
해당 포스트는 송교석 님의 유튜브 강의를 정리한 내용입니다. 강의 영상은 여기에서 보실 수 있습니다.
이번 포스트에서는 신경망을 어떻게 학습시키는 지에 대해서 알아보겠습니다.
Finetunning
ConvNet은 학습을 위해 많은 데이터를 필요로 한다”라는 말이 있는데, 이는 잘못된 미신일 수 있습니다.
왜냐하면, Finetunning이라는 방법이 있기 때문입니다. 예를 들어, ImageNet에서 이미 학습된 데이터를 가져와서 해당 값을 기반으로 특정 상황을 위한 추가적인 데이터를 학습시켜 모델을 만들어 낼 수 있기 때문입니다. 이렇게 finetunning을 이용해서 학습시키는 것을 전이 학습이라고 할 수 있는데 그림을 보면서 설명드리겠습니다.

제일 왼쪽에 있는 모델을 우리의 모델이라고 했을 때, 먼저 ImageNet의 데이터를 가져와 학습시킵니다.
사실, 데이터를 가져와 학습시킬 필요가 없습니다. 일반적으로 ImageNet, AlexNet 과 같은 것들은 학습 데이터와 함께 이미 학습된 가중치 값을 오픈해놓기 때문입니다.
근데, 우리가 가지고 있는 데이터 셋이 너무 작다면, 기존에 ImageNet에서 학습시킨 가중치들을 모두 고정시켜두고, 맨 마지막 부분에 위치한 Classifier부분만 다시 학습을 시킵니다. 위 그림에서는 Softmax Layer를 교체해주면 됩니다.
혹은, 우리가 가지고 있는 데이터 셋이 위와 같이 너무 작지도 않고, 너무 많지도 않은 상황이 있을 수 있는데, 이런 경우에 finetunning을 이용하여 학습시킵니다.
finetunning의 방법에는 크게 보면 두 가지로 방법이 있다고 할 수 있습니다.
첫 번째 방법은, 다른 곳에서 가져온 가중치들을 우리의 새로운 모델의 초기화 값으로 사용하는 것 입니다. 그렇게 Initialization Value로 사용한 뒤, 이를 기반으로 전체 학습을 진행합니다.
두 번째 방법은, 위 그림에서 처럼 윗부분과 아랫부분을 나눠서 봤을 떄, 윗 부분은 고정을 시켜놓고 아랫 부분만 학습을 시키는 방법입니다.

Caffe의 경우를 보게되면, Model Zoo라는 것을 가지고 있는데, 이는 이미 다양한 데이터 셋에 대해 학습을 시켜 놓은 가중치들을 Zoo에 업로드하여 마치 Docker Hub 처럼 사용할 수 있게 되어 있습니다.
Model Zoo는 Caffe에서 시작되었지만, 지금은 TensorFlow나 Pytorch같은 곳에서도 사용하고 있습니다.
연산 자원
또 하나로, “터미널이 무한한 연산 자원을 가지고 있다”고 생각하는 경향이 있는데, 이 또한 잘못된 미신이라는 것입니다.
그렇기 때문에 너무 무리하게 많은 데이터를 학습시킬 생각을 하는 것은 좋지 않다는 것을 알아두면 좋습니다.
2. 신경망의 역사
퍼셉트론(Perceptron)

최초의 Neural Network는 1957년의 퍼셉트론(Perceptron)이라고 할 수 있습니다. 당시 Mark I이라는 퍼셉트론은 소프트웨어는 아니었고, 회로(Circuit)기반의 하드웨어였습니다.
그리고 퍼셉트론의 수식을 보게되면 다음과 같은데,
\[f(x) = \begin{cases} 1 \quad \text{if } w \cdot x + b > 0 \\ 0 \quad \text{otherwise} \end{cases}\]기본적으로 binary step function이라 미분이 불가능하다는 단점도 존재했습니다. 그 때문에 Backpropagation이 불가능하여 가중치 W 값들을 임의로 조정하면서 최적화를 시도하였습니다. 물론, 이 시기에는 역전파나 손실함수에 대한 개념이 존재하지 않았습니다.
중첩된 퍼셉트론(Multilayered Perceptron)
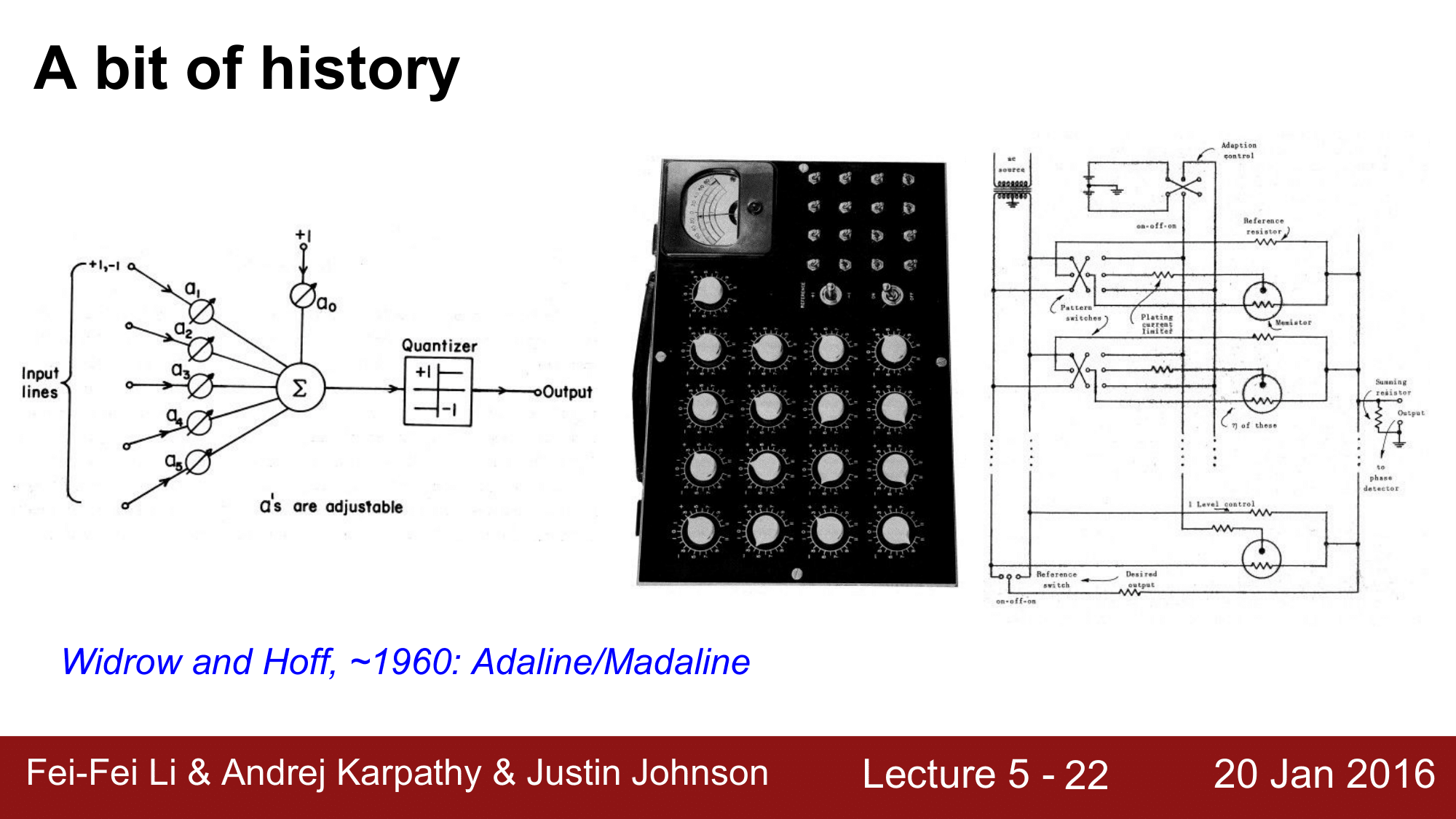
몇 년후, 1960년대에 들어서 퍼셉트론을 쌓기 시작했지만, 이 때 역시 역전파의 개념이 존재하지 않았고, 미분이 불가능한 퍼셉트론을 쌓기만 한 것이었기 때문에 가중치 설정에 대한 많은 어려움이 있었습니다.
하지만, 퍼셉트론과 같은 Parametric Approach를 도입한 것 만으로도 굉장한 도약이었습니다.
이후, 기대했던 것에 비해 성능이 좋지 않아 신경망의 첫번째 암흑기에 접어들게 됩니다.
최초의 역전파(First time back-propagation)

1986년에 최초로 backpropagation을 도입하면서 다시 빛을 발하게 됩니다.
역전파를 하게 된다는 것은 미분이 가능하다는 것이고, 이로 인해 가중치를 체계적으로 찾아나갈 수 있다는 것이기 때문에 다시 큰 기대감을 불러일으켰습니다.
하지만, 신경망이 커지고 Deep해지게 되면 기울기 소실이라는 문제점이 발생하여 제대로 동작하지 않는 문제가 발생하였습니다. 이 때문에 잠시 반짝했었던 기대감이 줄어들면서 2000년대 중반까지 신경망의 두번째 암흑기에 접어들게 됩니다.
RBM(Restricted Boltzman Machine)

2006년, RBM이라는 것을 이용해 이미지 데이터를 pretraining하고, 두 번째 단계에서 이들을 하나로 묶어 Backpropagation을 수행했더니 정상적으로 작동하는 것을 확인했습니다. 이렇게 해서 제대로 동작하는 역전파를 제대로 성공시킨 것인데, 나중에 가서 RBM을 이용해 pretraining을 할 필요가 없었다는 것이 밝혀지게 됩니다.
가중치 초기화의 문제와 활성화 함수로 시그모이드를 사용했다는 것이 문제였던 것인데, 이 당시에는 정상적으로 작동하는 것 만으로도 큰 의미가 있었습니다.
이 떄부터 관련 연구가 활성화되기 시작했고, 딥러닝이라는 이름으로 rebranding 되었습니다.
AlexNet
이후 2010년의 MicroSoft의 결과물 AlexNet과 2012년의 Hinton, Alex 교수의 결과물로 인해 폭발적인 주목과 발전을 이룩하게 됩니다.
이렇게 주목을 받게된 이유로는 여러가지가 있는데, 첫번째로 Weight Initialization을 제대로 할 수 있는 방법을 찾았고, 두번째로 시그모이드 이외의 Activation Function을 찾았으며, 마지막으로 GPU의 발전으로 인한 계산능력강화와 폭발적인 데이터 증가로 인한 연구에 좋은 환경이 되었다는 점입니다.
3. 개요(Overview)
지금부터 본격적으로 학습에 필요한 설정들과 평가방법들에 대해 알아보겠습니다.
- One time setup
- Training dynamics
- Evaluation
4. 활성화 함수(Activation Functions)

활성화 함수는 Cell body 에 $\sum_{i} w_ix_i + b$ 에 Non Linearity를 제공하는 activation function $f$가 됩니다.
이전 포스트에서도 설명드렸듯이 활성화 함수로는 다양한 함수가 있습니다. 먼저 시그모이드 함수에 대해 설명해보겠습니다.
시그모이드 함수(Sigmoid Function; Squash Function)
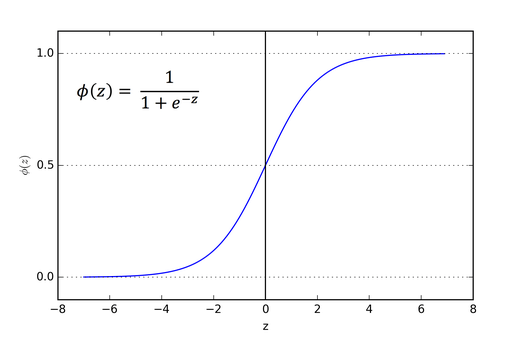
전통적으로 사용되어 왔지만 더 이상 사용되지 않는 함수가 바로 시그모으드 함수입니다. 시그모이드 함수는 넓은 범위에 있는 값들을 0과 1 사이의 값들로 squash해준다고 하여 Squash Function이라고도 불립니다.
입력값에 대해 0과 1사이의 값들을 반환하여, 마치 확률과 같이 값을 반환하게 되어 입력값에 대한 가중치의 영향력을 주기 좋기 때문에 많이 사용되어 왔습니다.
하지만, 더 이상 사용되지 않을 만한 몇 가지 문제점들이 존재합니다.
문제점 1: 뉴런의 포화로 인한 gradient의 소실; vanshing gradient
세가지 문제점 중 가장 심각한 문제점으로 vanishing gradient문제점이 있습니다. 이는 Saturated neuron 즉, 0 또는 1에 가까운 값을 나타내는 뉴런들이 반환하는 기울기가 0에 수렴하게 되어 종단에는 가중치에 아무런 영향력을 행사하지 못하는 학습도중 신경망 학습이 중단되어 버리는 문제점입니다.

좀 더 자세히 설명하면, 먼저 gradient는 local gradient와 global gradient의 곱으로 표현이 됩니다.
$x$가 매우 큰 값을 갖을 떄 $x$에 대해 시그모이드 함수를 미분하게 되면 기울기가 거의 0에 가깝기 때문에 0에 가까운 값이 나오게 되고, 마찬가지로 $x$가 매우 작을 때도 0인 값이 나오게 됩니다.
다시말해, $x$가 매우 작거나 큰 경우에는 local gradient가 0의 값이 되어버리기 때문에 backpropagation이 중단되는 결과가 나타나게 됩니다.
그래서, 시그모이드 함수 중간 부분을 정상 작동 지점 (active region of sigmoid), 양 쪽 끝에 기울기가 거의 0인 지점을 포화지점 (saturated regime)이라고 표현하게 됩니다.
문제점 2: not zero centered -> low convergence
두 번째 문제점으로 시그모이드 함수가 0을 중심으로 하지 않고, y값이 항상 0보다 크다는 문제점입니다.

위의 식에서 $x$는 항상 양수입니다. 왜냐하면, 기본적으로 $x$는 앞 단에서 항상 양수를 반환하는 시그모이드 함수를 거쳐 들어오기 때문입니다.
이 때, 위의 식을 $w$로 미분하게 되면,
\[\begin{aligned} \frac{dL}{dw_i} & = \frac{dL}{df} \cdot \frac{df}{dw_i} \\ & = \frac{dL}{df} \cdot f(1-f) \cdot x_i \end{aligned}\]가 되고 이때 $f(1-f)$는 ${y\ \in \reals : 0<y\le \frac{1}{4}}$ 이고 $x_i > 0$이기 때문에 결과적으로 $\frac{dL}{dw_i}$은 $\frac{dL}{df}$와 같은 부호를 같게 됩니다.

이렇게 되면, 가중치 업데이트시 가장 이상적인 방향인 대각선으로 값이 이동하는 것이 아니라, 지그재그로 이동하기 때문에 very slow convergence 한 결과를 갖게 됩니다. 따라서 non zero centered한 활성화 함수는 convergence 가 느려지는 결과를 도출할 수 있습니다.
문제점 3: 지수함수의 큰 계산 비용
지수함수의 연산은 큰 계산 비용이 들기 때문에, 성능저하를 일으키게 됩니다.
이와 같은 세가지 이유로 인해 시그모이드 함수는 더 이상 거의 사용되지 않는 활성화 함수 입니다.
하이퍼볼릭 탄젠트(Hyperbolic tangent)
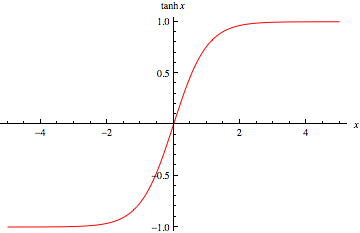
하이퍼블릭 탄젠트 함수는 -1과 1에 squash하는 형태로 되어있고, zero centered 한 특징을 같습니다. 하지만 여전히 0이 매우 크거나 작을 때 기울기가 소실되는 Saturation 문제가 발생합니다.
ReLU(Rectified Linear Unit)
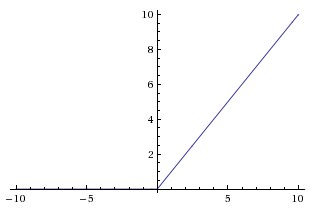
ReLU 함수는 현재 가장 기본적인 활성화 함수로, $f(x) = max(0, x)$로 나타낼 수 있습니다.
$x > 0$일 때, 기울기가 1이기 떄문에 saturation이 발생하지 않고, $max$함수만 활용하기 때문에, 연산이 매우 효율적이고 sigmoid 나 tanh보다 6배 더 빠른 convergence rate를 갖습니다.
하지만, ReLU 역시 문제점이 존재합니다.

gradient는 local gradient와 global gradient로 이루어져 있어서 $x = 10$ 인 경우에는, local gradient가 1이 됩니다.
그런데 $x = -10$이면, 기울기는 0이 되어서 gradient가 죽어버리는 결과가 나오게 됩니다. 즉, 기울기 소실 Dead ReLU가 되어버립니다.
그리고 $x = 0$인 경우에는 극한이 존재하지 않아서 미분이 불가능하기 때문에, gradient가 정의되지 않는(Undefined) 지점이 됩니다.
위 내용을 정리하자면 다음과 같습니다.
문제점
- Not zero-centered
- $x<0$ 일때 기울기 소실(vanishing gradient)
- $x=0$ 에서 smooth 하지 않아 극한이 존재하지 않음
ReLU가 현재로써 기본적은 활성화 함수이긴 하지만, 위와 같은 문제점들을 가지고 있기 때문에, 이에 대한 한계를 알고 있어야 나중에 어떤 문제에 봉착했을 때에 해결할 수 있으니 이러한 문제점들은 기억해 두는 게 좋습니다.
Active ReLU 와 Dead ReLU
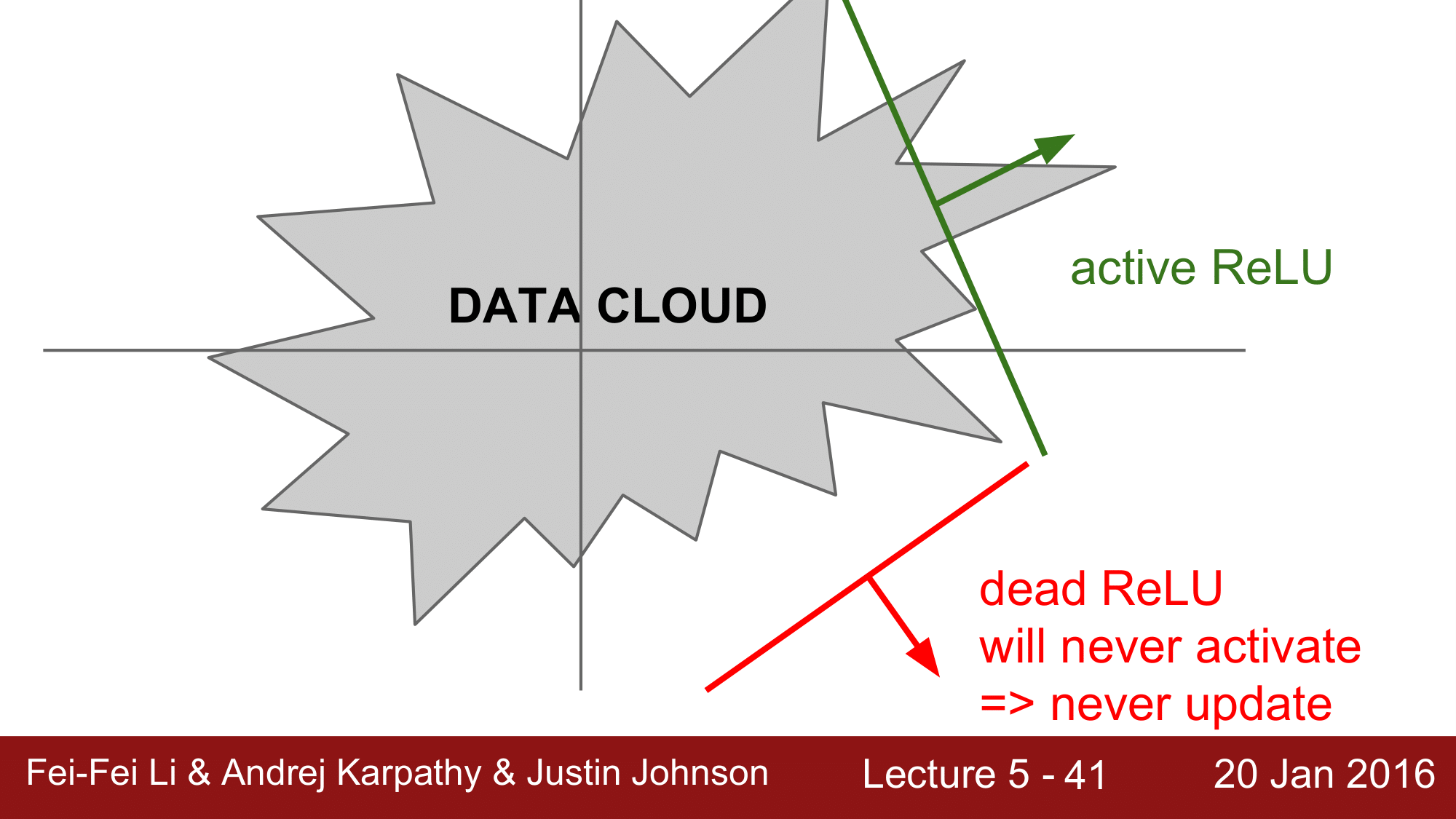
앞에서 언급한 Dead ReLU를 설명하기 위해 위 그림을 한번 보겠습니다.
위에서 회색부분을 input 데이터가 들어가는 Data Cloud라고 했을 때, 뉴런이 이 데이터 클라우드 내에서 activation 된 경우를 active ReLU라고 하고, 데이터 클라우드 외부에서 activation 된 경우는 Dead ReLU라고 합니다.
Dead ReLU의 경우는 절대로 activation되지 않기 때문에, update 또한 일어나지 않는 결과를 가져옵니다.
이러한 Dead ReLU 발생 요건을 살펴보면 다음과 같습니다.
- 운이 좋지 않아서, Dead ReLU zone 에서 시작할 때
- 학습시, $\alpha$(lr; learning rate)가 너무 큰 경우
위와 같은 문제를 대처하기 위한 방안으로, 아주 작은 양수 (0.01)로 초기화 하기도 합니다만, 이렇게 하는 것에 대한 효과는 검증되지 않았습니다.
Leaky ReLU
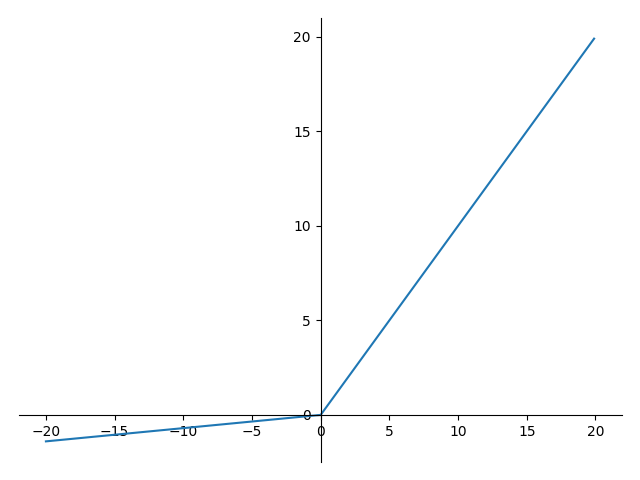
2013년, 2015년에 Kaiming He. 가 Leaky ReLU라는 것을 주장했습니다.
ReLU와의 차이점은 함수의 형태가 최솟값이 $0$이 아니라, $0.01x$ 라는 점입니다.
위의 그래프를 보게 되면, $x < 0$인 지점에서 기울기가 0 이 아니라 0보다 작은 값을 갖게되는 형태임을 알 수 있습니다.
그렇기 때문에, $x$의 값에 대해서 saturation이 발생하지 않을 것이고, 이로 인해 앞의 함수들에서 발생했던 vanishing gradient문제가 발생하지 않는다라는 것을 확인 할 수 있습니다.
Leaky ReLU가 좋다고 하는 사람들도 있긴 하지만, 아직 완전히 검증이 끝난 것은 아니기 떄문에 감안을 하고 사용을 해야 합니다.
정리하자면,
- Not saturated
- 효율적인 연산가능(exponential 과 같은 복잡한 계산비용이 발생하지 않음)
- 완전히 검증되지 않음
PReLU (Parametric Rectifier Unit)
PReLU는 ReLU에 대한 또 다른 변형 함수로 다음과 같은 식으로 되어 있습니다.
Leaky ReLU와 다르게, $0.01$ 이 아닌 $\alpha$를 사용하여, Backpropagtaion 수행시에 해당 기울기를 학습하게 한다는 것이 PReLU의 특징입니다.
ELU(Exponential Linear Units)
ELU라고 하는 또 다른 변형이 있습니다.
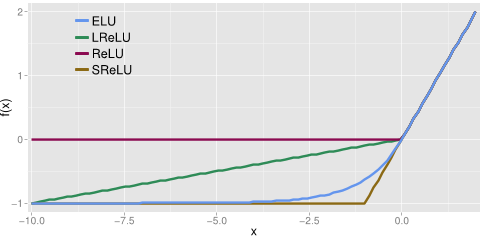
함수의 형태는 위의 그림처럼 $x > 0$인 경우에는 형태가 모두 같지만, ReLU, Leaky ReLU와는 다르게 $\exp$함수의 효과로 0 부근의 지점에서 round 한 모양을 가지게 됩니다.
장점
- ReLU의 모든 장점을 가짐
- 기울기 소실이 발생하지 않음
- zero mean output에 가까워짐
단점
- exp() 연산이 필요함
Maxout
activation function의 마지막으로 Maxout까지 소개하겠습니다.
이 함수는 Ian Goodfellow 라는 분이 2013년에 발표하신 함수로, $wx + b$와 같이 일반적으로 loss 를 계산하는 것이 아니라, Neuron이 연산하는 방법을 바꿨습니다.
ReLU와 Leaky ReLU를 일반화했으며, saturation와 vanishing gradient도 발생하지 않습니다.
이러한 장점들을 갖는데, 위의 함수를 보면 알 수 있듯이 2개의 파라미터 값을 갖습니다. 따라서 앞에서 소개했었던 1개의 파라미터만 사용하는 함수들에 비해 2배의 연산을 필요로 하게 되는 문제가 발생합니다.
정리
- 특별한 경우가 없으면,
ReLU사용 - 실험이 필요한 경우,
Leaky ReLUMaxoutELU사용 tanh는 가급적 사용을 하지 않을 것sigmoid함수는 더 이상 사용하지 않을 것
이후에 LSTM (Long Short-Term Memory)같은 경우에는 sigmoid를 사용하는 것을 볼 수 있습니다.
4. 데이터 전처리(Data preprocessing)
지금부터는 데이터 전처리에 대해서 간단하게 알아보겠습니다.
Step #1: Preprocess the data
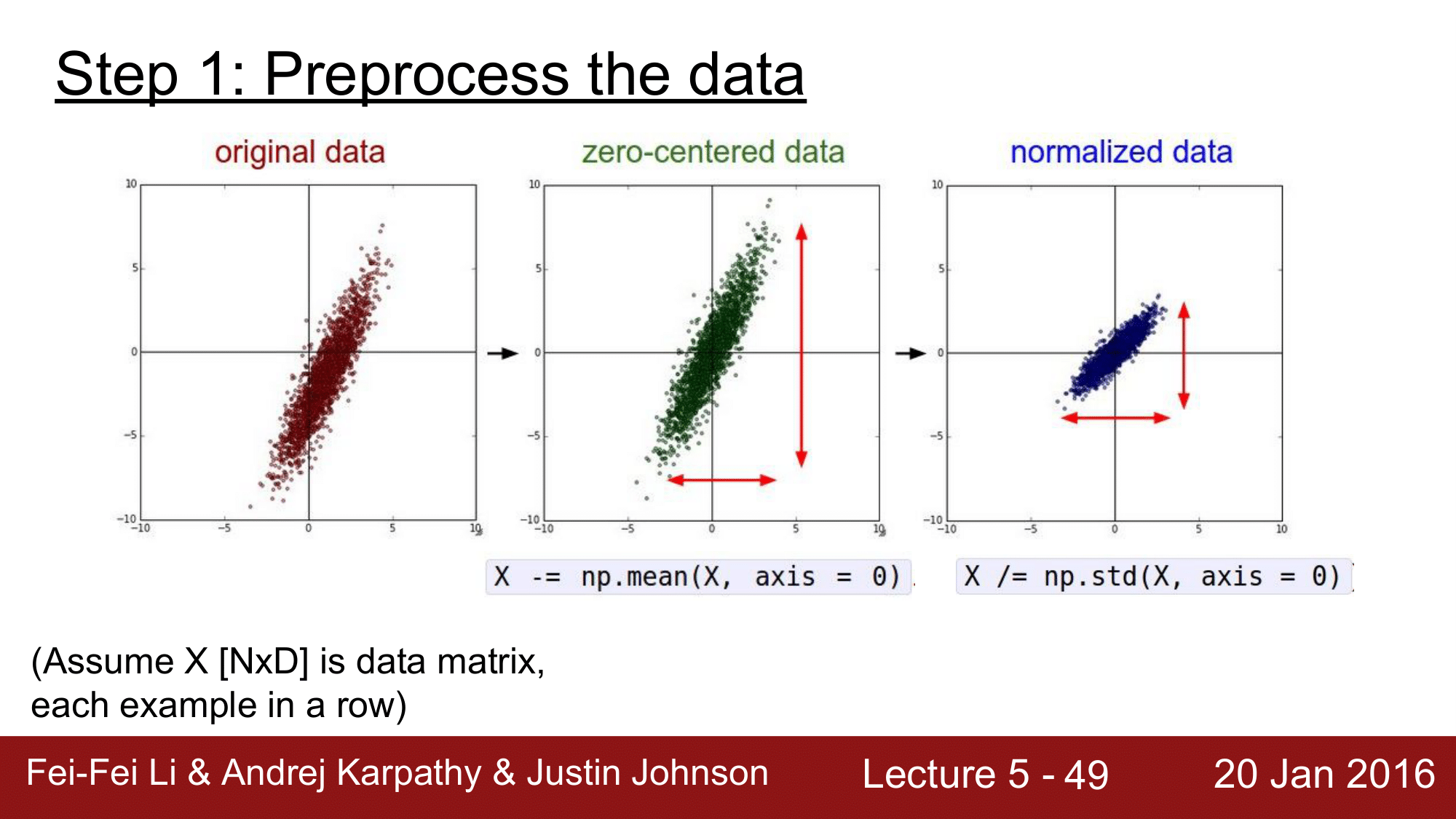
위와 같이 original 데이터가 있으면 먼저, X -= np.mean(X, axis=0)으로 각각에 대해 전체의 평균을 빼주는 방식으로 zero-centered를 맞춰줍니다. 이후 X /= np.std(X, axis=0)으로 normalization을 수행해줍니다.
그런데, 이미지에서는 일반적으로 zero-centered를 수행하지만 normalize를 수행하지 않습니다.
그 이유는, normalization을 수행하는 목적이 데이터가 어떤 특정 범위 내에 존재하도록 값을 조정하는 작업인데, 이미지 데이터의 경우 이미 0~255사이의 값들로 이미 특정 범위 내에 존재하기 때문입니다.
또한 이미지 분석에서는 주성분 분석(PCA), 백색화(Whitening)를 하는데, 이 역시 이미지에서는 사용하지 않습니다.
주성분 분석(PCA): 데이터를 비 상관화하여 차원을 줄이는 방법 백색화(Whitening): 인접하는 픽셀들 간의 인접성(redundancy)를 줄이는 방법
정리하자면, 이미지 전처리 과정에서는 zero-centered만 고려를 하면 됩니다.
zero-centered를 하는 방법은, CIFAR-10을 예로들어 설명하자면 [32,32,3]으로 된 이미지들로 부터 mean Image를 구해서 각 이미지에 값을 빼주는 방법이 있고, RGB각 채널별 mean값을 구해서 빼주는 방법이 있습니다.
위 두가지 방법의 편의성을 비교해보면, 각 3개의 채널만 고려하면 되는 두 번째 방법이 편리하다고 할 수 있습니다.
5. 가중치 초기화 (Weight Initialization)
가중치 초기화는 매우 중요한 주제입니다.
2006년도의 RBM에서 발생한 문제도 가중치 초기화로 유래된 문제였습니다.
예를 들어, 모든 가중치가 0으로 초기화 되면 모든 뉴런들이 동일한 연산을 수행하게 되고, 역전파의 경우에도 동일한 연산을 수행하게 됩니다. 이렇게 동일한 연산을 수행하게 되면 symmetric breaking이 발생하지 않게 됩니다.
Idea 1. Small random numbers
가중치를 초기화 하는 가장 기본적인 아이디어로 small random number로 가중치를 초기화 하는 방법이 있습니다.
W = 0.01 * np.random.randn(D, H)
1e-2 의 가우시안 정규분포로 W를 초기화 하는 것 입니다.
이렇게 구성하게 되면 network이 작은 경우 문제 없지만, 커지면 문제 발생하게 됩니다.
다음은 위의 방법을 이용한 가중치 초기화를 시행했을 때의 평균과 표준편차를 계산하는 코드입니다.

먼저 10개의 hidden layers 를 구성하고, 각각의 레이어에 500개의 노드를 구성해 줍니다. nonlinearity는 $tanh$를 사용하여 [-1, 1]의 범위를 갖도록 설정해 줍니다.
그 다음, W를 0.01을 곱해준 정규분포로 초기화 해줍니다. 이후 평균과 표준편차를 구해주고 그래프와 히스토그램으로 그려줍니다.
다음은 위 코드의 실행 결과 입니다.
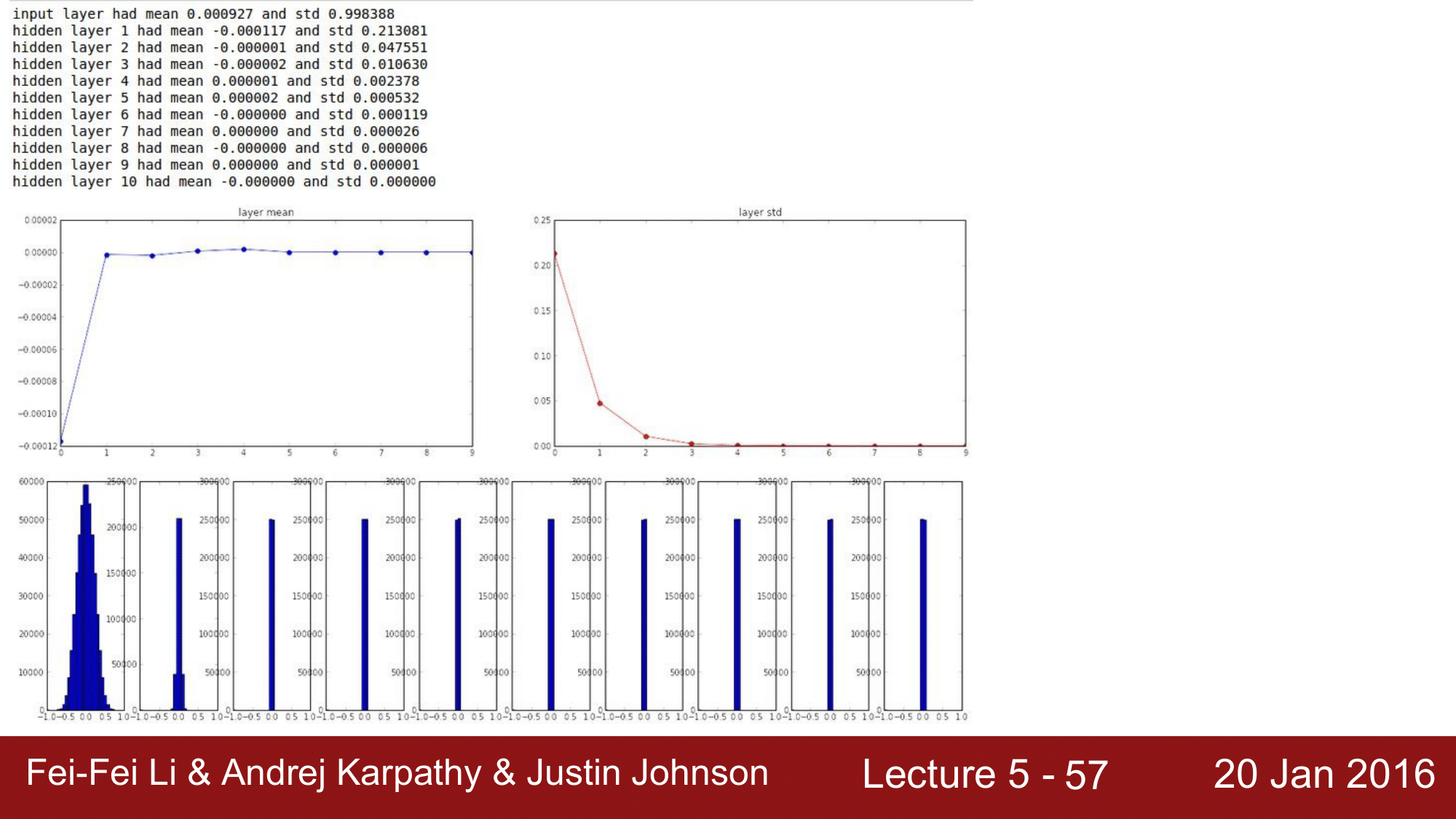
위 그림에서, 각각의 평균과 표준편차를 출력하여 그래프로 나타내고 있는 것을 확인할 수 있습니다.
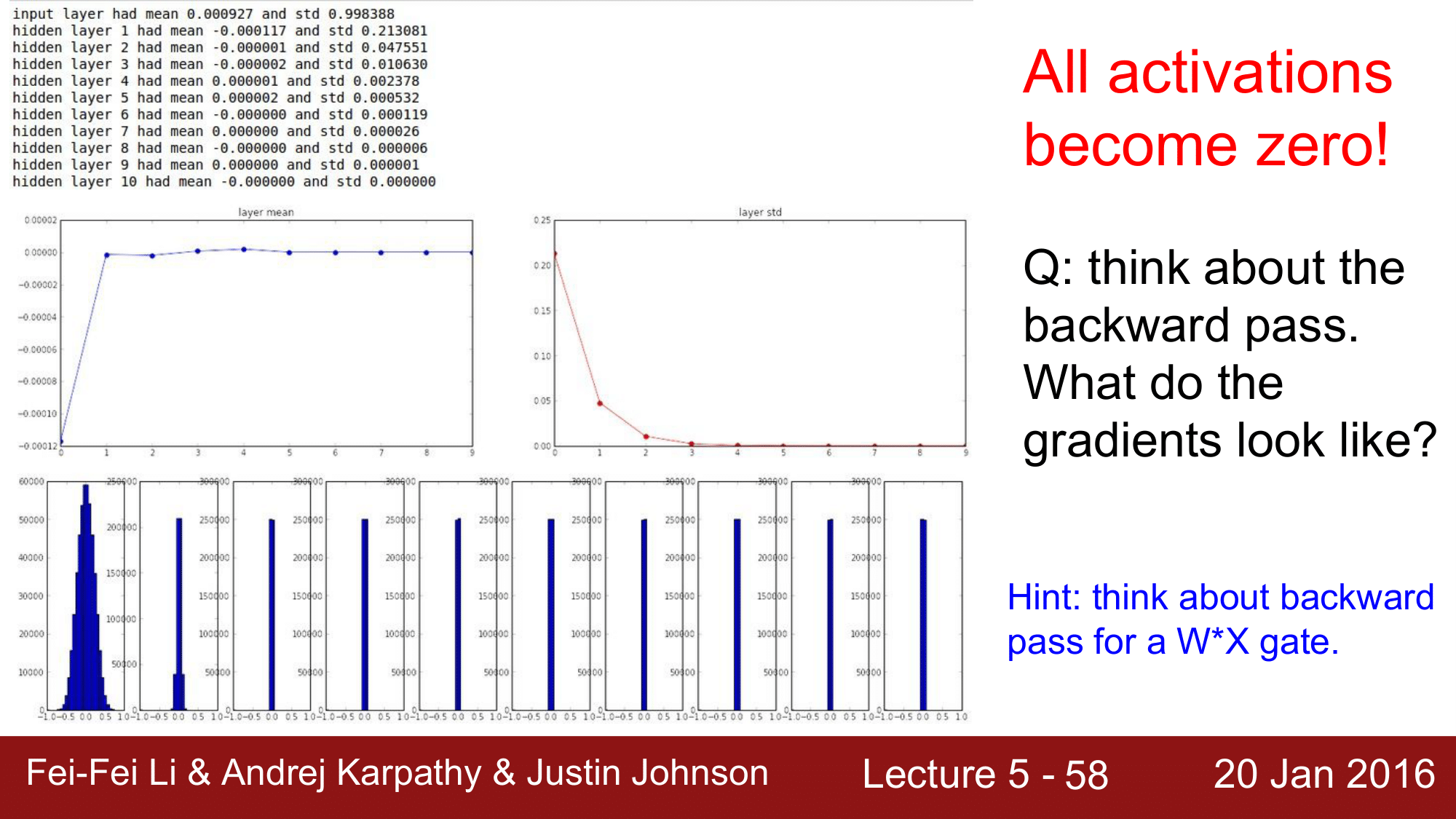
코드상에서 $tanh$를 사용했기 떄문에 평균값이 0으로 수렴하는 것을 볼 수 있습니다. 하지만 문제는 표준편차가 급격하게 0으로 수렴한다는 것입니다. 이 때문에 히스토그램을 보게 되었을 때도, 처음에는 잘 분포되어 있다가 레이어를 거치면서 중앙으로 collapse하게 되는 것을 확인할 수 있습니다. 이렇게 되면 결국에는 모든 activation들이 0이 되어버리는 결과를 얻게 됩니다.
이러한 상황에서 역전파에 대해서도 생각해 볼 수 있는데, 역전파의 경우 식이 다음과 같습니다.
\[dW_1 = X \cdot dW_2\]X가 0에 가까워짐에 따라 $dW_1$역시 0에 수렴하게 되어 결과적으로 기울기가 0이 되어버리는 즉, vanishing gradient문제가 여기서도 발생하게 됩니다.
위의 코드는 0.01 대신에 1.0을 적용하여 실행한 코드입니다. 이렇게 되면 보시다시피 W값이 너무 크기 때문에 overshooting이 발생하여 거의 모든 뉴런들이 -1 또는 1로 saturation 되게 됩니다. 당연히 gradient값도 0 이 되어 vanishing gradient문제가 발생합니다.
실제로 학습을 시킬때 loss 값이 전혀 변하지 않는 현상을 볼 수 있는데, 이런 경우가 위와 같이 $W$값을 매우 크게 잡은 경우에 발생하게 되는 것입니다. 따라서 이에 대한 주의가 필요합니다.
Idea 2. Xavier initialization
가중치를 초기화하는 다른 아이디어로 자비에르 초기화(Xavier initialization)방법이 있습니다.
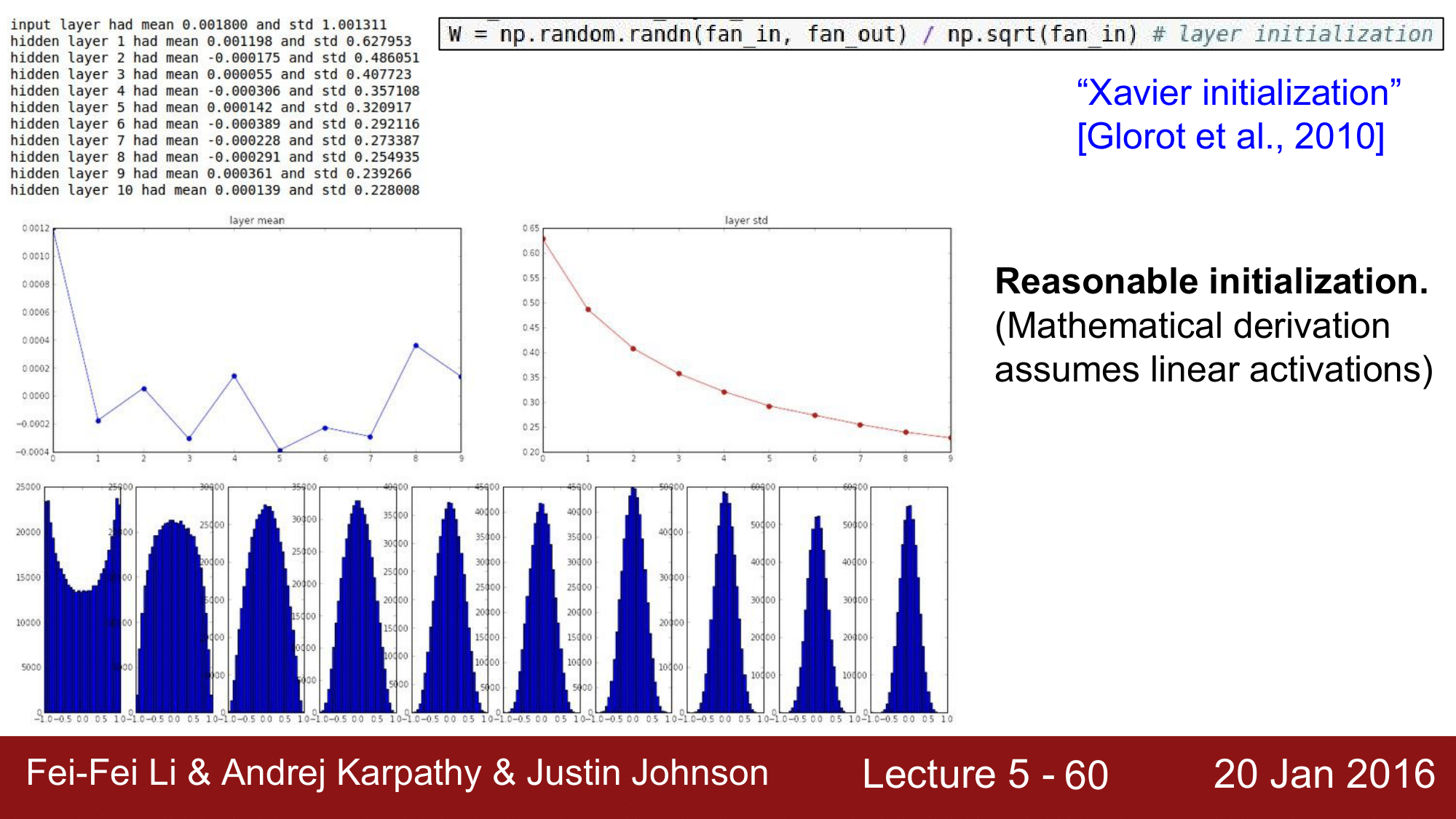
자비에르 초기화에서 주의 깊게 봐야할 부분은 위의 코드에서 np.sqrt(fan_in)부분입니다. 입력값의 개수가 커지면 해당 부분또한 커져서 결과적으로는 W가 작아지게 되고, 반대로 작아지면 W값이 커지는 방식으로 초기화합니다.
이러한 특성 때문에 매우 합리적인 초기화 방법이라고 할 수 있고, 그림 밑부분의 히스토그램을 보게 되면 layer가 깊어짐에도 불구하고 saturation이 발생하지 않고 정상적으로 작동하는 것을 확인할 수 있습니다. 그렇기 때문에 $tanh$와 같은 함수에서 잘 작돌하는 것을 볼 수 있습니다.
하지만 이 초기화 방식에도 문제점이 있는데, 바로 ReLU를 사용할 시에 다시 saturation이 발생하게 된다는 것 입니다.
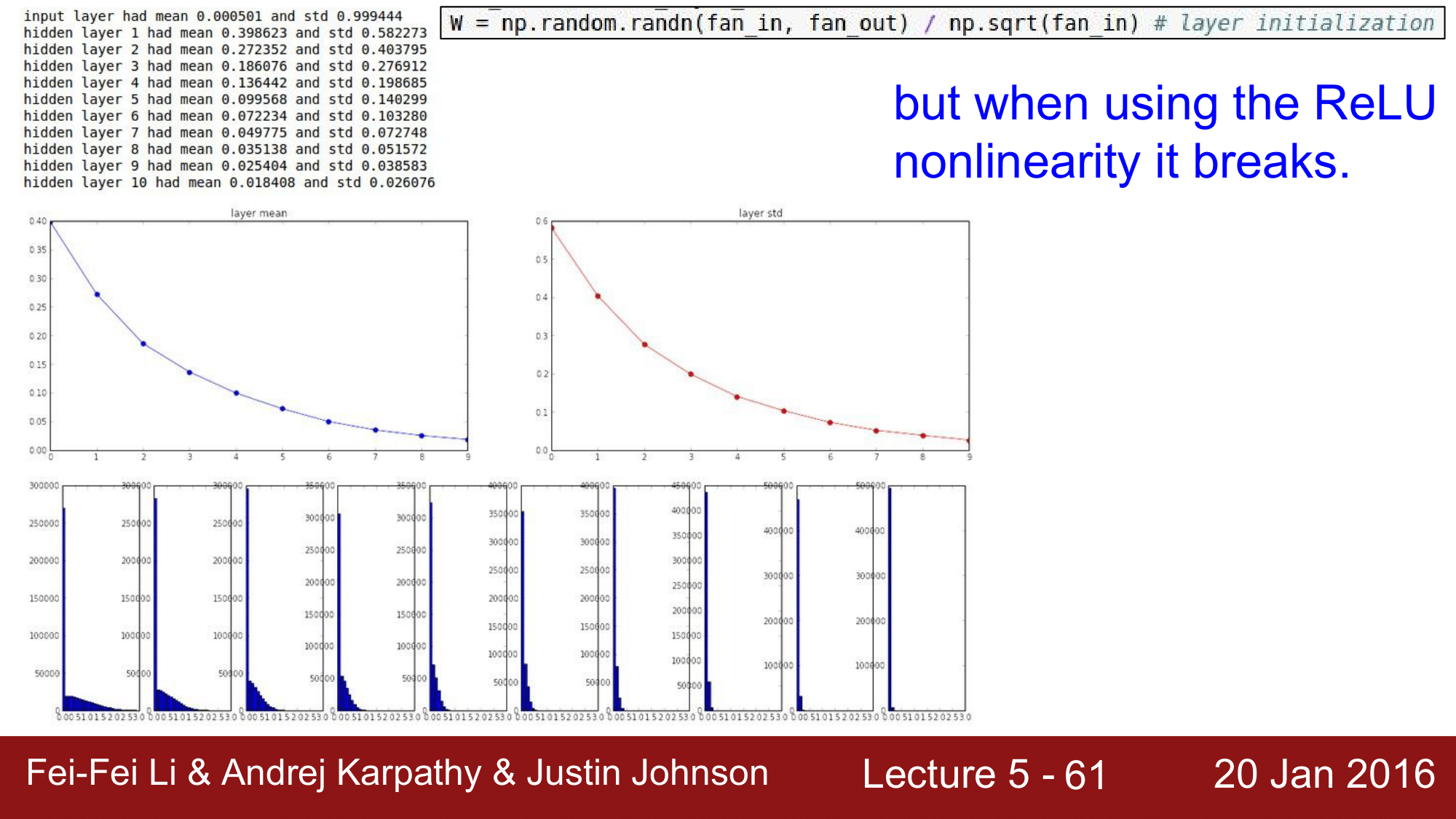
그래서 이를 해결하기 위한 방법으로 2015년에 Kaming He 가 발표한 He 초기값입니다.
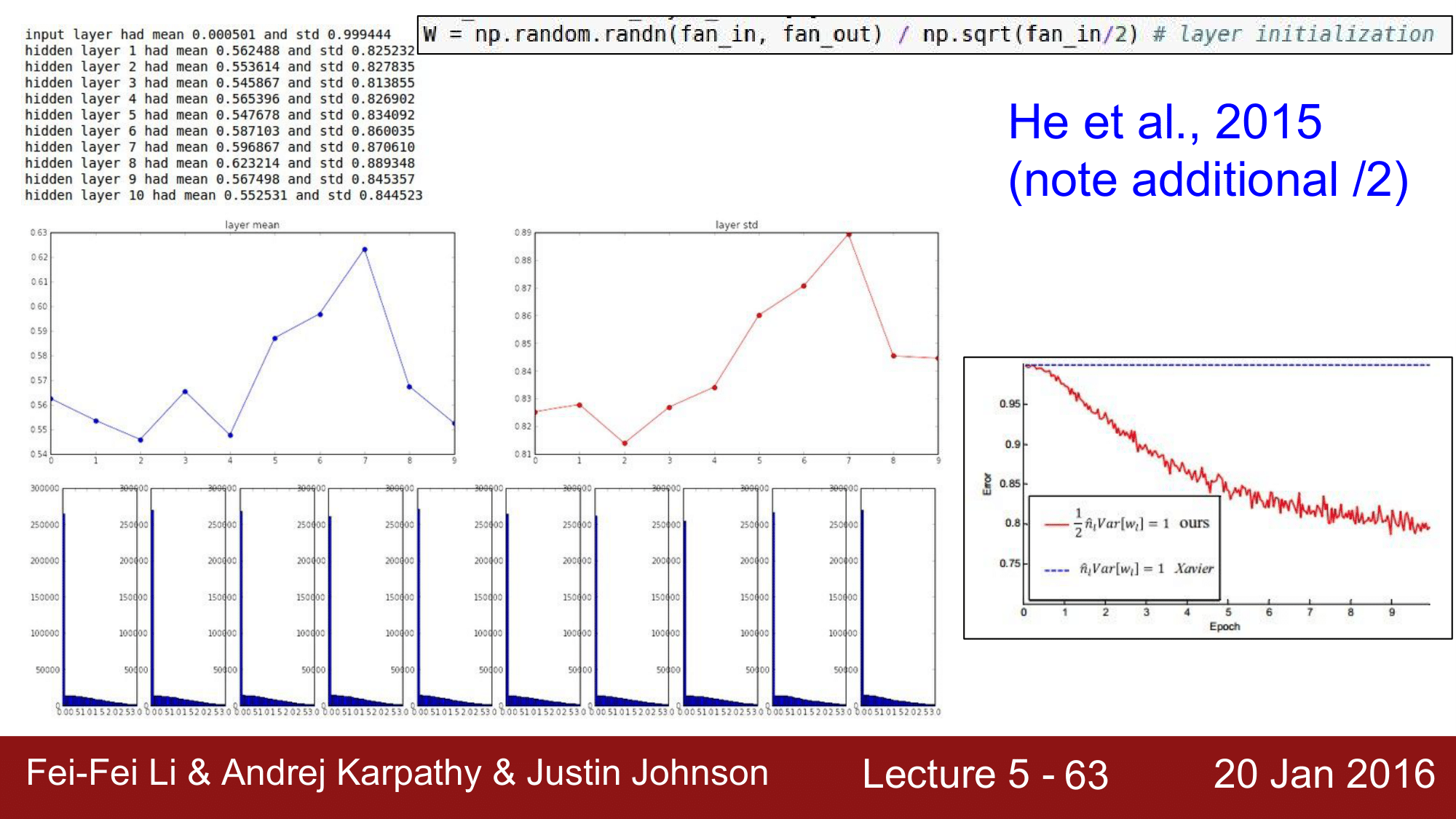
W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in/2) # layer initialization
He 초기값의 경우 자비에르 초기화 방법에 더해 입력값을 2로 나누어 주어 초기화 합니다. 이를 적용하여 테스트해보게 되면 위와 같이 히스토그램 분포가 잘 되는 것을 확인할 수 있습니다.
6. 배치 정규화 (Batch Normalization)
지금까지 매우 간단하게 가중치 초기화 방법에 대해 알아봤는데, 이 분야는 지금까지도 매우 활발하게 연구가 되고 있는 분야입니다. 앞으로도 많은 기술적 발전이 있을 것이라고 기대할 수 있습니다. 하지만 가중치 초기화에 너무 의존하지 않고도 좋은 성능을 낼 수 있는 방법이 바로 배치 정규화 (Batch Normalization) 입니다.
배치 정규화는 기본적으로 Vanishing Gradient가 발생하지 않도록 하는 아이디어 중 하나 입니다. 앞에서는 Vanishing Gradient를 해결하기 위한 방법으로 activation function을 변화시키거나, Weight Initialization을 좀 더 섬세하게 하는 방법을 사용해 왔었는데, 여기서 설명할 배치 정규화 (Batch Normalization)같은 경우 이러한 간접적인 방법을 사용하는 것이 아니라 학습과정 전반을 더 안정화를 함으로써 학습속도와 안정성 모두를 개선하는 근본적인 해결 방법을 제시합니다.
이 방법에 대한 아이디어는 다음과 같습니다.
학습시에 발생하는 불안정함의 이유들은 내부에서 발생하는 covariate shift 떄문입니다. 즉, 각 레이어를 거치면서 입력값의 분포가 달라지는 현상이 발생하기 때문에 불안정화가 일어난다는 것 입니다. 그렇기 때문에 각 레이어를 거칠 때 마다 정규화하는 방식으로 전개하자는 것이 이 방식의 핵심 아이디어가 됩니다.
각 레이어에서 정규화를 하더라도 여전히 미분 가능한 함수라서 순전파와 역전파에도 아무런 문제가 없기 때문에, 이를 그냥 적용하면 된다는 것입니다.
그래서 아래 수식을 이용하여 각 layer 의 output에 정규화를 적용을 하는 것입니다.
\[\hat{x}^{(k)} = \frac{x^{(k)} - E[x^{(k)}]}{\sqrt{\text{Var}[x^{(k)}]}}\]위 함수를 적용하는 방식은 다음과 같습니다.
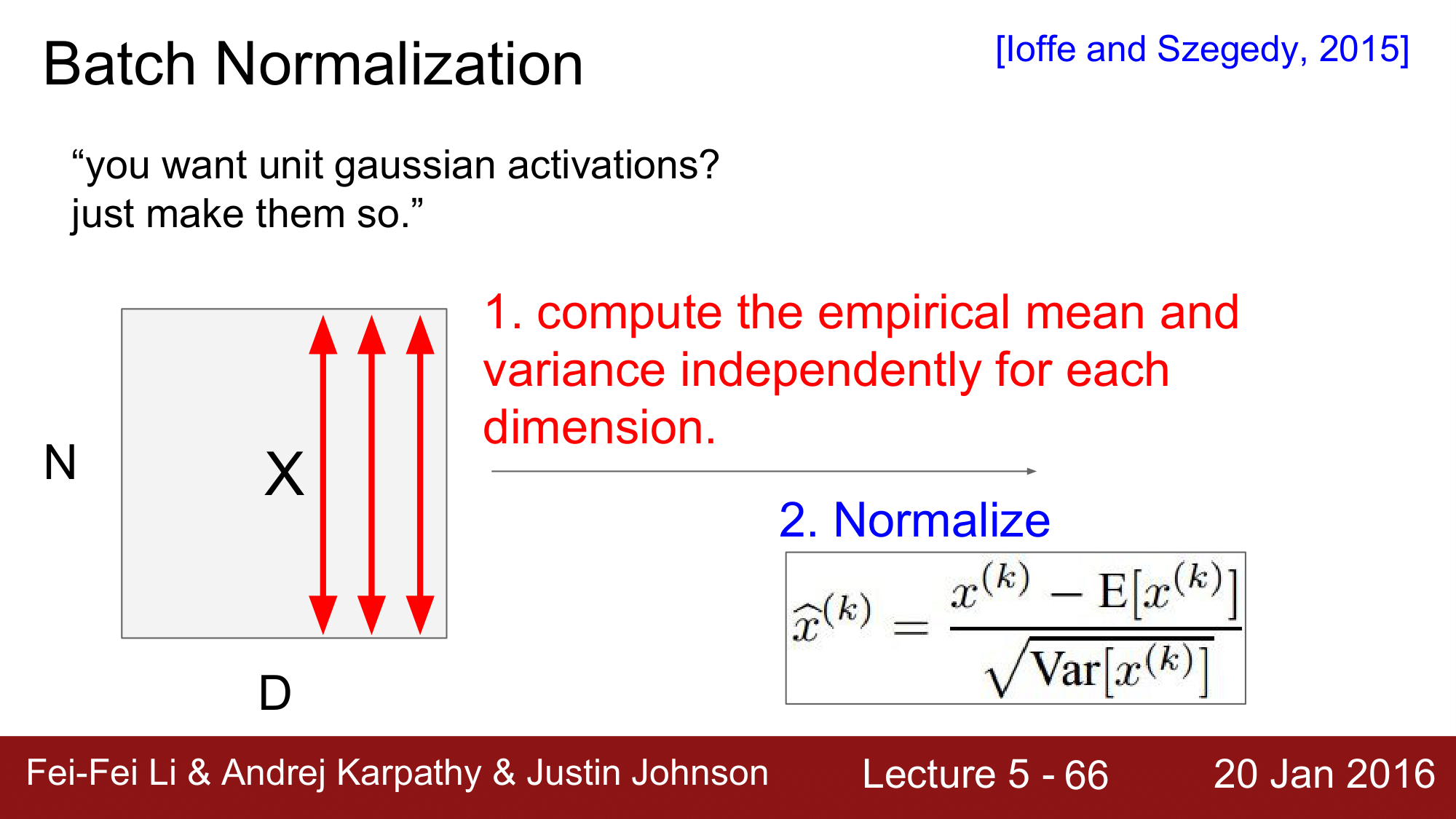
배치 정규화라는 이름에서 알 수 있듯이, 정규화를 모든 값에 대해 적용하는 것이 아니라 미니배치에 적용을 하는 것 입니다.
N(배치 내의 데이터 수) x D(feature 수) 의 형상을 갖는 데이터 X가 있을 때, 이 배치에 대한 평균과 분산을 구해 정규화를 해주는 방식입니다.

배치 정규화는 일반적으로 위 그림과같이 FC (Fully-Connected) Layer와 activation function(여기에서는 $tanh$)사이에 구성됩니다.
그런데, 배치 정규화를 통한 unit gaussian을 nonlinearity로 전달하는 것이 과연 적합한지에 대해서 생각해보아야할 필요가 있어보입니다.

하지만, 배치 정규화에서는 이러한 적합성조차도 학습에 의해 가능하다고 합니다.
그래서 두 단계로 나누어서 보게 되면, 첫 번째 단계에서는 정규화 식을 통해 Normalize를 진행하고, 두 번째 단계에서는 정규화된 결과를 다시 조정할 수 있게 하는 방식으로 이루어 집니다.
두 번째식에서의 $\gamma$는 정규화된 결과에 대해 scaling을 하는 변수이고, $\beta$는 shift를 하는 변수입니다. 이 두 변수는 학습을 통해 결정하게 되고, 배치 정규화를 아예 무효화할 것인지를 결정할 수 있습니다.
각 변수의 값이 오른쪽에 있는 식 처럼 된다면, 정규화의 효과가 상쇄가 되는 방식으로 정규화의 정도를 조절할 수 있습니다.
실제 과정은 다음과 같은 방식으로 진행됩니다.

평균과 표준편차를 구해 정규화를 진행하고, 마지막 단계에서 scale과 shift를 적용을 하는 방식입니다.
결과적으로 배치 정규화는 network상에서 gradient의 흐름을 개선해주고, 학습률(learning rate)이 다소 큰 값을 갖더라도 이를 허용해 줌으로써 보다 빠른 학습을 가능하게 해줍니다. 가장 핵심이 되는 것은 초기화에 대한 강한 의존성을 줄여준다는 것입니다.
이외에도 regularization 효과와 Dropout의 필요를 약간 줄여주는 효과를 줍니다.
배치 정규화를 하면서 한가지 주의할 점은, training 시와 test 할 때 정규화가 조금 다른 방식으로 동작한다는 것입니다. training 시에는 배치를 기준으로 평균과 표준편차를 구하게 되고, test 시에는 전체를 기준으로 값을 구하게 되는 차이점이 있습니다. 이러한 차이점 떄문에, 학습을 할 떄 mean 과 std를 미리 계산해두고, test 시에는 배치가 아닌 전체에 대해 mean 과 std를 계산을 해준다고 생각하면 됩니다.
7. Babysitting the Learning Process
지금 부터 학습과정을 어떻게 시작해나가야 하는지에 대해 설명하겠습니다.
간단하게 과정을 소개하자면, 우선 전처리를 하고 Neural Network의 구조를 결정하고, loss가 정상적으로 변화하는지 확인한 다음, 트레이닝 데이터 셋의 일부분을 이용하여 overfitting이 일어나지 않는 지 확인해주고, 마지막으로 learning rate를 찾아가는 순서로 진행합니다.
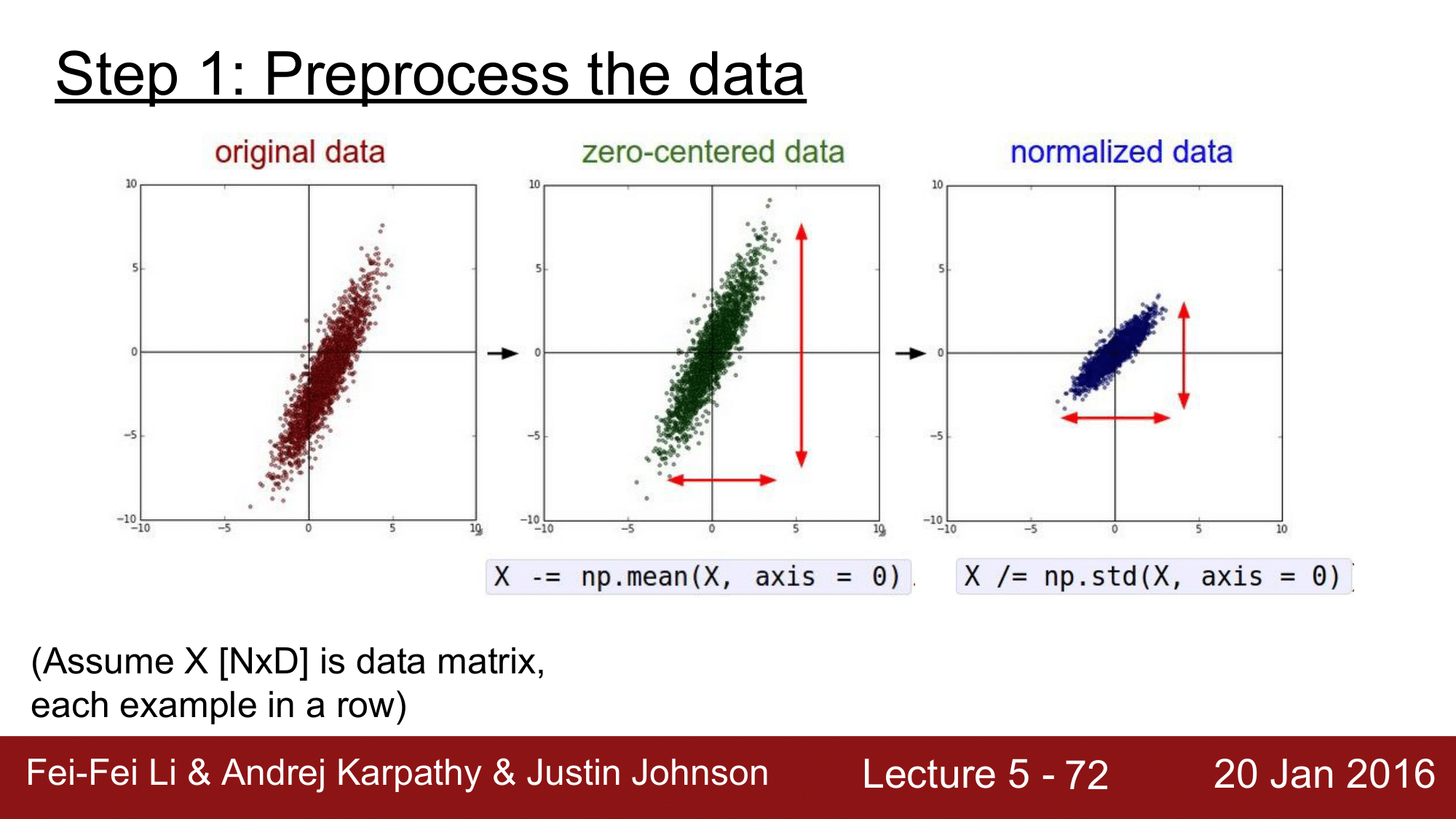 일단 데이터를 전저리 하는 단계에서는 앞에서 언급했듯이, 이미지에 대해서는 zero-centered 하는 것이 중요합니다. 그렇기 떄문에 이를 수행해줍니다.
일단 데이터를 전저리 하는 단계에서는 앞에서 언급했듯이, 이미지에 대해서는 zero-centered 하는 것이 중요합니다. 그렇기 떄문에 이를 수행해줍니다.
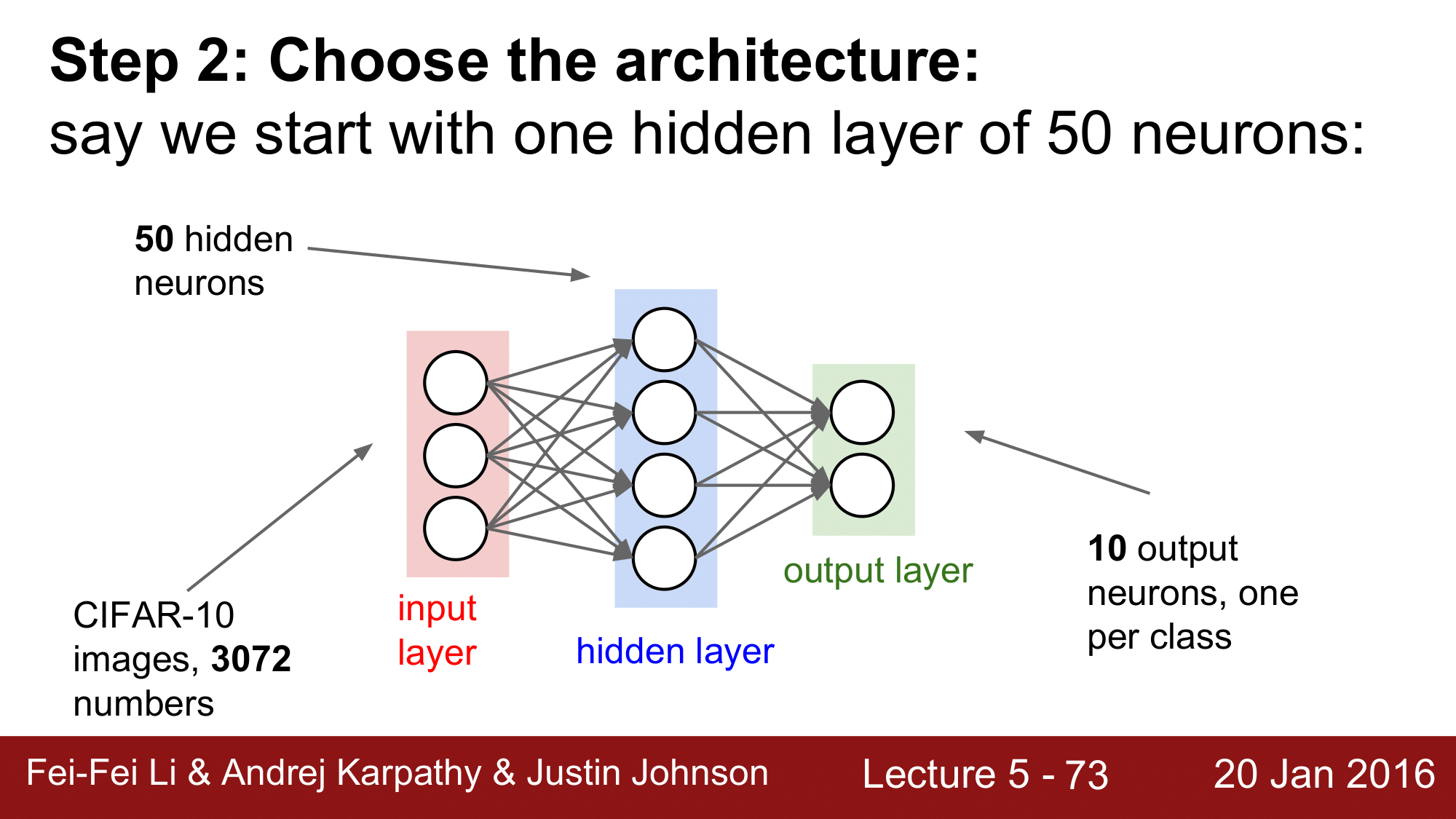
그 다음으로 Architecture를 결정해주게 됩니다. hidden layer를 몇 개를 둘 것인지, 각 레이어에는 몇 개의 노드를 둘 것인지를 결정해줘야 합니다.

위 Network의 경우 두 가지 레이어로 구성되어 있습니다. 이때 regularization을 0으로 disable 해준 상태에서 시작과 동시에 loss를 구하게 됩니다. 이 과정은 앞에서 설명드렸듯이 sanity check를 하는 것입니다. 위 예시에서는 CIFAR-10을 사용하여 10개의 클래스로 분류를 하기 때문에 $-ln(Number of class)$에 의해 $-ln(\frac{1}{10}) = 2.3$이 되어 제대로된 loss 값이 나왔음을 확인 할 수 있습니다.

그 다음 단계에서, regularization을 0이 아닌 1e3으로 설정하면 loss 가 올라가는 것을 확인할 수 있습니다.

본격적인 학습을 시작하기 전에, 전체 데이터 중 일부 데이터를 취합니다.
예를 들어, 20개의 데이터를 취하고 regularization을 꺼준 상태에서 SGD를 사용합니다. 이렇게 일부의 데이터 만으로 학습을 진행하게 되면 반드시 overfitting이 발생하게 됩니다.
위의 코드에 대한 실행 결과를 보게 되면, loss 는 0에 근접하고 acc는 1.0인 것을 확인 할 수 있습니다. 이렇게 오버피팅이 일어났음을 확인 할 수 있습니다.
이 때 만약 오버피팅이 일어나지 않으면 뭔가 문제가 발생한 것이고, 오버피팅이 일어났다는 것은 backpropagation, weight update가 잘 동작하고 있고, 앞에서 설정한 learning rate도 크게 문제가 없다는 것이 됩니다.

여기에서 주목해야 하는 부분은 lr 을 1e-6라는 매우 작은 숫자로 설정했다는 것 입니다.
위 코드에 대한 학습 결과를 보게 되면, cost 가 거의 감소하지 않음에도 불구하고 acc가 증가하는 것을 확인할 수 있습니다.
위와 같은 결과가 나오게 되는 이유는, 학습을 시작할 떄 굉장히 diffuse한 score로 시작하게 됩니다. 이때 lr이 굉장히 작은 값으로 설정되어 있어 cost의 변화는 거의 없지만 score는 약간씩 변화하게 되어 결과적으로 acc가 조금씩 증가하게 되는 것입니다.
실제로, loss가 감소하지 않는데도 training accuracy가 어느 정도 까지 증가하는 현상은 일반적으로 발생하는 현상입니다.
그렇다면 위와는 반대로 learning rate에 굉장히 큰 값을 주게되면 어떻게 되는지 한 번 보겠습니다.

위 처럼 lr로 1e6을 주게 되면, cost는 NaN(Not a Number)값이 나오게 됩니다. 이는 언제나 lr이 높다 라고 이해를 해도 좋습니다.
그렇다면 lr을 3e-3으로 주게 되면 어떻게 되는지도 한 번 살펴보겠습니다.

결과를 보게 되면, cost 즉 loss 가 inf로 explode 하는 것을 확인할 수 있습니다. 이는 3e-3이라는 값도 여전히 매우 높다는 것입니다.
지금까지의 결과로 미루어 봤을 떄, 위 모델에 적합한 learning rate은 아마도 [1e-3, 1e-5]의 범위 어딘가에 있다는 것을 알 수 있고, 이에 대한 정확한 lr를 결정하는 것은 결국 cross-validation을 통해 결정해야 된다는 점입니다.
때문에, cross-validation을 통해 하이퍼파라미터 검증해야 하는 방법을 지금 부터 알아보겠습니다.
8. 하이퍼파라미터 최적화 (Hyperparameter Optimization)
여기에서는 learning rate과 regularizaton term을 결정하는 방법을 중심으로 알아보겠습니다.
교차 검증 전략 (Cross-validation strategy)
우선 cross-validation을 하는 전략입니다.

coarse 하게 시작해서 이 것을 finetunning 해 나가자라는 방식으로, 첫 단계에서는 반복을 너무 여러번 하지 않는 것 입니다. epoch을 작은 숫자를 주어 몇 번만 반복을 하고 파라미터로 어떤 값을 사용해야 하는 지에 대한 감을 잡으면, 두 번째 단계에서 learning time을 좀 더 길게 해주고, 세부적인 하이퍼파라미터 탐색을 수행하는 것입니다.
예시) Run coarse search for 5 epochs
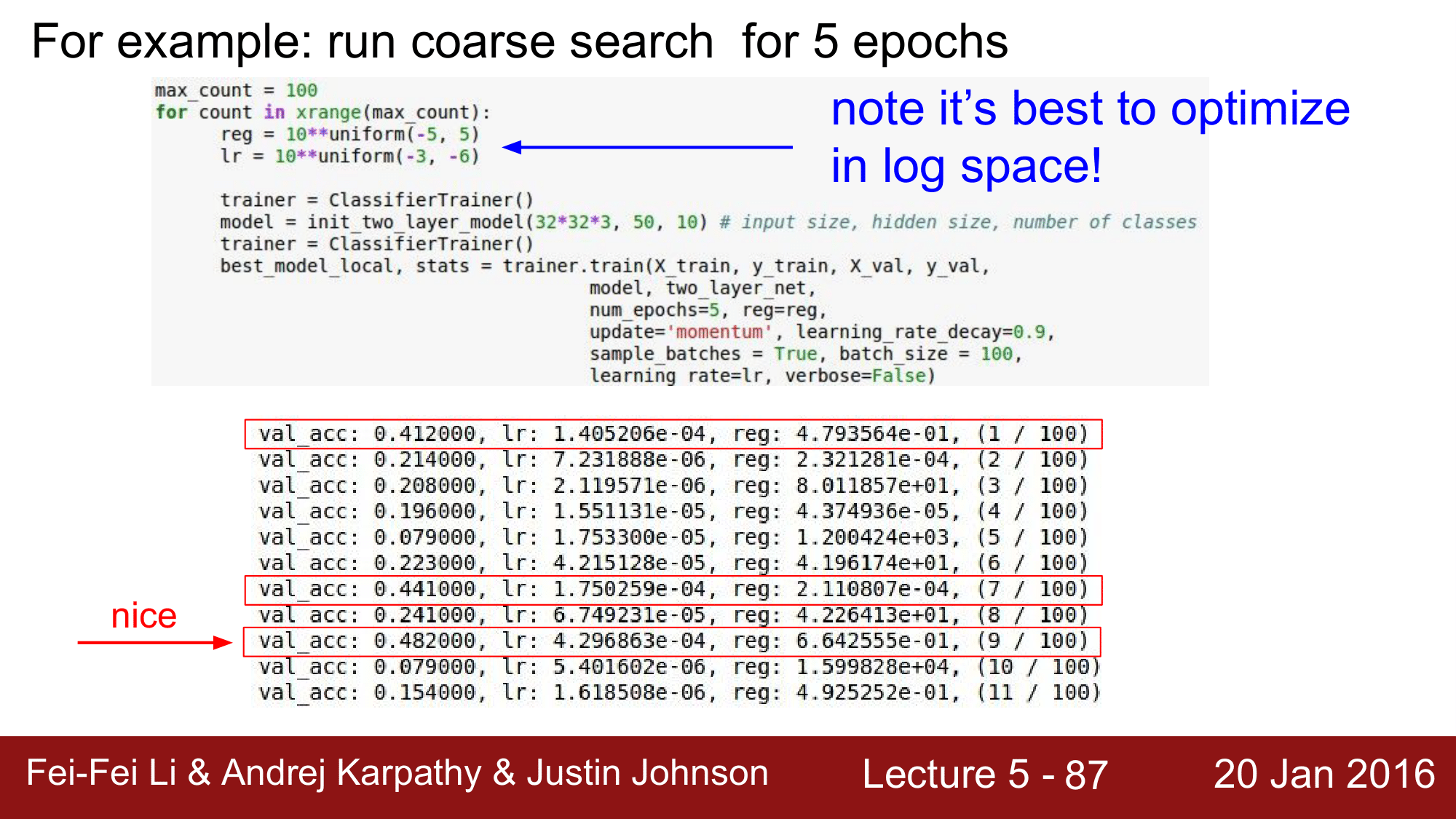
위의 예는, 1단계로 coarse한 탐색을 하는 예시입니다.
regularization 값을 uniform을 통해 범위 내의 스칼라 값을 받아 사용을 하도록 했습니다. 이 떄 10의 자승을 이용하여 log space에서 최적화를 할 수 있도록 해줍니다.
위의 결과를 통해 도출된 최적의 값에 대한 후보들을 추출하여 다음 단계로 넘어갑니다.
예시) Run finer search

앞에서 추출한 후보 값들을 통해 범위를 위와 같이 다시 설정하여 테스트를 합니다. 위의 결과에서 알 수 있듯이 이전의 결과에 비해 더 높은 정확도를 갖는 후보 군들을 확인할 수있습니다. 이는 좋은 방향으로 후보군을 좁혀나가고 있다는 의미 입니다.
그런데 위의 결과에서 주의할 점이 있습니다. 바로 lr이 위에서 설정했던 [1e-3, 1e-4]범위의 종단 부분에 위치해있다는 점입니다. 위와 같은 결과는 설정했던 범위가 조금 잘못되었을 수 도 있다는 의미이기 때문에 해당 값을 -2.5, -4 정도로 수정해야 하는 것을 고려해야 한다는 것을 뜻합니다.
이렇게 하이퍼파라미터를 탐색해나가는 과정은 특정 범위 내에서 값을 랜덤하게 골라옵니다. 이러한 방식을 Random Search라고 합니다. 이와는 다른 방법으로 Grid Search라는 방법이 있습니다.
Ramdom Search vs Grid Search
Grid Search는 Random Search처럼 랜덤하게 값을 찾아나가는 것이 아니라 동일한 간격으로 모든 범위를 커버할 수 있도록 탐색하는 방식입니다. 언뜻보면 Grid Search 가 더 합리적으로 보일 수 있지만, 매우 좋지 않은 방법입니다.

Grid Search에 문제가 있다는 것은 많은 상황에서 특정 파라미터가 다른 파라미터보다 중요하다는 것입니다. 그런데 이를 무시하고 등간격으로 탐색을 진행하게 되면 오히려 최적화된 파라미터를 찾지 못하게 되는 상황이 발생할 수 있다는 것입니다.
예를 들어, 좌측 이미지에서 2번 column의 row를 각 1, 2, 3번이라고 하고, loss function의 성능이 x차원에 대한 함수라고 한다면, 각 1, 2, 3의 값은 모두 같은 값을 갖게 되기 때문에 결국 좋은 정보를 찾아내는 것이 불가능 하게 된다는 것입니다.
결론적으로 learning rate이나 regularization과 같은 하이퍼파라미터의 최적값을 구하는 경우에 절대로 Grid Search 를 사용하면 안되고, 언제나 Radom Search를 사용해야 한다는 것입니다.
하이퍼파라미터
따라서 딥러닝을 하는데 있어서 결정해햐하는 하이퍼파라미터는 다음과 같습니다.
- network architecture (Number of hidden layers and Number of Nodes for each layers, model …)
- learning rate, it’s decay schedule, update type
- regularization (L2 or Dropout Strength …)

Andrej Karpathy 교수의 경우 하이퍼파라미터의 값을 설정하기 위해 70여개의 머신을 사용한다고 합니다.
모니터링 대상 (Monitoring Target)
Loss
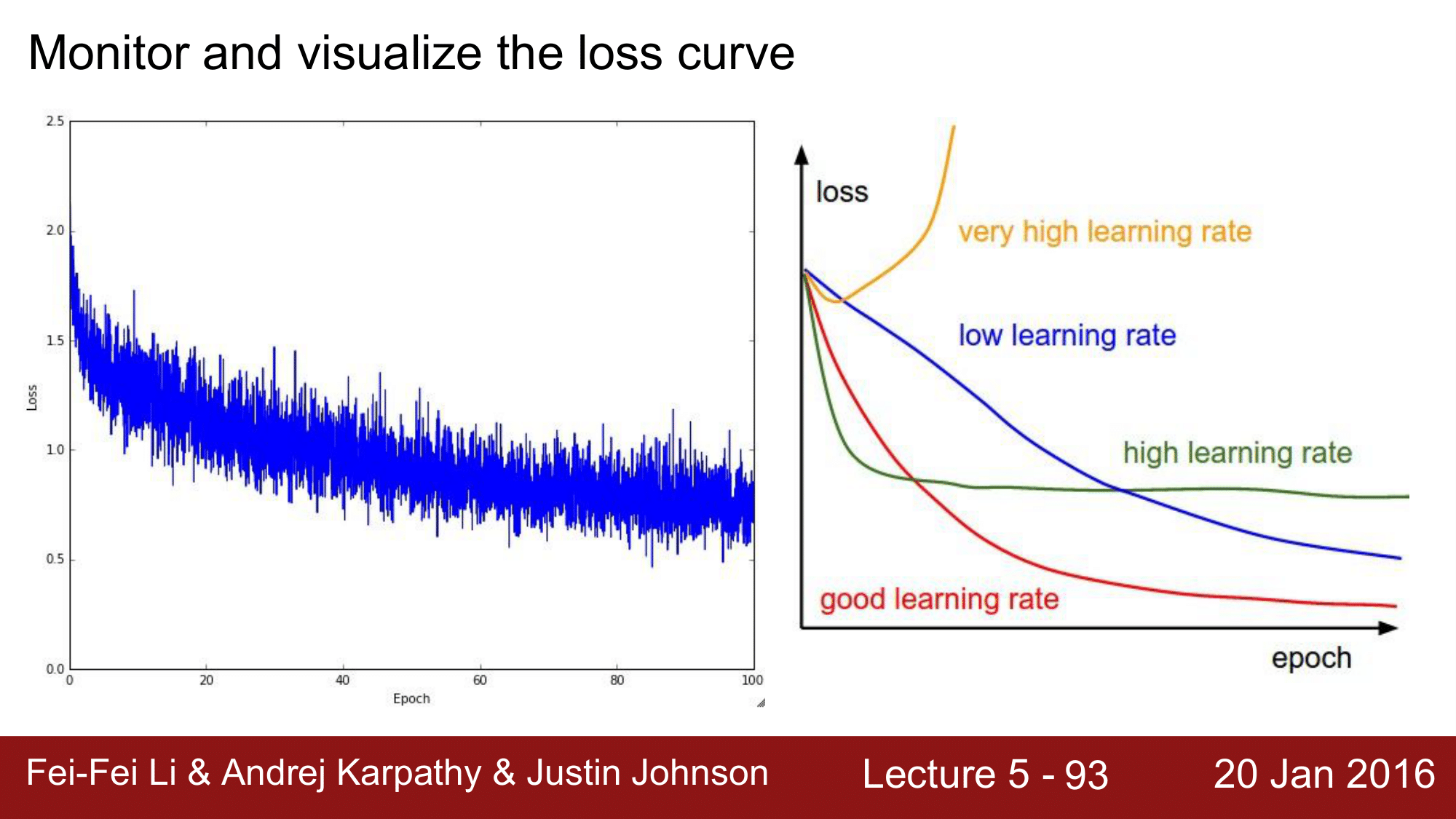
위의 모니터링에서는 learning rate이 너무 낮다는 것을 확인할 수 있습니다. 왜냐하면 convergence하는 rate이 굉장히 낮기 때문입니다. 따라서 좀 더 빠르게 convergence할 수 있도록 lr을 좀 더 높혀야한다는 것을 생각해볼 수 있습니다.
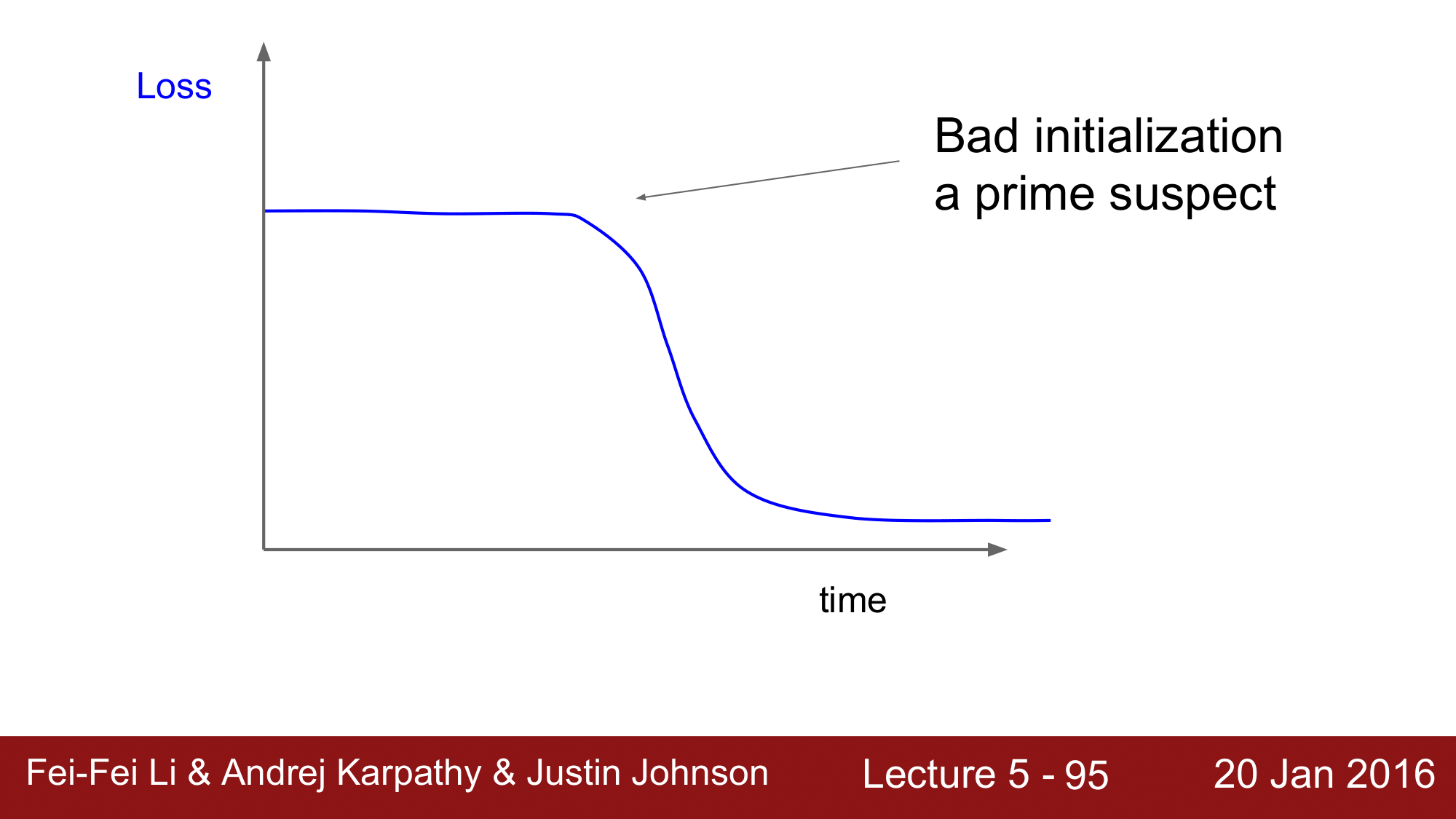 위의 경우는 아마도 초기화가 잘못된 것을 의심해 볼 수 있는 그래프 입니다. 즉, 가중치 초기화에 실패하여
위의 경우는 아마도 초기화가 잘못된 것을 의심해 볼 수 있는 그래프 입니다. 즉, 가중치 초기화에 실패하여 gradient가 거의 흘러가지 않는 (0에 가까운) 상황인 것입니다. 그렇기 때문에 loss 가 정체되어 거의 변화하지 않다가, 어느 시점이 되면 누적된 gradient가 threshold 값을 넘어가면서 급격하게 loss 가 변화하는 것이라고 추측해 볼 수 있습니다.
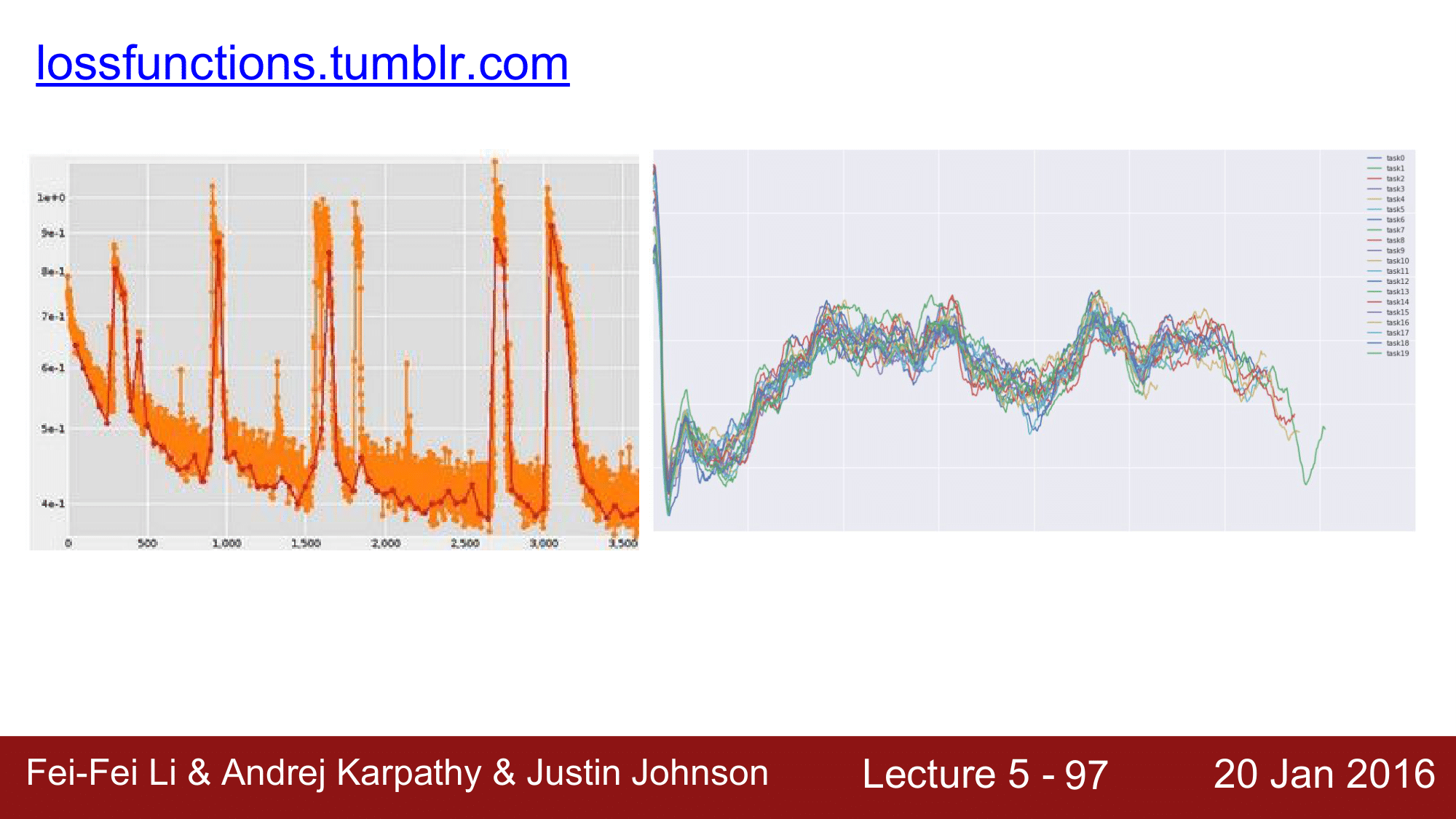
위 그래프는 강화학습을 할 때의 loss 변화에 대한 그래프입니다.
강화학습은 정해진 데이터 셋을 가지는 것이 아니라 에이전트가 환경과 계속해서 상호작용을 하게 됩니다. 예를 들어 agent가 미로를 탐색하는 것을 생각해보면, 벽을 만나게 되면 페널티를 받아 다른 곳으로 이동하게 되고 또 정책이 변경이 되면 다른 곳으로 이동을 하는 식으로 학습을 합니다. 즉, agent가 익숙하지 않은 input을 받으면 loss 가 올라가고, 그러한 input에 대해 익숙해지면 loss 가 내려가는 과정을 지속적으로 반복하기 때문에 위와 같은 그래프를 확인할 수 있습니다.
Accuracy
loss 외에 두 번째로 모니터링 해야하는 대상은 정확도(Accuracy)입니다.
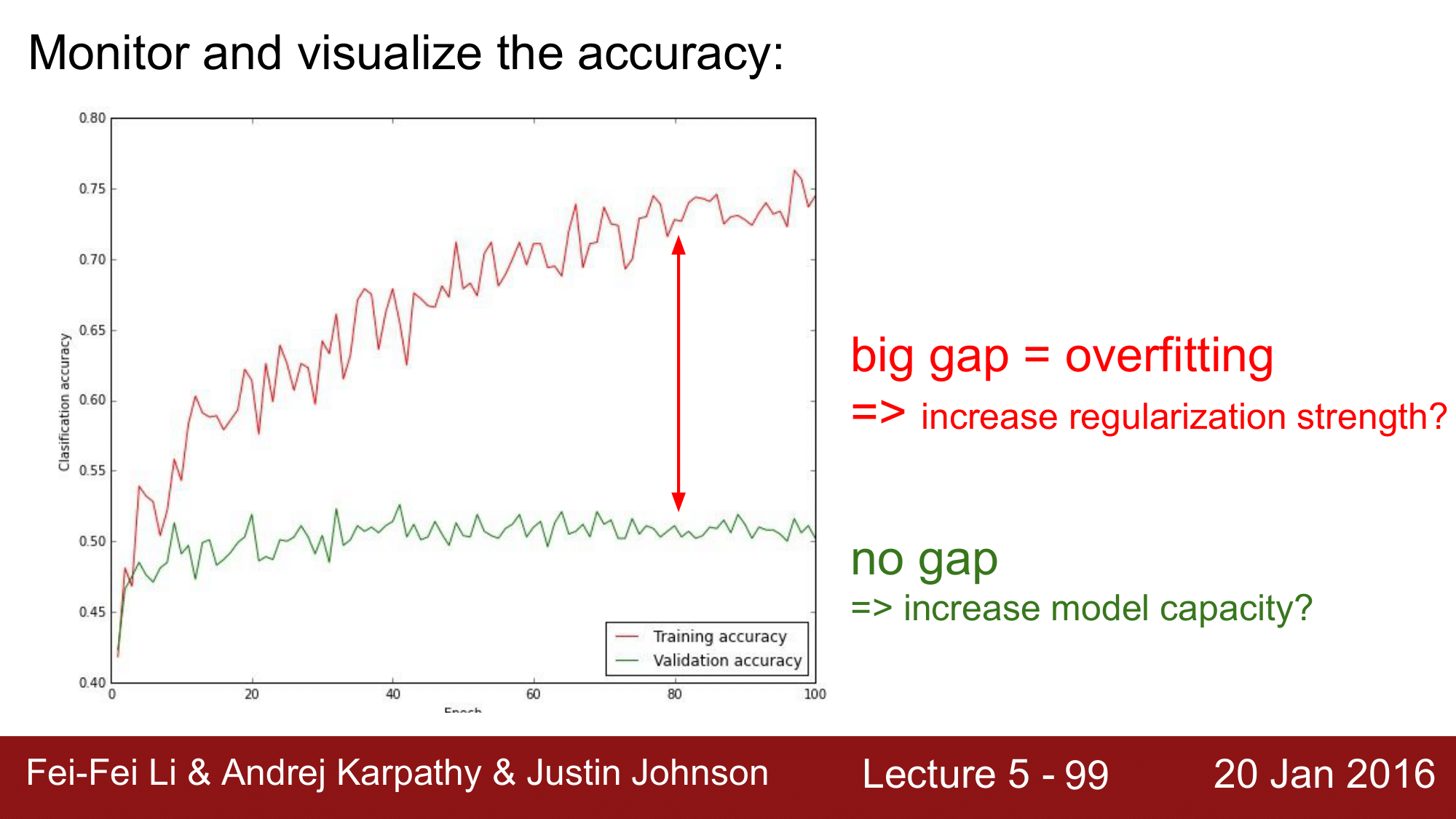
loss function의 단점은 0.278 과 같은 loss 값이 나왔을 때, 해당 값에 대한 해석이 불가능 하다는 것인데, 정확도의 경우 loss와는 다르게 해석이 가능하다는 장점이 있습니다. 이 때문에, loss functino 보다 더 모니터링 대상으로 선호되기도 합니다.
위 그림과 같이, training accuracy와 validation accuracy사이에는 gap 이 생기는 것이 당연합니다.
하지만 위의 경우에는 gap이 너무 크기 떄문에 오버피팅이 되고 있다라고 의심을 해봐야 하는 상황입니다. 이런 경우에는 regularization strength를 증가시켜 오버피팅을 억제해야합니다. 이와는 다르게 gap 이 전혀 없는 경우, model capacity에 문제가 있는 것이기 때문에 이를 증가시켜주어야 합니다.
Ratio of weight updates / weight magnitudes
다음으로 살펴 볼 것은 $\frac{weight updates}{weight magnitudes}$의 비율입니다.

이 비율은 파라미터를 한 번 업데이트할 때의 크기를 전체의 크기로 나눠준 것입니다. 다시말해, w의 update 크기를 w 전체의 크기로 나눠준 것입니다. 이 값은 전반적으로 1/1000정도의 값이 이상적이다라는 것입니다.
Summary
- Activation Functions: use ReLU
- Data Preporcessing (image: zero-centered, subtract mean)
- Weight Initialization (use Xavier init, ReLU -> He init)
- Batch Normalization (use)
- Babysitting the LEaring process
- Hyperparameter Optimization