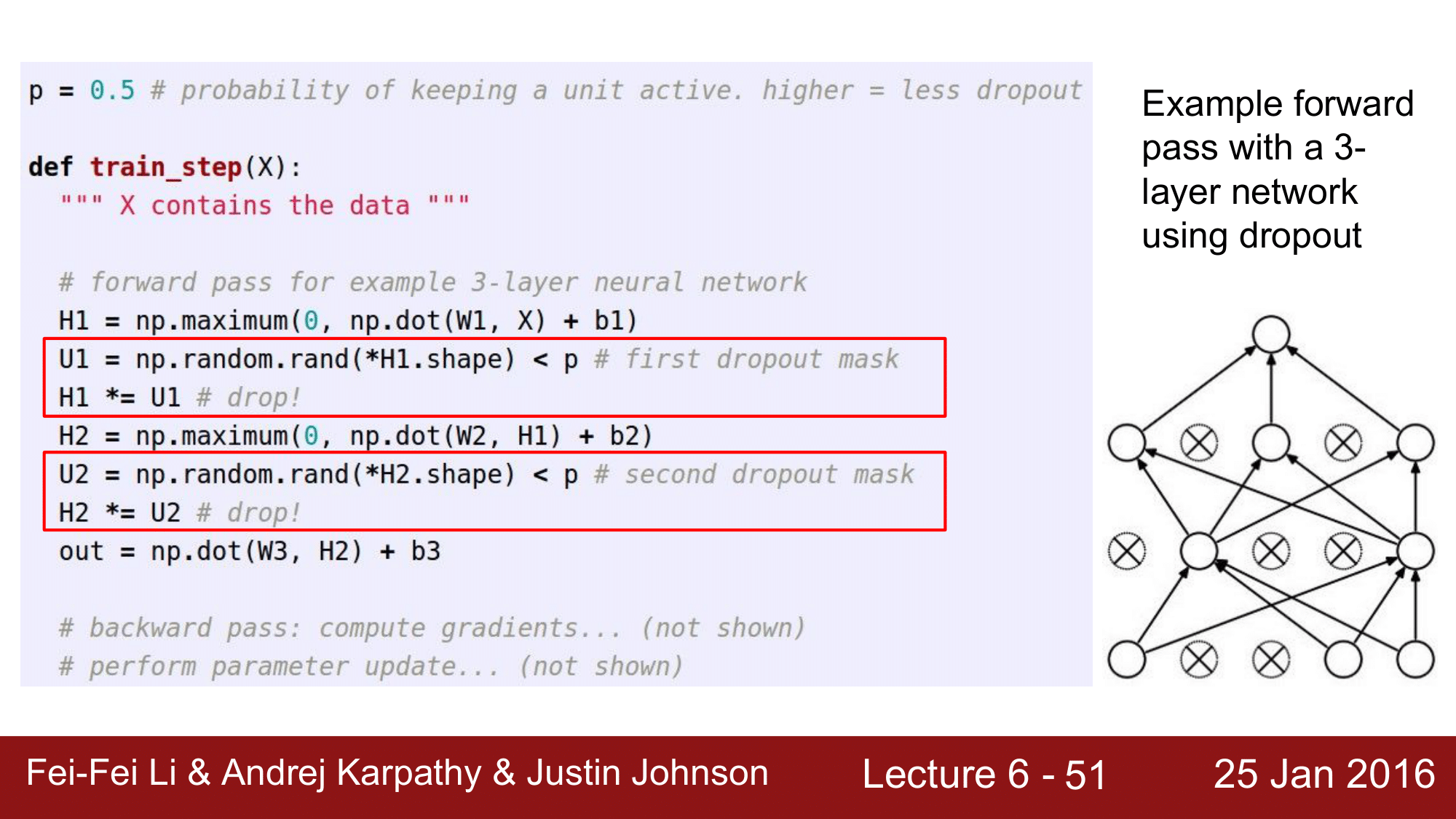
위 코드에서는, dropout 의 확률 p를 0.5로 설정을 했고, U1, U2에서 binary mask 역할을 하는 np.array를 설정해주어 H1, H2에서 마스킹된 노드들을 drop 해줍니다.
*(asterisk)는 튜플을 unpack 하기 위해서 사용함.
backward pass 때에도 dropout mask를 사용해서 dropout를 적용시킵니다. dropout이 된 노드에서는 gradient 가 죽어버리는 효과가 나타나게 됩니다. 당연히 dropout 된 노드는 loss function 에 아무런 영향을 주지 못하고 weight 값들이 없데이트 되지 않는 결과를 얻게 됩니다.
neuron drop 외에도 connect drop 방법도 존재합니다.
Dropout 사용에 대한 직관적인 해석
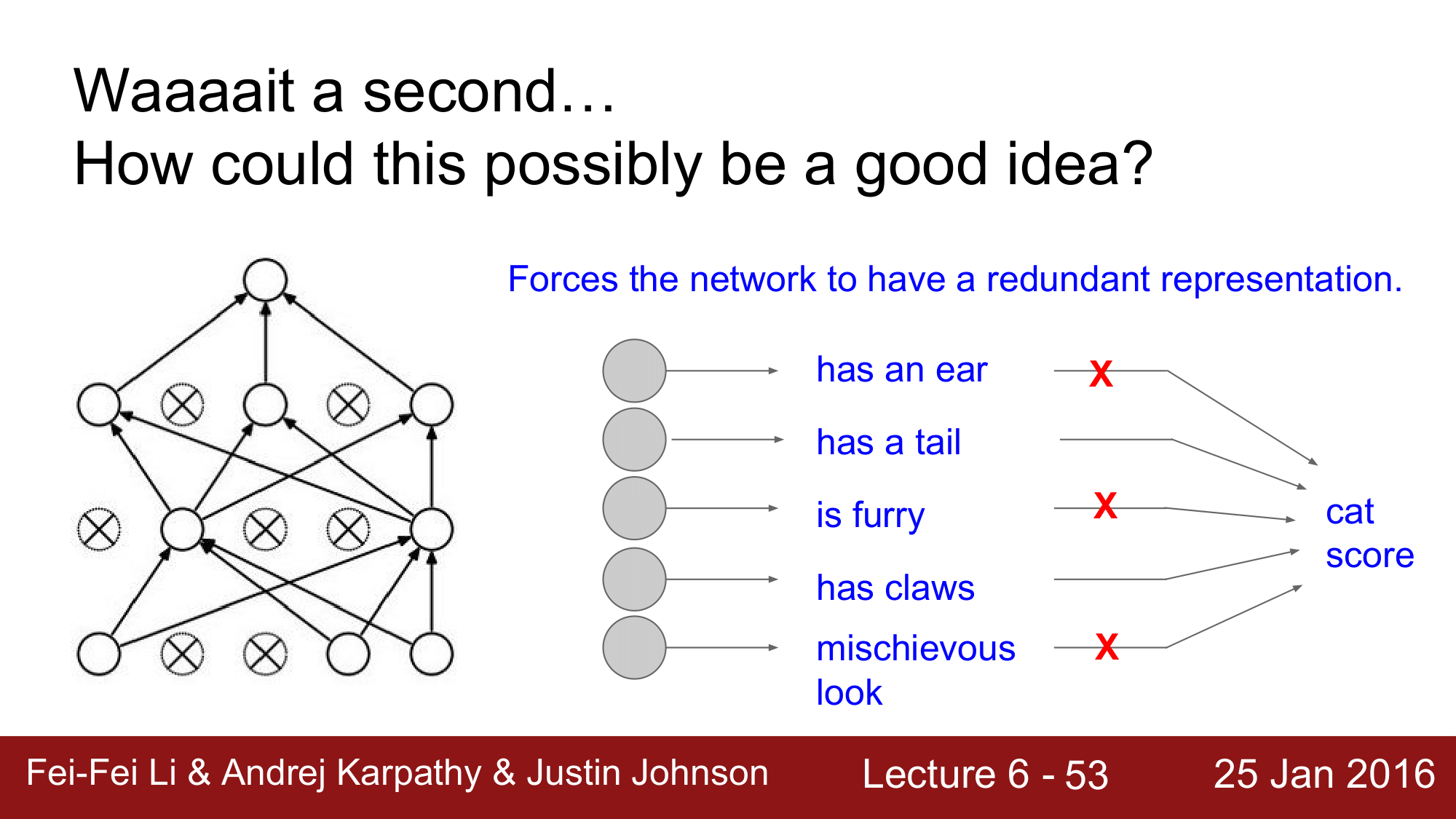
1. 특징 추출시 약간의 중복을 허용
네트워크가 중복을 허용하게 한다는 것으로, 원래는 모든 노드가 살아있는 상태로 학습을 진행하게 되면 각각의 노드가 하나의 특징만을 검출하게 하여 고양이인지 아닌지에 대한 점수를 매겨 검출을 하게 되는데, 드롭아웃을 함으로써 다른 노드들이 드롭아웃 된 노드가 학습할 특징을 같이 중복적으로 학습하여 모든 것을 같이 고려하게 되는 식의 해석 방법이 있습니다.

2. 앙상블의 관점
드롭아웃된 네트워크를 하나의 모델처럼 봐서 평균을 내는 방식으로 앙상블을 통해 성능을 향상시킬 수 있다고 해석할 수 있습니다.
Monte Carlo approximation

앞에서 까지는 학습의 관점에서 살펴보았는데, 그럼 테스트 시에는 어떻게 할 것인가에 대해서도 한번 보겠습니다.
트레이닝 시에는 드롭아웃을 랜덤하게 적용해서 여러가지 노이즈들을 만드는 방식을 이용했습니다. 테스트 시에는 이러한 노이즈들을 통합시키는 것이 이상적인데, Monte Carlo Approximation에서 드롭아웃을 테스트 시에도 그대로 활용하는 방법으로 접근합니다. 각각의 드롭아웃에 대해서 평균낸 것을 이용해 예측을 하자는 방법인데, 안타깝게도 매우 비효율적인 방법입니다.
이 대신에 테스트 때에는 드롭아웃 없이 모든 뉴런을 turn on! 하여 사용합니다. 이때 유의해야할 사항이 있습니다.
바로 test time 에 x라는 output을 얻었을 때, p=0.5면 training time 에 얻을 수 있는 값의 기대치가 x * 2 가 된다는 것 입니다.
test 때 $a = w_0 x + w_1 y$ 라고 하면, train 때에는 x 와 y 노드에 대한 조합으로 총 4개의 경우가 나오게 되어 다음과 같이 됩니다. \(\begin{matrix} E[\text{a}] &=& \frac{1}{4} (w_0 \cdot 0 + w_1 \cdot 0 + w_0 \cdot 0 + w_1 \cdot 1 + w_0 \cdot x + w_1 \cdot 0 + w_0 \cdot x + w_1 \cdot y) \\ &=& \frac{1}{4} (2 w_0 x0 + 2w_1 y) \\ &=& \frac{1}{2} (w_0 x0 + w_1 y) \\ &=& \frac{1}{2} a \\ \end{matrix}\)
즉, test time 때에 training time 만큼 scaling 을 해줘야 합니다.

정리하게 되면, test time 때에는 모든 neuron 이 살아있고 activation 값들을 training time 때의 기대치 만큼으로 스케일링을 해줘야 한다고 할 수 있습니다.

그래서 위의 코드에서도 테스트 시에는 p 만큼 scale 을 해주는 것을 볼 수 있습니다.
그런데 현실적으로는 이런 드롭아웃보다는 Inverted Dropout 이라는 것을 사용합니다.
Inverted dropout

test time 은 그대로 두고, training time 때 미리 / p 를 해줍니다. 즉 training 시에 미리 scale 을 해주는 것입니다. 이렇게 사용하는 것이 보다 일반적인 방법입니다.
4. Convolutaional Neural Networks (CNN)

지금부터는 본격적으로 CNN에 대해 살펴보겠습니다.
Hubel & Wiesel

역사의 첫 시작은 Hubel & Wiesel 의 노벨상까지 받은 생물학적 연구로 고양이의 시신경(visual cortex)이 특정 방향에 반응을 한다는 것을 발견 한 것입니다. Hubel & Wiesel - Cortical Neuron - V1
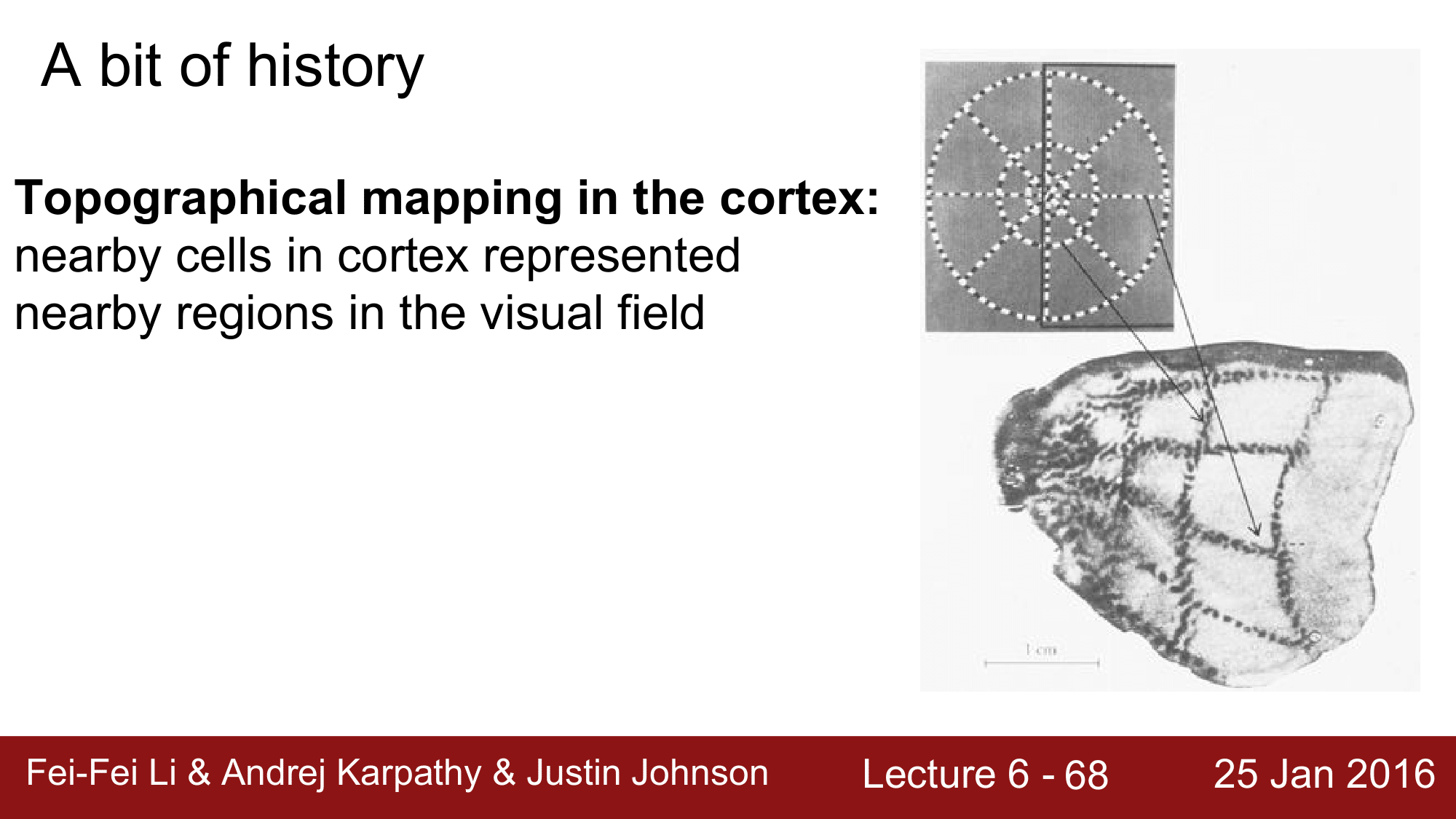 또 다른 발견으로는 cortex의 지역성(locality)이 보존이 된다는 것으로 cortex에서 근접하는 cell은 실제 시각에서도 근접하는 부분을 관장한다는 것입니다.
또 다른 발견으로는 cortex의 지역성(locality)이 보존이 된다는 것으로 cortex에서 근접하는 cell은 실제 시각에서도 근접하는 부분을 관장한다는 것입니다.
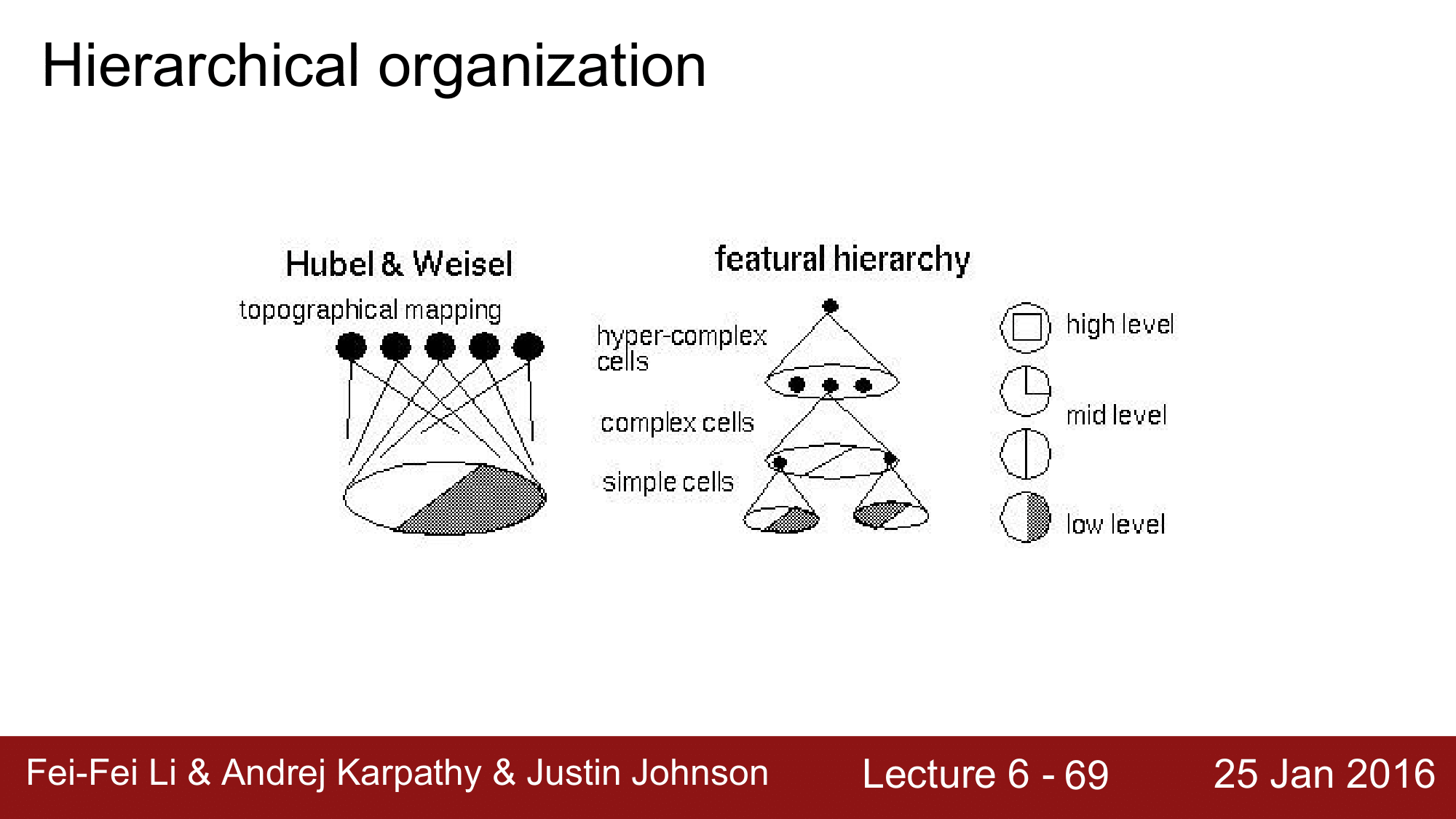 위 연구 결과 시신경의 지역성은 low level 에서 high level 까지 나뉘는데, 이를 컴퓨터를 이용해서 시뮬레이션을 하려는 시도로 이어지게 됩니다.
위 연구 결과 시신경의 지역성은 low level 에서 high level 까지 나뉘는데, 이를 컴퓨터를 이용해서 시뮬레이션을 하려는 시도로 이어지게 됩니다.
NeuroCognitron
첫 번째 시도로, Fukushima 에 의한 Neurocognitron 이라는 장치 입니다.
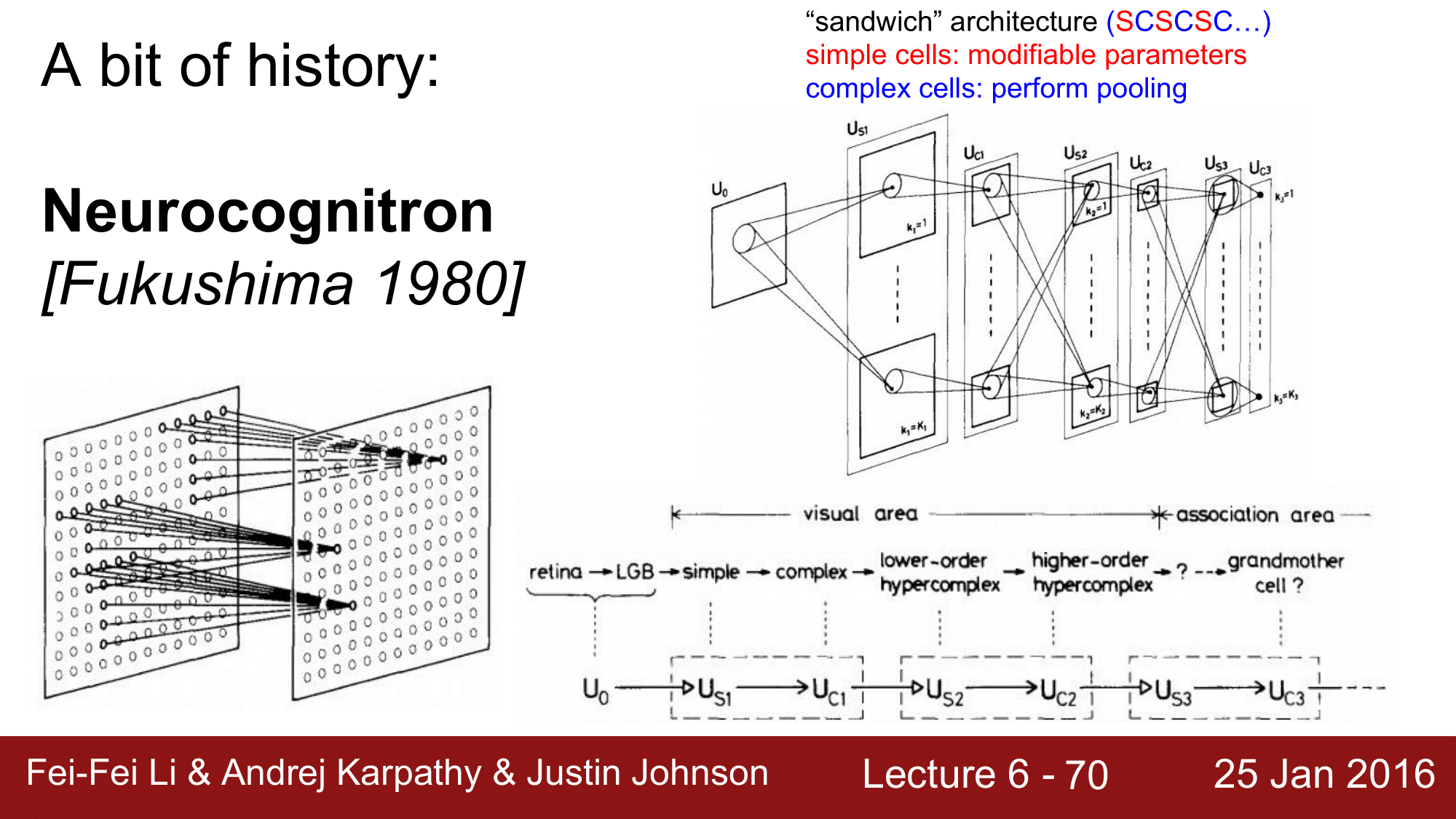
입력값의 작은 부분을 보는 simple cell 들을 s 라고 하고 여러개의 simple cell 을 관장하는 cell 을 complex cell; c 라고 할때 위 그림처럼 쌓아 올리는 식이었습니다. 물론 이때에는 역전파가 불가능한 상태였습니다.
이로부터 약 18년 뒤, 1998년에 실용화가 되기 시작합니다.
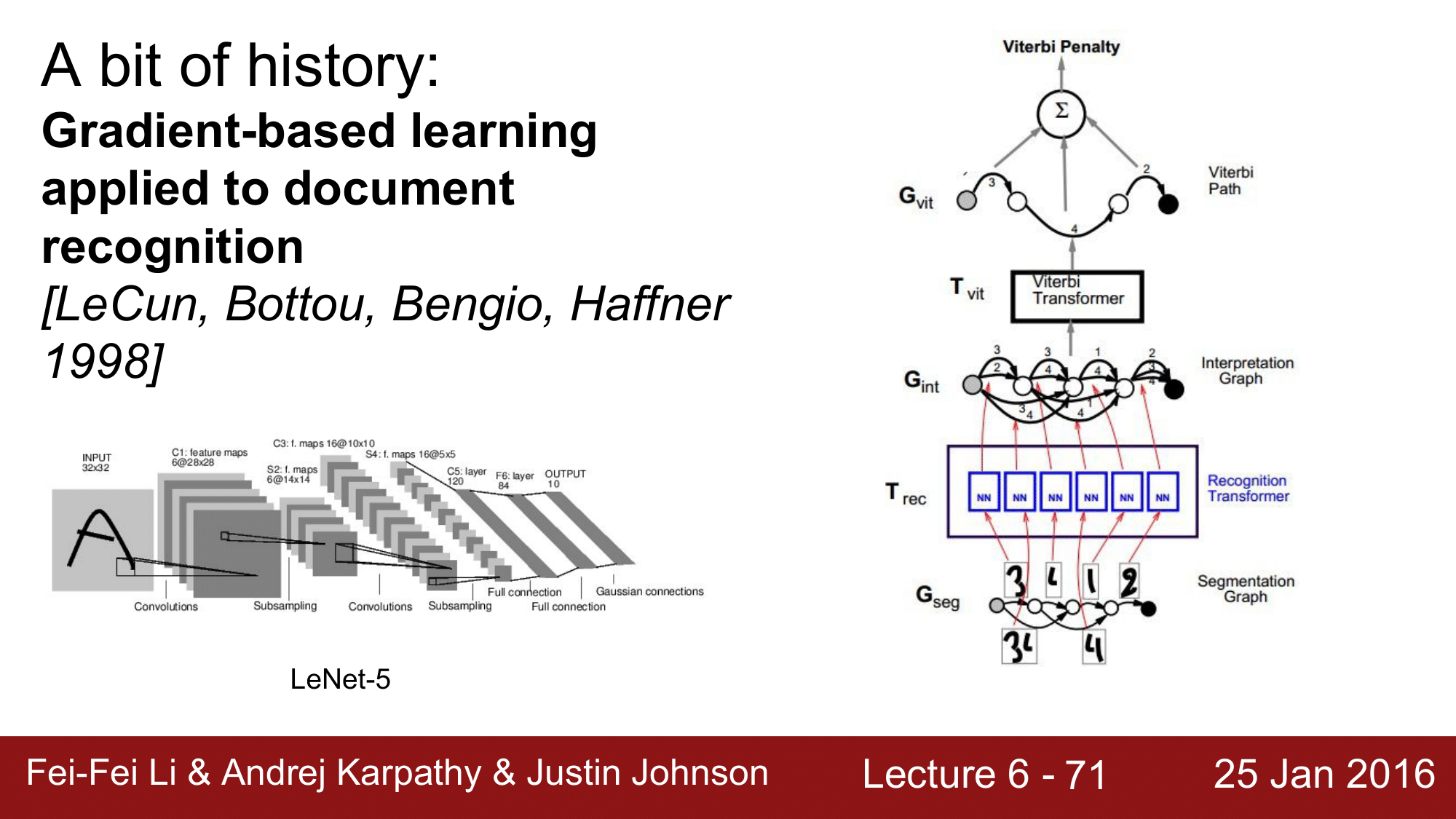
우편물의 우편번호(ZIPCODE)를 분류하는데에 사용한 것으로, 이것이 가능했던 이유는 LeNet에서 역전파가 가능했기 떄문입니다. 이를 통해 CNN 의 가능성이 상당히 확인이 됐습니다.
아후 2012년, AlexNet이 CNN 의 비약적인 발전을 이루게 됩니다.

이 것을 이용해, 이미지를 분류하는 대회에서 기존의 정확도를 확연하게 능가하게 되는 기록을 세우게 됩니다.
재미있는 사실은 1998년의 LeNet 과 비교했을 때, 구조적인 측면에서 큰 차이를 보이지는 않았습니다. 다만, LeNet은 활성화 함수로 $tanh$ 를 사용했고, AlexNet은 LeRU를 사용하고 네트워크가 더 크고 깊어졌으며 GPU 등의 하드웨어가 발전했습니다. 특히, 가중치 초기화를 더 잘했고 배치정규화를 사용했다는 차이가 있습니다.
이런 여러가지 작은 이유들이 복합적으로 작용을 하여, 비약적인 발전을 이룰 수 있었던 것 입니다. 그래서 2012년 이후로는 CNN이 모든 분야에 활용되기 시작합니다.










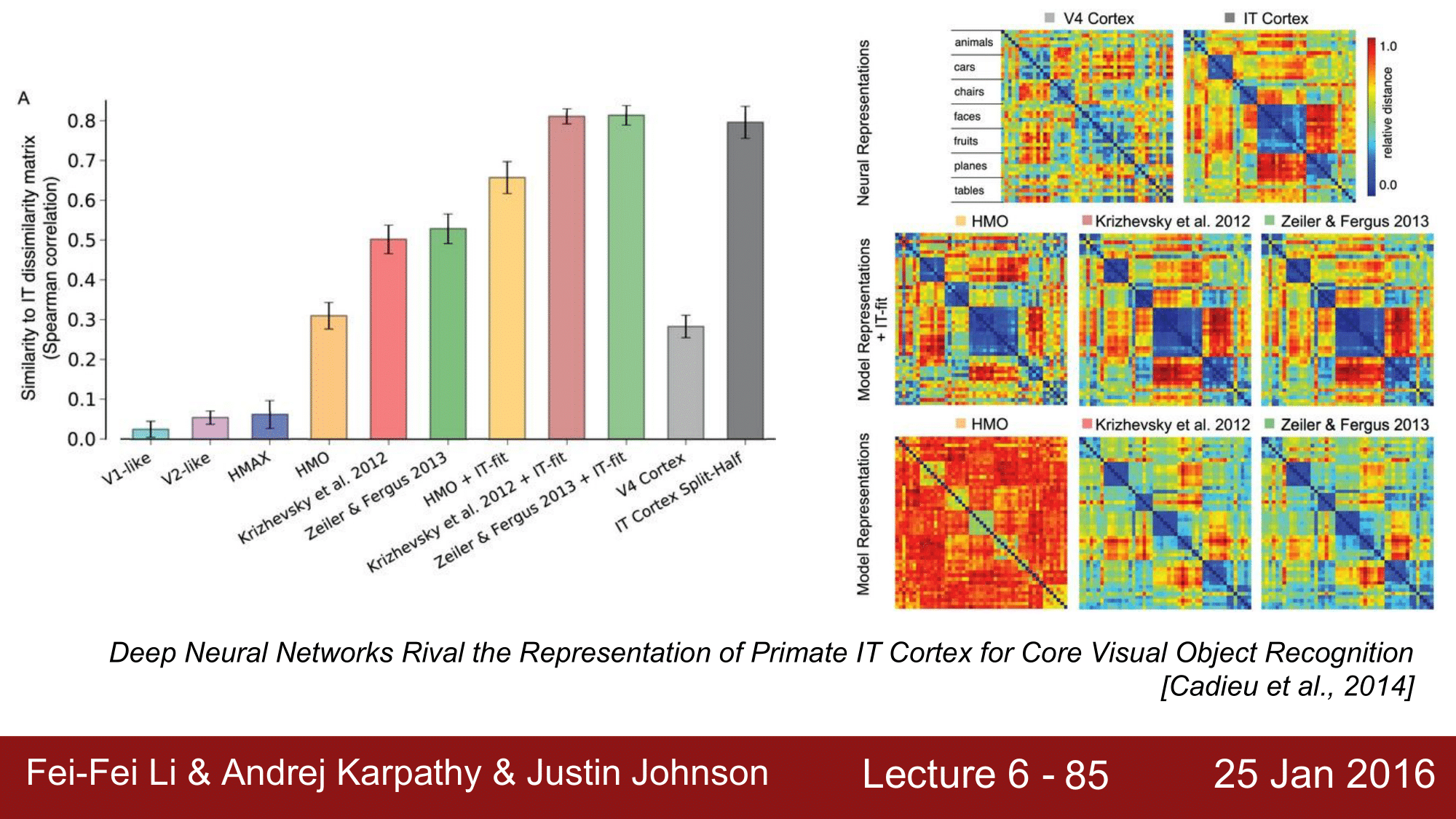
한가지 주목하고 넘어가야 하는 사실은, 2013년의 CNN 이 원숭이의 하측 두 피질과의 정확도와 동일한 수준이라는 것입니다.
재미있는 사실은, 원숭이의 IT Cortex에서 보는 것을 오른쪽 그림과 같이 Representation 한 내용과 AlexNet이나 2013년의 ZFNet 이 예측한 내용과 굉장히 유사하게 나타난다는 것 입니다.
결과적으로 CNN이 사람만큼, 사람 이상으로 정확도를 보이는 이유가 됩니다.