
해당 포스트는 송교석 님의 유튜브 강의를 정리한 내용입니다. 강의 영상은 여기에서 보실 수 있습니다.
이번 포스트에서는 CNN 을 현실에서 어떻게 사용하는지에 대해서 깊이 있게 알아보도록 하겠습니다.


Making the most of your data
Data Augmentation

CNN 에서는 Image 와 Label 을 CNN 에 feed 해주고, 이로부터 loss 를 계산해 줌으로써 오차를 줄여나가는 최적화 과정을 통해서 Classificaiton 을 하는 식으로 진행했었습니다.
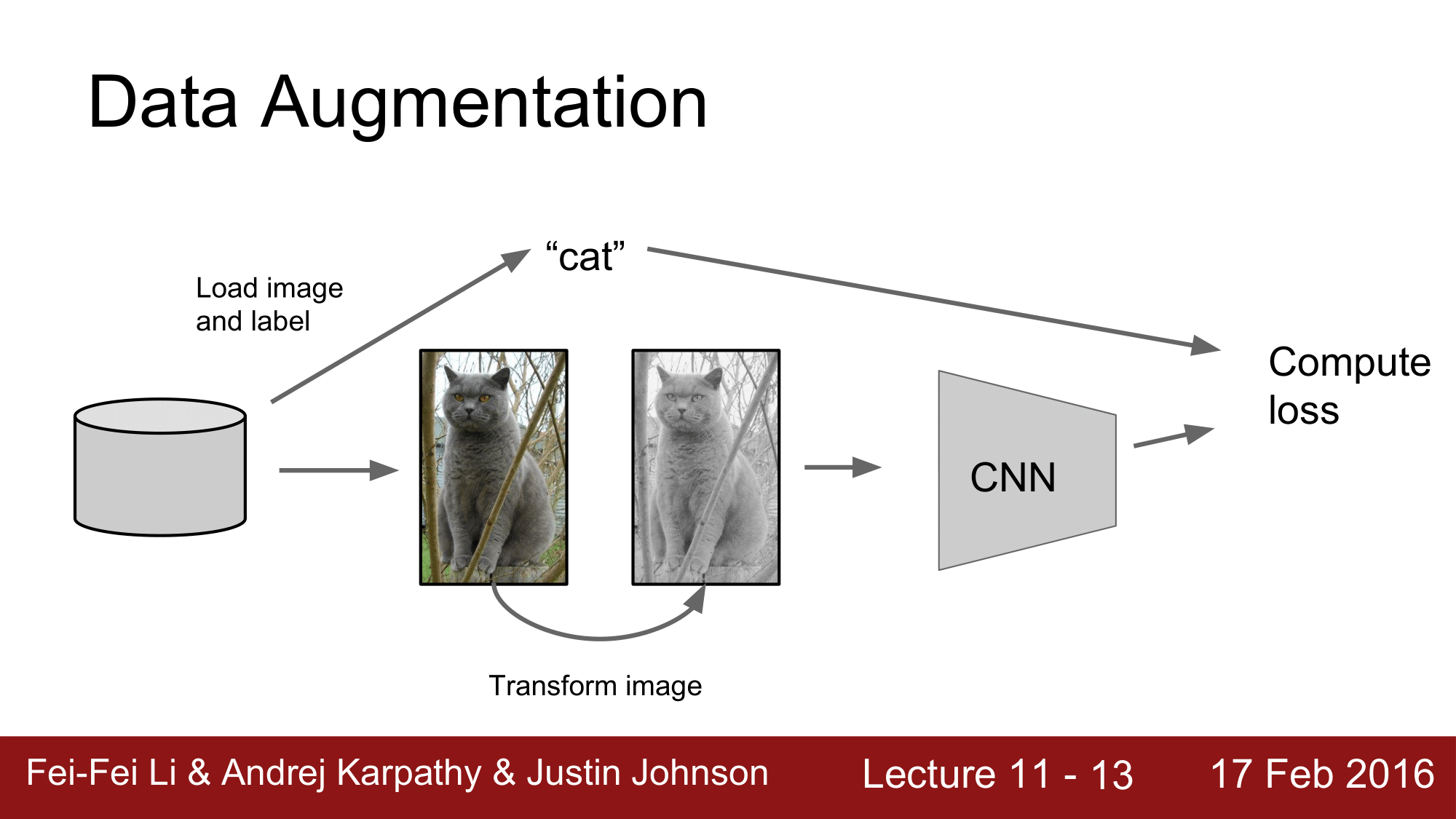
그런데, Data Augmentation 에서는 CNN 에 Image 를 feed 해주기 전에 데이터를 변형해주는 한 가지 과정을 더 거치게 됩니다.
그래서 어떠한 변형 방법을 이용할 것인지 정하는 것이 다양한 Augmentation 의 방법이 되겠습니다.

Data Augmentation 이라는 것은 label 은 변경하지 않고 pixel 의 내용을 바꾸는 것입니다. 이렇게 변경된 데이터를 통해서 학습하고 실제로 매우 폭 넓게 이용되고 있습니다.
1. Horizontal flips

첫 번째로 가장 간단한 방법은 Horizontal flip 즉 좌우반전 입니다. 거울에 비춘것 처럼 변형이 되기 때문에 Mirror Image 라고도 합니다.
2. Random crops/scales

두 번째로, Random 한 crop 과 scale 이 되겠습니다. 이 방법은 먼저 위 그림처럼 랜덤하게 이미지를 잘라주고, scale 도 다양하게 합니다. 이렇게 random cropped/scaled Image 를 학습 시켜줍니다.
예를 들어 ResNet 에서는 [256, 480] 의 범위에서 랜덤하게 수를 선택해주고 training 이미지를 resize 해줍니다. 이때 짧은 부분이 L 이 되도록 하고, 이후 [224 x 224]의 패치를 랜덤하게 샘플링하여 추출해 줍니다. 이렇게 해서 나온 [224 x 224]의 이미지는 ResNet 에 들어가는 이미지의 크기가 되겠습니다.
이처럼 Augmentation 을 이용하면 Training 시에 이미지 전체가 아니라 Crop 된 패치에 대한 학습이 이루어지기 때문에 테스트시에도 이미지 전체가 아닌 정해진 수의 crop 을 이용해서 테스트를 진행하게 됩니다. 즉, 정해진 수의 crop 을 통해 평균내는 작업을 테스트시에 하게 되는 것 입니다.
예를 들어, 우측 이미지에서처럼 서로 다른 5개의 crop 을 가지고 있을 때, 이들을 horizental flip 을 하게 된다고 하면 2 x 5 의 총 10개의 crop 을 얻을 수 있는데, 이들을 평균내주는 작업을 하게 되다는 것 입니다.

다시 ResNet 의 예를 들면, ResNet 에서는 한 걸음 더 나아가서 이미지 resizing 을 {224, 256, 384, 480, 640}의 다섯 가지로 분류하고 각각의 크기에 대해서 [224 x 244] 의 Crop 을 10개를 사용한다고 합니다.

세 번째 방법으로는, Color jitter 입니다. 제일 간단한 방법은 contrast 를 위와 같이 jittering 하여 변경하는 것입니다.
이보다는 다소 복잡 하지만, 많은 경우에 사용되는 방법은 Image 의 [R, G, B] 3개의 채널에 대해서 PCA(Principal component analysis; 주성분 분석)를 이용하는 것 입니다.
PCA 를 굳이 이용하는 이유 직관적으로 볼 때, 이미지의 주성분을 뽑아냄으로써 이미지의 핵심을 잃지 않으면서도 이미지의 개수를 늘려줄 수 있기 떄문
이를 통해, 각각의 채널에 대해서 한 개씩의 principal component direction 을 얻게 됩니다. 이를 따라서 color 의 offset 을 sampling 해준 다음, 이 offset 을 image 모든 픽셀에 더해준다는 것입니다. 이외에도 더 다양한 방법들이 있습니다.

경우에 따라서 창의적인 augmentation 을 수행할 수 있다는 것으로, translation(shift), rotation, stretching, shearing, lens distortions 등 적용해야 하는 데이터 셋의 종류에 따라서 다르게 적용하여 더 좋은 효과를 거둘 수 있습니다.
그래서 나의 데이터 셋에 어떤 invariance 가 필요한지를 잘 파악한 다음에 창의적인 방법을 적용해 볼 수 있습니다.

Augmentation 을 일반적인 theme 으로 생각한다면, 다음과 같이 볼 수 있습니다.
training 과정은 랜덤한 노이즈를 더해주는 과정이 될 것이고, testing 은 노이즈를 average out(평균화)하는 과정이라고 생각할 수 있습니다. 이렇게 하면 앞에서 보았던 Dropout, DropConnect 또한 넓은 의미에서 Data Augmentation 이라고 볼 수 있습니다.
마찬가지로, Batch Normalization 이나 Model ensembles 의 경우도 이와 유사한 효과를 거두고 있다고 생각할 수 있습니다.

정리하자면, Data Augmentation 이라는 것은 매우 구현하는 것이 간단하기 떄문에 사용을 권장한다는 것이고, 특히 데이터 셋의 크기가 작은 경우 유용할 것이며, training 시에는 노이즈를 더해주고 testing 시에는 노이즈를 average out 해주는 그런 framework 이라고 생각할 수 있습니다.
Transfer learning

다음으로 Transfer learning 에 대해서 살펴보겠습니다.
CNN 을 학습시키거나 사용하려면, 굉장히 많은 데이터를 가지고 있어야만한다는 것이 어쩌면 잘못된 믿음일 수 있다는 것에서 출발합니다.

CNN 으로 Transfer learning 을 하는 것을 살펴보게 되면, 우선 위 모델을 ImageNet 에 training 시킵니다.
ImageNet 에 Training 시킨다는 것은 우리가 직접 처음부터 할 수도 있고, 아니면 미리 학습된 model 을 다운로드 받아서 구현할 수도 있습니다.
당연히, 이미 학습된 모델을 다운받아서 하는 것이 훨씬 더 효율적입니다.

그런데 이때, 가지고 있는 데이터셋이 너무 작은 경우 FC-1000 과 softmax 레이어만을 남겨놓고 앞단의 모든 부분을 freeze 해줍니다. 즉, freeze these 에 해당하는 부분은 더 이상 변하지 않게 됩니다. 그렇기 떄문에 ImageNet 과 같은 곳에서 학습해놓은 freeze 부분은 feature etractor 처럼 특징을 추출해주는 역할을 한다고 생각할 수 있습니다.
이렇게 하여 빨간 박스 부분의 레이어만 가지고 있는 데이터 셋을 이용하여 학습을 시키게 됩니다.
다른 관점에서 보게 되면, freeze 되어 있는 부분은 가중치 집합, 체크포인트 같은 것으로 hdd 저장해두는 것이고 아래 빨간 박스부분은 학습시켜야 하기 때문에 memory 에 올라와서 동작한다고 생각할 수 있습니다.
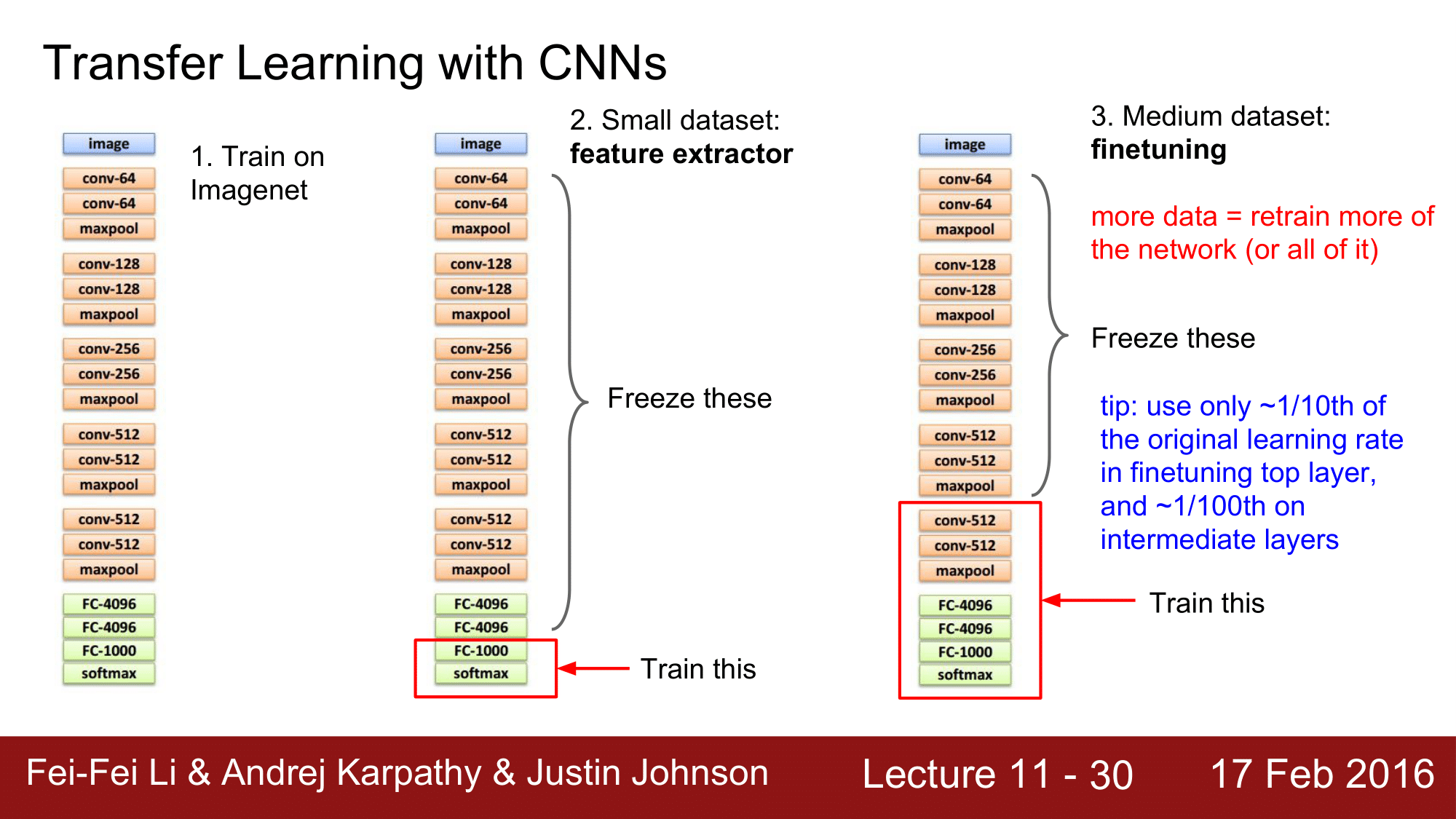
데이터가 작은 경우는 앞에서와 같이 진행이 되는데, 데이터셋의 크기가 아주 크지는 않지만 학습을 못 시킬 정도로 너무 작지도 않는 경우는 finetuning 을 해주게 됩니다.
데이터가 정말 많은 경우라면 1번과 같이 학습을 전체 레이어에 대해서 자체적으로 진행할 수 있고, 데이터가 거의 없는 경우라면 2번과 같이 말단 부분만 학습시키며, 데이터가 더 많은 경우라면 점점 더 위쪽의 레이어까지 학습을 시켜줍니다.
그래서 freeze 하는 영역을 적절하게 데이터의 크기에 따라 선택하고 training 을 시키는 부분도 이에 따라 선택하면 되는 것입니다.
finetuning 을 하는 말단의 레이어의 경우는 learning rate 을 원래의 lr 의 1/10 정도를 사용하고, 중간의 레이어의 경우는 1/100 정도를 사용하는 것이 좋습니다. 그 위의 레이어들은 freeze 했기 때문에 lr 을 0으로 설정해주면 됩니다.
지금까지 transfer learning 을 하는 방법에 대해 알아보았습니다.
이렇게 transfer learning 을 하는 것이 처음부터 학습시키는 것 보다 일반적으로 성능이 잘 나오는 이유는 무엇일까요?
ImageNet에 있는 pretrained 모델을 가져와서 사용한다고 했는데, 그렇게 되면 ImageNet에 있는 Class 와 전혀 무관한 이미지에 대해서도 처음부터 학습시키는 것보다 더 좋은 성능이 나온다고 하는게 좀 이상하게 느껴질 수 있습니다.
pretrained Image(여기에서는 ImageNet)와 매우 유사한 이미지들을 Classify 하는 경우라면, 말단 부분만을 학습시켜도 나름대로 좋을 성과를 얻을 수 있는 것이고, 만약에 pretrained Image 와 전혀 관련이 없는 (ImageNet의 경우 MRI, CT 같은 의료데이터) 이미지를 Classify 하는 경우라면 train 하는 자체 데이터를 상당부분 상위 레이어까지 늘려야 된다고 생각할 수 있습니다.
이렇게 되면 상위단에 전혀 관계없는 이미지를 학습시켰다고 해서 어떻게 MRI 같은 이미지 데이터에 대한 Classify 성능이 좋아지겠는가라는 의문에 도달하게 됩니다.
앞 단의 레이어에서 edge 나 color 같이 gabber filter 같은 low level 의 feature 들을 인식하고, 뒷 단으로 갈 수록 상위 레벨의 추상적인 것들을 인식한다고 했습니다.
이때 low level feature 를 미리 학습해 놓는다는 것은 어떤 이미지를 분석할 때도 도움이 된다는 이유에서 입니다.
이런 이유에서 거의 모든 Transfer learning 이 더 좋은 퍼포먼스를 낸다는 것을 기억하고 활용하면 됩니다.
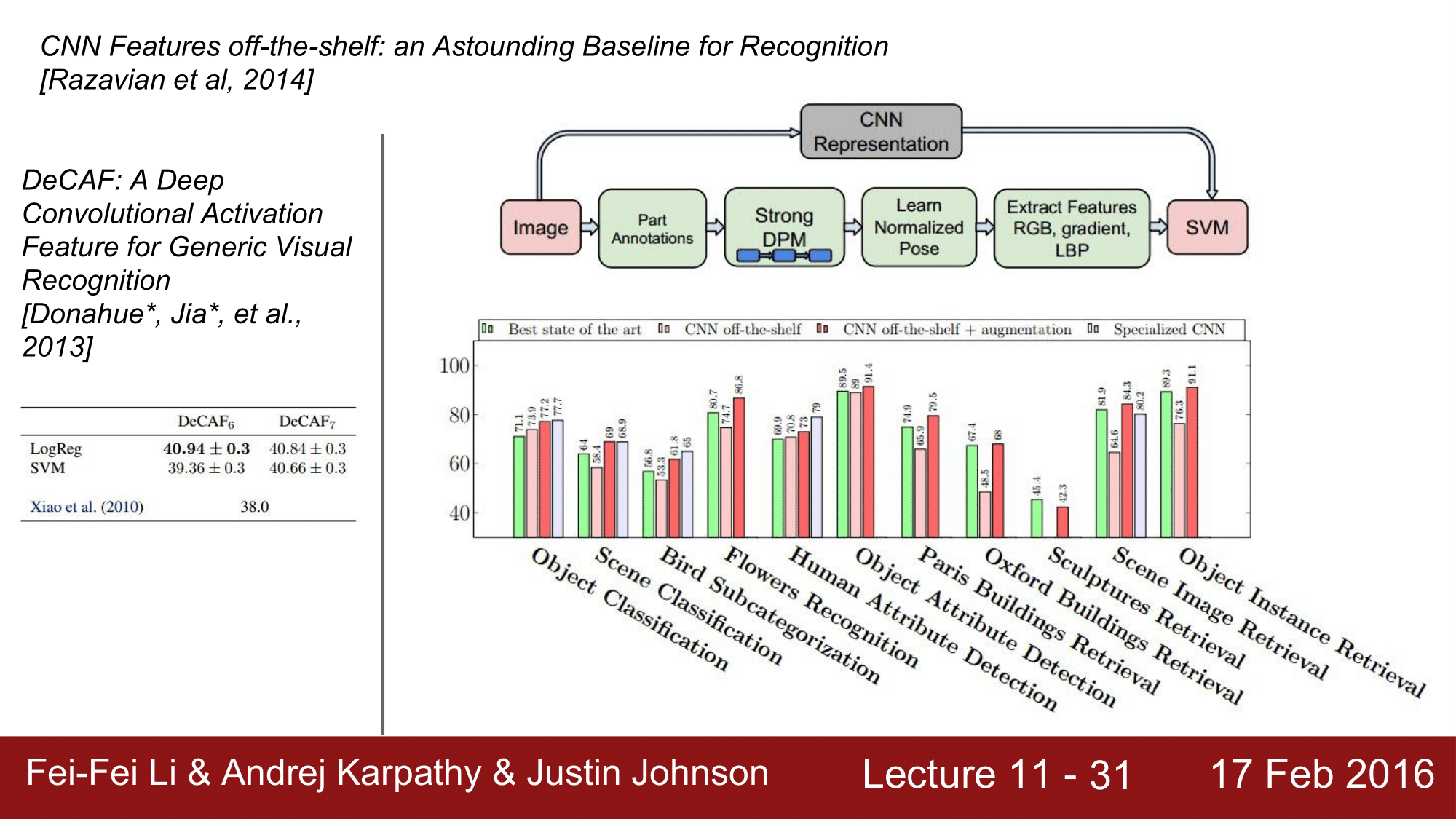
CNN Features off-the-shelf: an Astounding Baseline for Recognition 이라는 논문에서도 앞서 설명한 바와 같이, SOA, CNN, CNN + AUG 를 적용했을 때에 성능을 비교했습니다.
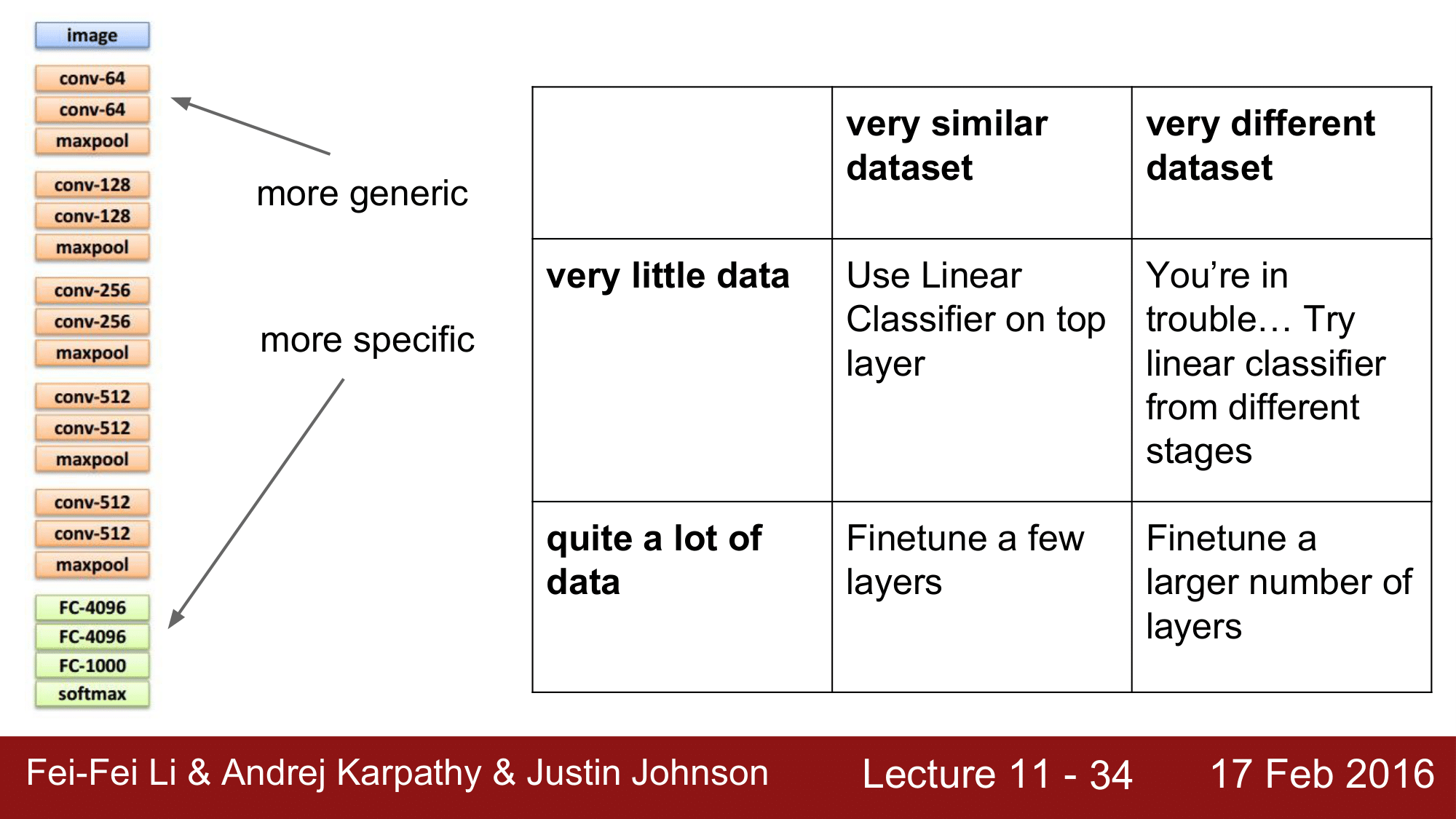
위 테이블에서 x 축은 Data의 유사성 즉 내가 가지고 있는 dataset 이 pretraining 된 dataset 과 얼마나 유사한지에 대한 유사성을 나타내고, y 축은 Data의 수를 나타냅니다. 이때, 각 상황에 대해서 어떠한 전략을 가지고 가야 하는지에 대해서 살펴보겠습니다.
먼저 왼쪽의 figure 을 보게 되면, 위쪽은 좀 더 generic 하고 끝쪽 top 부분은 좀 더 specific 한 양상을 보이게 됩니다.
그래서 데이터의 수는 비록 적지만, 데이터 유사성이 높은 경우라면 top layer 에서 linear classifier 만 이용해도 된다는 것이고, 데이터도 많고 유사한 데이터를 갖는다고 하면 몇 개의 layer 만 fine tunning 해주면 됩니다.
그리고, 데이터의 수도 적고 데이터 유사성도 작은 경우 문제가 좀 힘들어 집니다. 이러한 경우는 figure 에서 학습시킬 부분과 freeze 할 부분의 경계를 상황에 따라서 판단해야 할 것입니다. 앞에서 잠깐 예를 들었던 의료영상같은 경우가 이에 해당할 수 있습니다.
마지막으로 데이터의 수는 많지만 데이터 유사성이 떨어지는 경우라면, 많은 레이어들을 fine tunning 해주는 전략이 필요할 것입니다.

이렇게 CNN에 있어서 Transfer learning 은 마치 표준과 같이 항상 사용해야 하는 것으로 굳어져 있는 상황으로, Obejct detection(Faster R-CNN)의 Convolutional Nerual Network 에서도 Transfer learning 을 사용하고, 오른쪽의 Image Captioning 의 경우에도 CNN 에서는 물론 RNN의 word vector 들에 대해서도 Transfer learning 을 사용합니다.
물론 word vector 들은 word2vec 이라는 것을 이용해서 ImageNet 을 통해서 pretrain 하듯이 word2vec 을 이용해서 word vector 를 이용해서 pretrain 시킵니다.

결론적으로, 프로젝트에 임하는데 있어서 가지고 있는 데이터가 작다라고 한다면, 데이터를 어떻게든 찾아내서 큰 dataset 을 만들거나, 아니면 좀 더 쉬운 방법으로 transfer learning 을 활용해라는 것이 되겠습니다.
이렇게 미리 학습된 모델에 대해서는 Caffe 같은 경우 Model Zoo 라는 pretrained Model 들을 모아둔 library 가 있습니다.
최근에는 TensorFlow, pyTorch, Keras 에서도 Model Zoo 와 같은 library 를 제공하고 있기 때문에 이를 활용하면 됩니다.

지금까지 Augmentation 과 Transfer learning 에 대해서 살펴봤습니다.
이제 부터는 Convolution에 대해서 어떻게 stacking 하고 어떻게 효율적이고 빠르게 연산해나갈 것인지에 대해서 알아보겠습니다.
우선, 어떻게 쌓는 것이 효율적일 것인지에 대해서 알아보겠습니다.
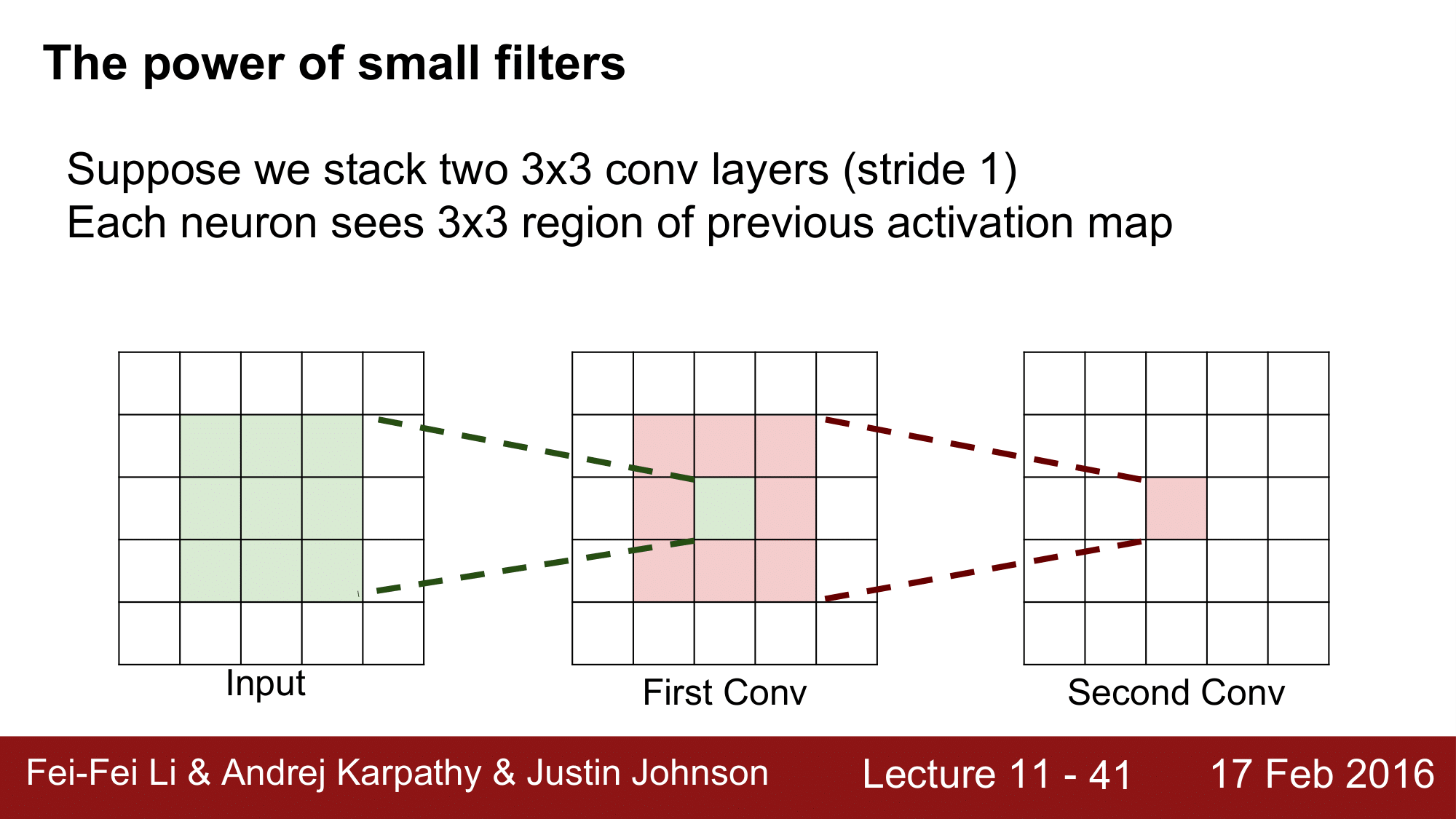
제목에서 부터 알 수 있듯이 small filter 가 얼마나 강력한지에 대해서 앞으로 살펴볼 것입니다.
stride 를 1로 하는 2개의 [3 x 3]의 레이어를 쌓는다라고 할 때, 위처럼 Input, First Conv, Second Conv 로 구성됩니다.
이렇게 되면 Conv 레이어에서 하나의 뉴런은 전 단계에의 Activation Map 에서 [3 x 3]의 지역을 보게 될 것입니다. 위 그림에서 보이다시피 First Conv 레이어의 가운데 뉴런은 전 단계의 [3 x 3]을 보게 되고, Second Conv 레이어의 뉴런 또한 전 단계인 First Conv 레이어의 [3 x 3] 영역을 보는 것을 확인할 수 있습니다.
그렇다면, Second Conv Layer 의 하나의 뉴런은 input 의 어느정도 크기의 region 을 보게 될까요?
바로 [5 x 5]입니다. 왜냐하면 Second Conv 의 뉴런 하나는 First Conv 의 [3 x 3]을 보게 됩니다. 그리고 [3 x 3] 각각의 뉴런이 또 다시 앞단의 [3 x 3]을 보게 돼서 결국은 Second Conv 의 뉴런 하나가 input 레이어의 모든 영역 [5 x 5]를 보게 되는 것입니다.
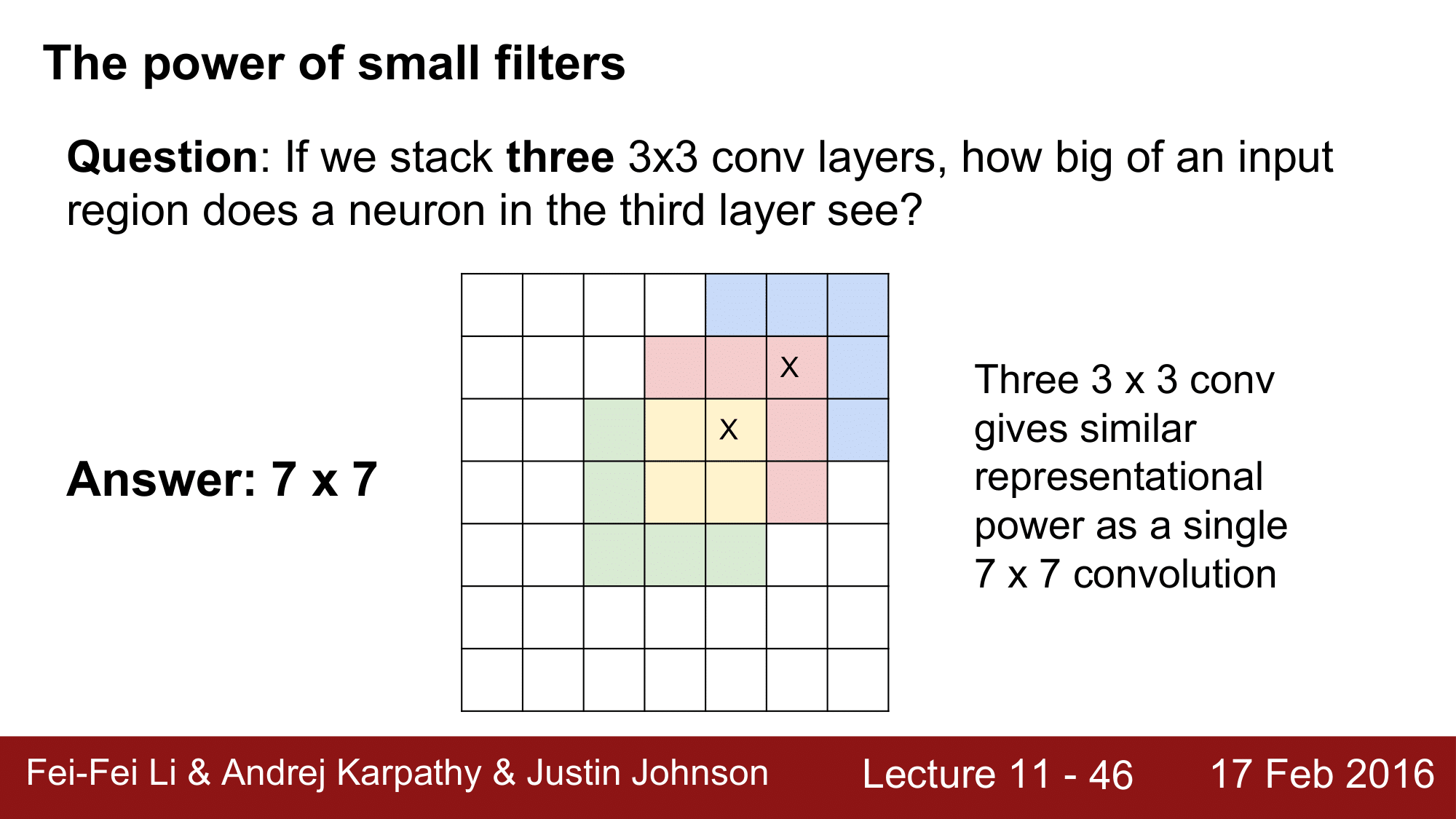
[3 x 3]의 Conv 레이어를 3개를 쌓게 되면 뉴런 하나가 몇개의 레이어를 볼 수 있을 지도 위와 같은 방법으로 해서 [7 x 7]의 영역을 보게 됩니다.
이를 통해 알 수 있는 것은, [3 x 3]의 레이어를 3개를 쌓은 것이 결과적으로 단일 [7 x 7] 레이어와 동일한 representational power 를 가진다라는 것이 되겠습니다.

input 이 H x W x C 라고 하고 depth 를 보존하면서 C 개의 필터를 이용해서 Convolution 을 하려고 한다고 가정해봅시다. (이때, stride 1, padding 은 H, W 를 보존)
앞의 Lecture 7 에서 살펴봤던 내용을 다시 상기시키며 예를 다시 살펴보겠습니다.
input 이 [32 x 32 x 3] 이고 [5 x 5] 크기로 하는 10개의 필터, stride 1, padding 2 라고 할 때, 파라미터의 개수는 $(5 \times 5\times3+1)\times10=760$가 됩니다.
이를 염두에 두고 [7 x 7]크기를 갖는 하나의 CONV 레이어와 [3 x 3]크기를 갖는 세 개의 CONV 레이어를 비교해보겠습니다. 왼쪽의 경우에 weight 의 개수는 $7 \times 7 \times C \times C$ 가 되고, 오른쪽의 경우 $3 \times 3 \times C \times C \times 3$
결국 왼쪽은 $49C^2$ 오른쪽은 $27C^2$이 되어 하나의 [7 x 7] 필터를 갖는 것 보다 3개의 [3 x 3]필터를 갖는 것이 더 적은 파라미터수를 갖게 되고 3번의 layer 를 거치면서 ReLU 와 같은 것들을 통해 Non Linearity 도 강화가 되는 여러 방면에서의 좋은 효과를 갖게 되는 것입니다.
이게 바로 작은 필터의 강력함이 되겠습니다.
여기서 그치지 않고 한 가지 더 보겠습니다.

각 방식에서 얼마나 많은 곱셈연산을 하는지 계산을 해 보게 되면 왼쪽의 경우 $49HWC^2$이 되고 오른쪽의 경우 $28 HWC^2$이 되므로 이 역시 오른쪽이 훨씬 더 좋다는 것을 알 수 있습니다.
정리하자면, 작은 필터를 사용하게 되면 파라미터수가 적고 곱셈연산도 적으며 Non Linearity 가 강화가 되기 때문에 여러면에서 좋다는 것이 되겠습니다.
그런데 왜 [3 x 3]으로만 하는지 의문이 들 수 있습니다. [1 x 1]로 내려가면 더 좋은 결과를 볼 수 있지 않을까라는 의문이 들 수 있습니다. 이에 대해서 알아보겠습니다.

H x W x C 의 크기를 가지는 input 이 있고, 여기에 Conv 를 [1 x 1]로 주고 filter 를 C/2 로 주도록 하겠습니다.
여기서 conv 를 [1 x 1]로 주게 되는 것을 bottleneck Architecture 라고 합니다.

다음 단에서는 Conv 를 [3 x 3]을 주고 filter 를 C/2 로 앞의 결과과 같이 H x W x (C / 2) 라는 결과를 얻게 됩니다.
그 다음으는 [1 x 1]의 Conv 와 C 개의 필터를 이용해서 dimension 을 H x W x C 로 다시 복원합니다.
이렇게 [1 x 1] Conv 를 곳곳에 활용하는 것을 Netowork in Network 또는 Bottleneck Convolution 이라고 합니다.
이런 구조들은 GoogleNet 이나 ResNet 과 같은 데에 이용이 되면서 유용성이 많이 입증되어 있습니다.

이렇게 Bottleneck 을 이용한 Convolution 과 [3 x 3]을 이용한 단일 Convolution 을 비교를 해보게 되면 결과는 동일하게 H x W x C의 결과를 얻는 것을 볼 수 있습니다.
하지만, 여기에서 사용되는 파라미터의 수를 계산해보게 되면 다음과 같이 됩니다.

Bottleneck 모델에서는 $3.25C^2$ 의 개수를 가지고 single convolution 에서는 $9C^2$의 파라미터 개수를 가지게 되어, 왼쪽의 모델이 훨씬 더 적은 파라미터를 사용하게 됩니다.
왼쪽 모델의 연산 개수는 다음과 같이 계산할 수 있습니다.
$$
\begin{aligned}
1 \times 1 \times C \times \frac{C}{2} = \frac{1}{2}C^2
3 \times 3 \times \frac{C}{2} \times \frac{C}{2} = \frac{9}{4}C^2
1 \times 1 \times \frac{C}{2} \times C =\frac{1}{2}C^2 \
\frac{1}{2}C^2 + \frac{9}{4}C^2 + \frac{1}{2}C^2 = 3.25C^2 \end{aligned} $$
이처럼 파라미터 개수가 줄어든다는 것은 훨씬 더 적은 연산을 요구한다는 것이기 때문에, 훨씬 더 효율적이게 될 수 있다는 것입니다. layer 를 거치면서 nonlinearity 도 좋아지기 때문에 작은 필터를 사용할지 않을 이유가 없다는 것입니다.
그런데 여기에서도 [3 x 3] 필터를 사용하기 때문에 이를 더 쪼갤 수 없는가에 대해서도 알아보겠습니다.
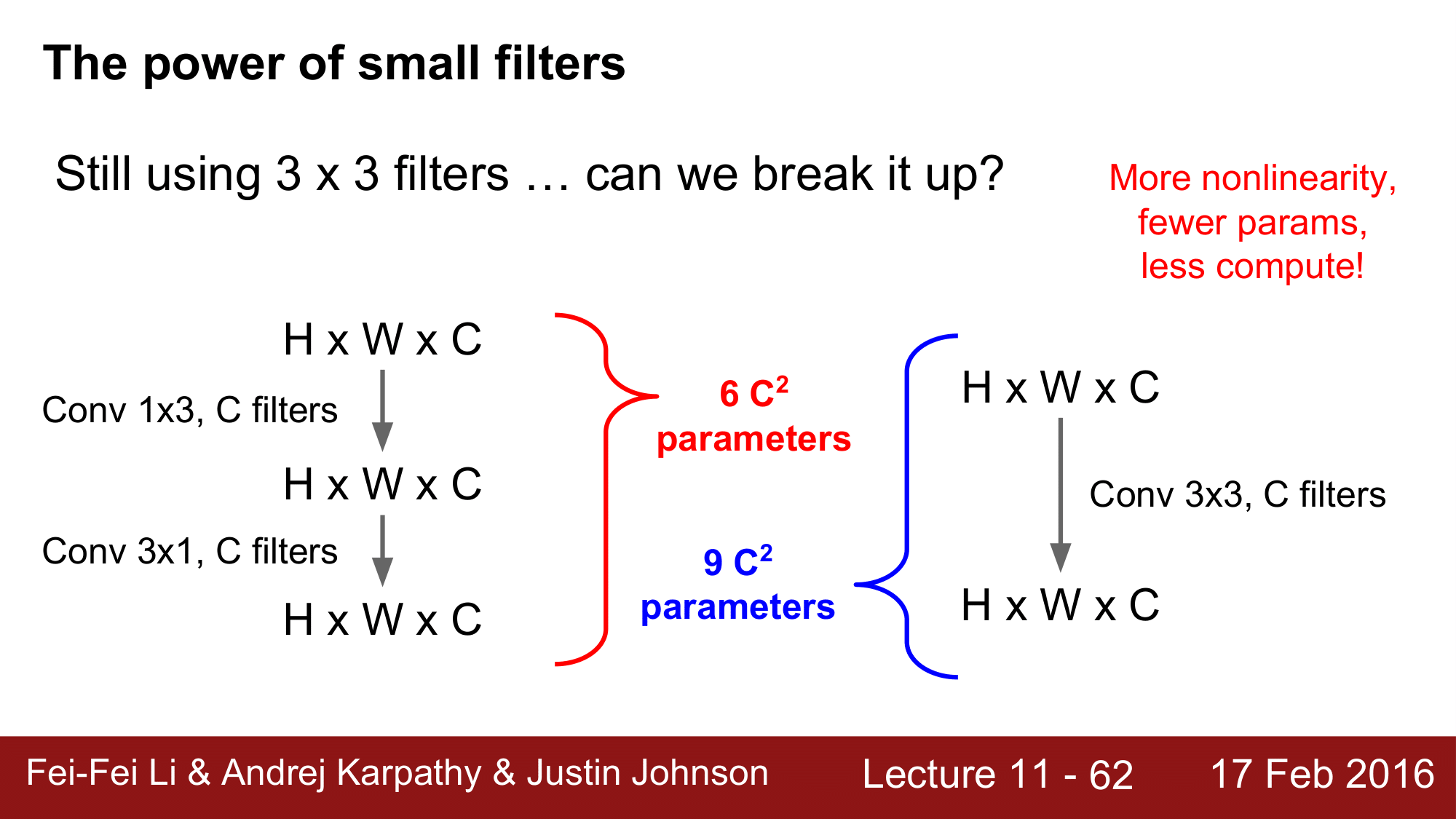
이전의 포스트에서 asymetric filter 라는 것에 대해서 잠깐 언급한 적이 있습니다.
asymetric filter 는 첫 번째에서 [1 x 3], 두 번째에서 [3 x 1]을 이용하는 것인데, 첫 번째의 파라미터 개수는 $1 \times 3 \times C \times C = 3C^2$
그리고 두 번째에서는 $3 \times 1 \times C \times C = 3C^2$ 가 되어 결국 $6C^2$의 파라미터 개수를 가지게 됩니다.
[3 x 3]필터와 비교를 해보게 되면 asymetric filter 가 좀 더 효율적이라는 것을 확인해볼 수 있습니다.
이런 식으로 creative 하게 asymetric filter 와 [1 x 1] bottleneck 를 잘 조합하여 사용하게 되면 더 좋은 결과를 얻을 수 있어보입니다.

실제로도 GoogLeNet 에서 사용하고 있는 filter 도 이런식으로 이루어져 있는 것을 확인 할 수 있습니다.

정리하자면, [5 x 5]나 [7 x 7]과 같은 큰 필터를 사용하지 말고, 가급적이면 [3 x 3] Convolution 으로 대체하여 사용하는 것이 좋다는 것, [1 x 1]의 bottleneck convolution 도 매우 효율적이다는 것입니다.
맨 처음에 Convolution 에 대해서 공부할 때 [1 x 1] 는 receptive field 가 1인 경우로 뉴런 하나만 볼 뿐인데 어떻게 효과가 있을 수 있는지에 대해서 의문을 가진 적이 있었습니다만, bottleneck 과 같이 사용할 수 있다는 것이 되겠습니다.
[N x N] Convolution 의 경우 [1 x N], [N x 1]의 두 개의 레이어로 나눠서 구성을 할 수 있으며, 이렇게 함으로써 효율적인 연산이 가능해진다는 것이 있었습니다.
이와 같은 모든 기법들은 파라미터 수는 줄이면서, 이에 따른 연산도 줄어들고, 레이어가 늘어남에 따라 nonlinearity 는 점점 더 강력해지는 효과를 거둘 수 있게 됩니다.

지금까지 어떻게 쌓느냐에 대해서 알아보았고, 이제부터는 어떻게 연산을 하느냐에 대해서 보도록 하겠습니다.

Convolution 을 구현하는 방법에는 여러가지가 있는데, 대표적으로 im2col 을 사용하는 방법입니다.
matrix multiplication 은 원래 매우 빠른 연산으로 대부분의 platform 에서 최적화하여 구현해놓은 상태입니다.
그래서 Convolution 을 matrix multiplication 으로 일반적으로 im2col 을 통해 recast 해 줄 수 있습니다.
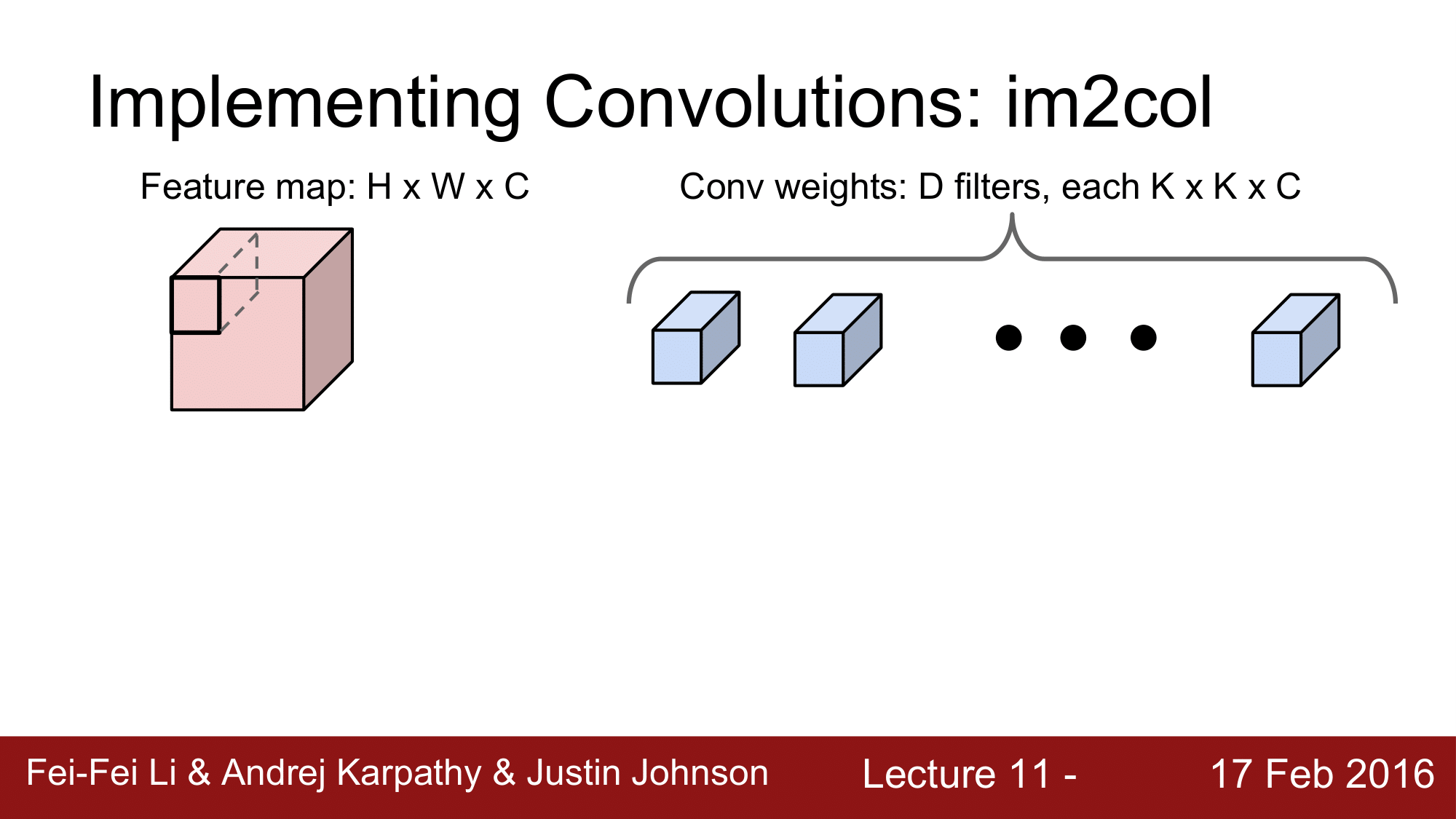
im2col은 위와 같은 방법으로 구현이 됩니다.
Feature map 이 H x W x C 로 구성되어 있고, Conv weight 는 K x K x C 로 이루어진 D 개의 filter 로 이루어집니다.
즉, receptive field 의 크기가 K x K x C 라고 할 수 있습니다.
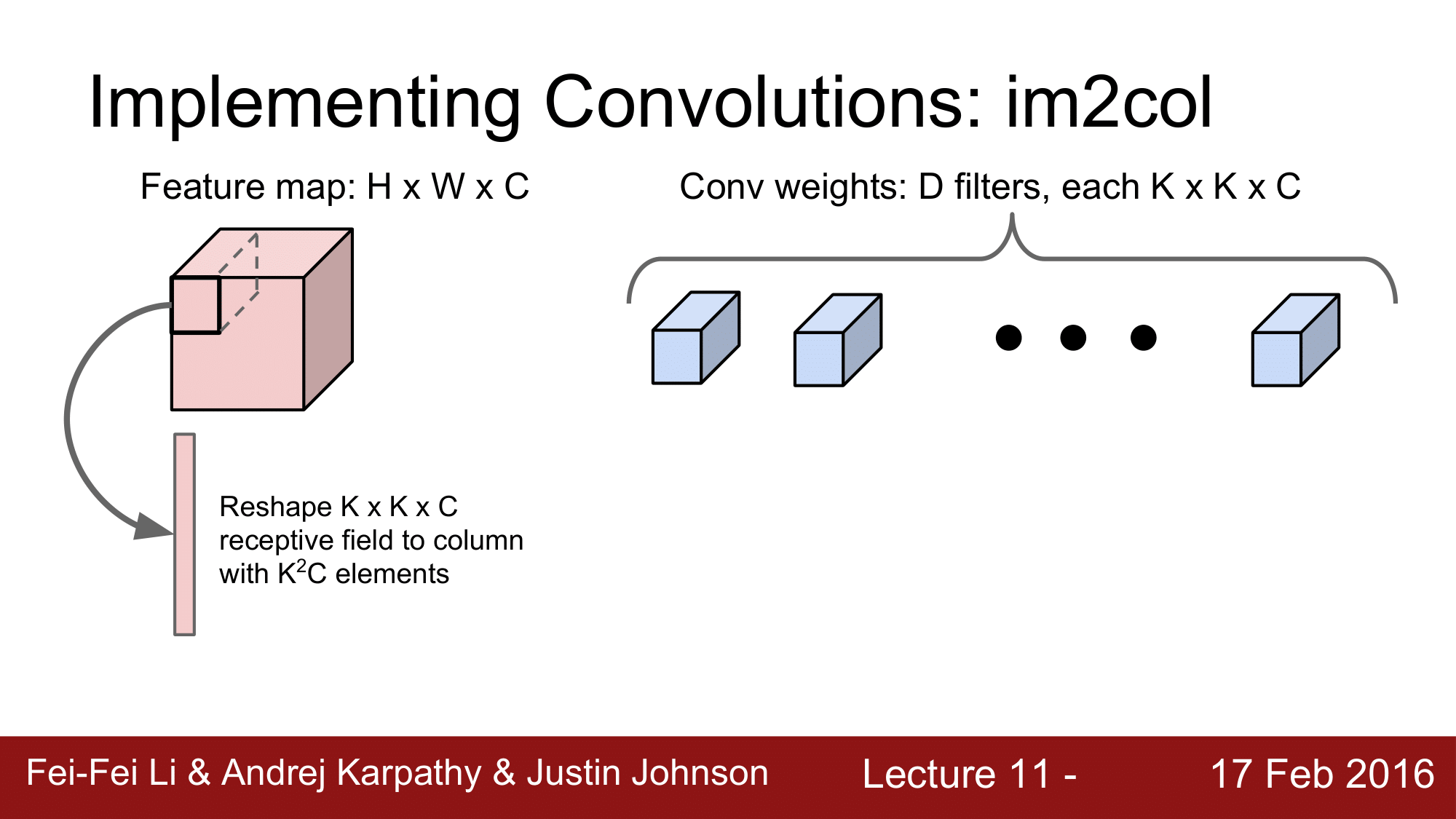
일단 첫 단계에서, K x K x C 의 receptive field 를 $K^2C$ 개의 원소를 가지는 column 으로 reshape 을 해주게 됩니다.

이후 receptive field 의 개수를 N 이라고 한다면, $(K^2C) \times N$의 column vector 를 N 번만큼 반복을 한 형태로 만들어주게 되는 것입니다.
그런데, 여기서 한가지 문제점은 receptive field 의 원소들이 중복이 되기 때문에 memory 를 다소 낭비하게 됩니다만 큰 문제가 될 수준은 아니라 일반적으로 이렇게 진행합니다.

다음 단계에서는 filter 를 $D \times (K^2C)$ 형태의 row vector 로 reshape 합니다.
 **
그래서 행렬 곱 연산을 다음과 같이 해주게 됩니다.
**
그래서 행렬 곱 연산을 다음과 같이 해주게 됩니다.
$(D, (K^2C)) \times ((K^2C), N) = (D, N)$

실제 Caffe 라이브러리의 예시를 보게 되면, 위와 같습니다.
빨간색 부분은 이미지를 column vector 로 변환하는 함수이고, 파란색 부분은 matrix multiplication 을 수행하는 부분이 되겠습니다.

지금까지가 im2col 에 대해서 알아봤습니다. Covolution 을 활용하는 또 다른 예로 FFT(Fast Fourier Transform)이 있습니다.
이것은 Signal Processing 에 관련한 Convolution Theorem 에 의하면 하나의 시그널 $f$ 와 또 다른 하나의 시그널 $g$를 Convolution 한 것은 Fourier Transform 한 것의 elementwise product 와 동일하다는 것입니다. 그래서 이를 식으로 표현하면 아래와 같이 됩니다.
\[F(f * g) = F(f) \cdot F(g)\]그래서 FFT(Fast Fourier Transform)이라는 것은 Fourier Transform 과 역행렬을 매우 빠르게 계산해내는 알고리즘이 되겠습니다.

FTT를 구현하기 위해서는 먼저 weight 와 activation map 를 구한 다음에 이들을 elementwise product 를 해주고 이에 대한 역행렬을 취하는 순으로 convolution 을 진행해줍니다.
이를 통해서 속도에 매우 큰 향상을 기대할 수 있습니다.

위 kernel 크기에 초점을 맞추어 실험 결과를 보게 되면, [7 x7]의 경우 효과가 잘 나타나는 반면에 [3 x 3]의 경우 효과가 잘 나타나지 않는 것을 볼 수 있습니다.
초록색 부분이 speedup 을 나타냄

또 다른 Convolution 구현의 예로는 Fast Algorithms 이 있습니다.
일반적인 matrix multiplication 에서는 두 개의 (N, N)행렬을 연산해주게 되면, $O(N^3)$의 연산을 수행하게 되는데, Strassen’s Algorithm을 이용하면 $O(N^{log2(7)}) ~ O(N^{2.81})$까지 낮출 수 있게 됩니다.

이러한 효과를 Convolution 에 적용을 해본 것이 2015년의 Lavin and Gray 의 “Fast Algorithms for Convolutional Neural Networks” 입니다.
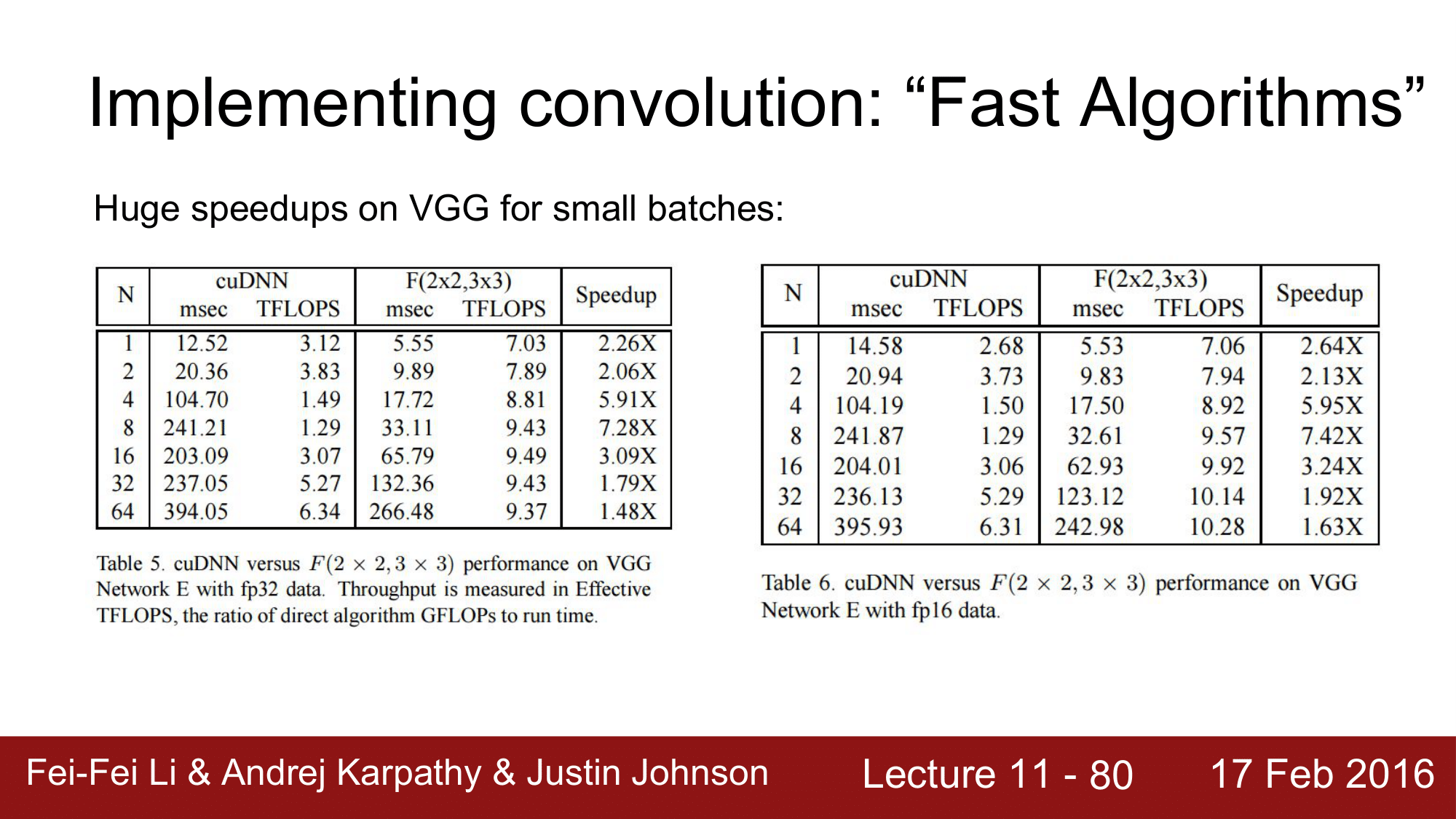
이 알고리즘을 VGGNet 에 테스트 해봤는데 굉장한 속도의 향상을 가져온 것을 위의 표를 통해 확인할 수 있습니다.
단점은 Convolution 의 size 가 다르면 각각에 대해 다른 과정을 거쳐 알고리즘을 최적화해주어야 한다는 것이 존재하지만, 그럼에도 불구하고 매우 속도가 빠르기 때문에 convolution 은 앞으로 이러한 측면에서도 발전을 해나갈 것으로 예측해볼 수 있습니다.

Convolution의 활용 예에 대해서 정리하자면, im2col 은 구현이 쉽고 메모리에 대해서 overhead 가 많이 발생하긴 하지만 기본적으로 많이 사용한다라고 정리할 수 있습니다.
FFT 의 경우 작은 kernel 에 대해서는 성능향상을 가져올 수 있다라는 것, 마지막으로 Fast Algorithms 은 small filter 에도 잘 동작하기 때문에 매우 앞으로 전도 유망하지만 아직 널리 쓰이지는 않고 있다라고 정리할 수 있습니다.

이제는 실제로 convolutional neural net 을 어떻게 구현하는 지에 대한 예를 살펴보겠습니다.

GPU 같은 경우 nvidia 와 AMD 가 양분하고 있는데 일반적으로 딥러닝에서는 nvidia 쪽을 좀 더 선호하고 있습니다.

CPU 와 GPU 를 비교해보면, CPU 는 코어 수가 적은 대신에 매우 빠르며 sequential processing 에 강력합니다.
반면에, GPU 는 느린 코어들을 매우 많이 갖고 있으며, 처음에는 그래픽 성능향상을 목적으로 사용되었다가 parallel computaion 에 매우 강력한 성능을 보유하고 있기 때문에 딥러닝에 많이 활용되고 있습니다.

또한, GPU 는 프로그램이 가능합니다.
GPGPU(General Purpose GPU)로 CUDA 나 OpenCL 과 같은 것들이 있는데 CUDA 의 경우 NVIDIA 에서 사용하는 것이고 OpenCL 은 모든 플랫폼에서 사용됩니다.
여기서 CUDA를 보게 되면, GPU 상에서 바로 돌아갈 수 있는 C 코드를 바로 적용할 수 있습니다. 그리고 여기에 적용할 수 있는 상위 level 의 API 로는 행렬연산에 최적화되어 있는 cuBLAS 나 딥러닝에 최적화되어 있는 cuDNN 과 같은 것들이 있습니다.
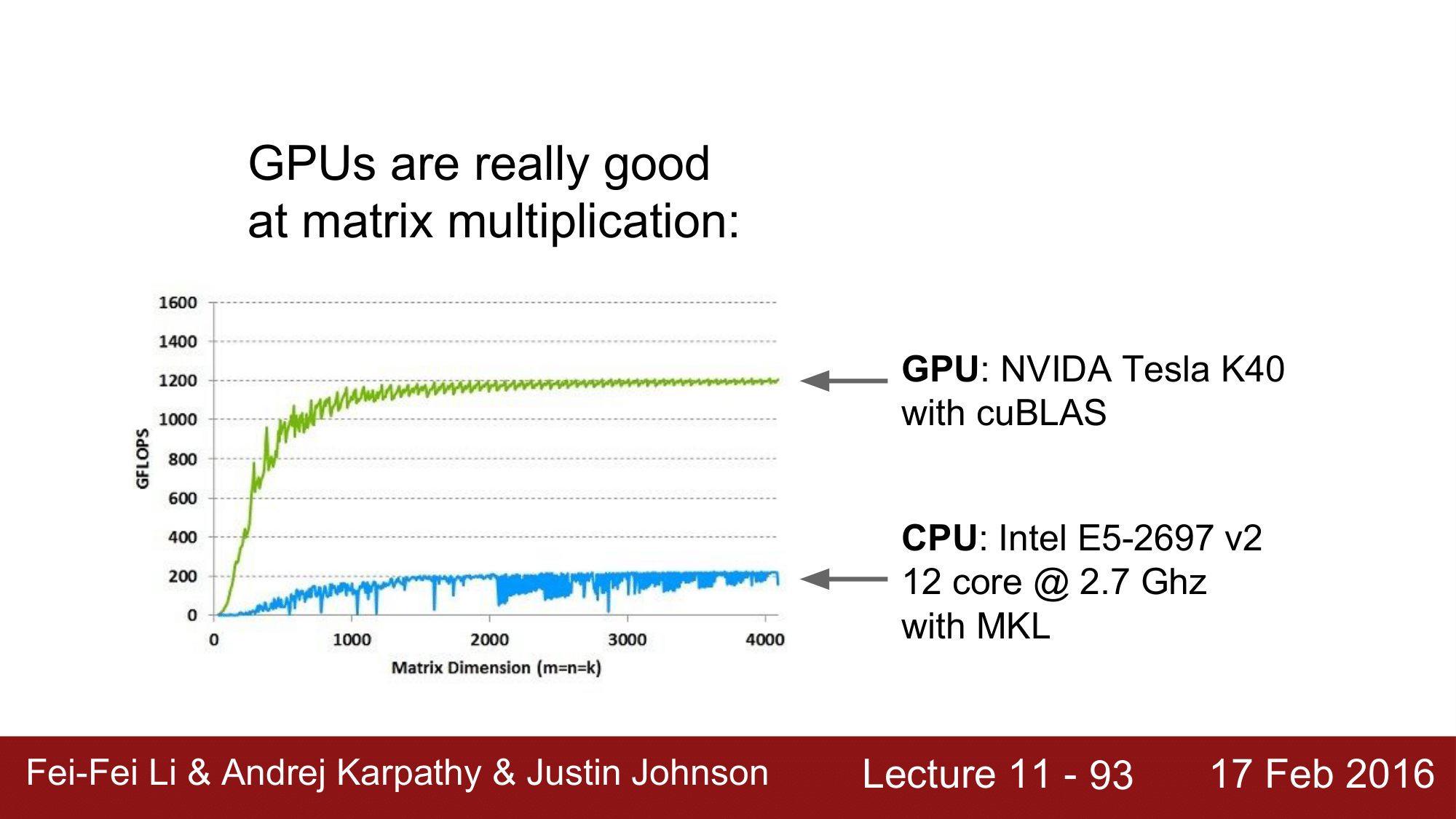
GPU의 장점은 병렬연산이 강하기 때문에 matrix multiplication 에 매우 강하다는 것이고, 위의 그래프는 CPU 와 GPU 의 속도를 비교한 것이 되겠습니다.
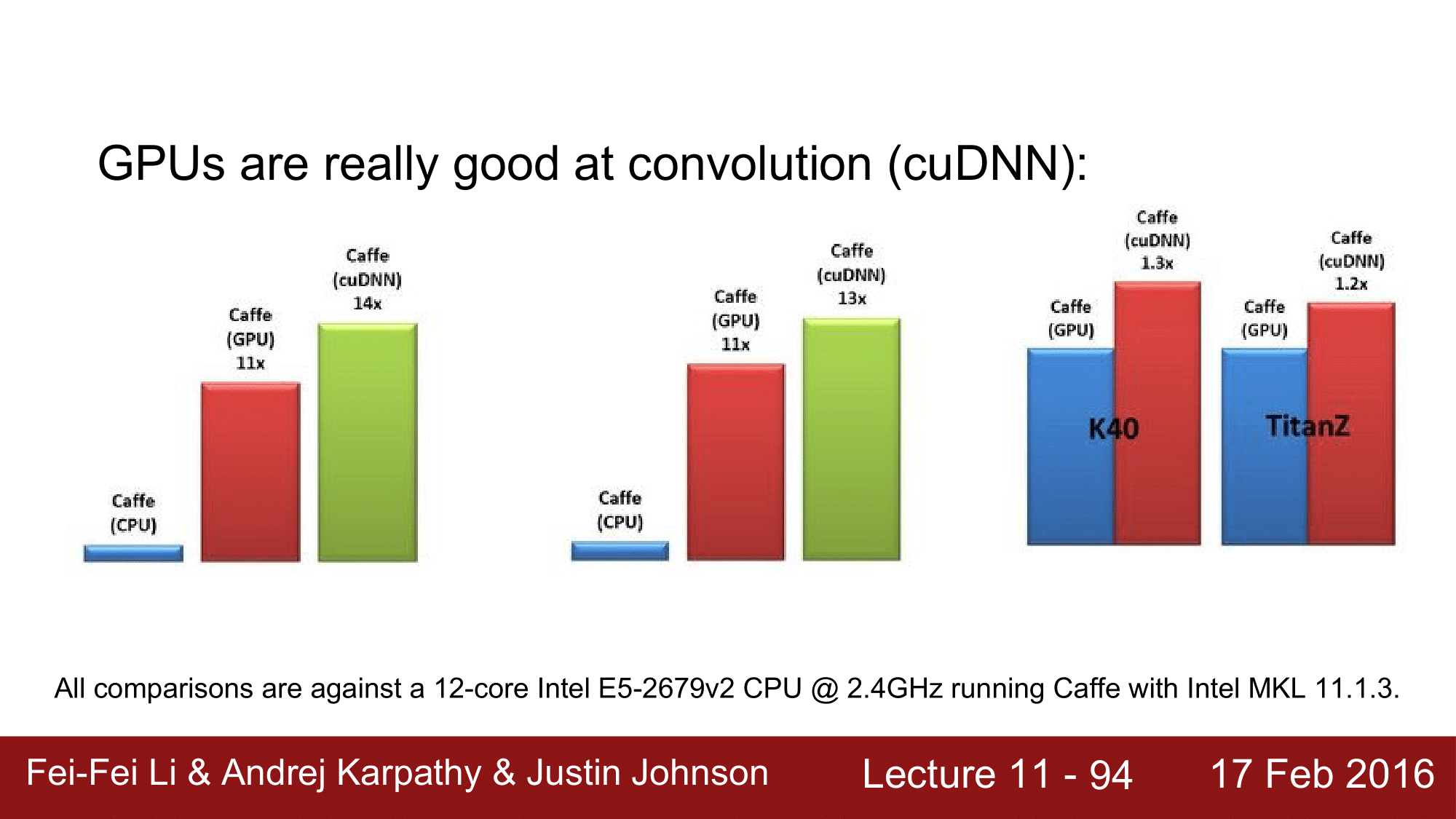
CPU에 비해서 GPU의 성능차이는 굉장히 크고, 여기에 cuDNN 을 사용할 경우에는 더 차이가 납니다.

하지만 현실적으로는 GPU를 아무리 사용한다 하더라도 학습에는 시간이 오래 소요되는데, VGG의 경우 4개의 GPU 를 사용한다고 했을 때 2~3 주, ResNet 의 경우는 마찬기지로 2~3 주가 소요됩니다.
여기서 VGG 의 경우 memory 사용량이 굉장히 많기 때문에 single GPU 로는 미니배치의 크기가 커지는 것을 감당할 수 없습니다. 그래서 여러개의 GPU 를 사용하는 것입니다.

Multi-GPU training 은 좀 더 많이 복잡하게 진행됩니다.
Alex Krizhevsky 의 “One weird trick for parallelizing covnolutional neural networks”를 보게 되면 upper layer 인 FC Layer 는 matrix multiplication을 하기 때문에 model parallelism 을 통해 함께 진행하게 되고, lower layer 인 CONV Layer 에서는 각 GPU 별로 작업을 하는 것이 효율적이라고 합니다.

구글이 TensorFlow 이전에 머신러닝 학습 프레임워크로 DistBelief 라는 것을 만들었었는데, 이는 CPU 기반의 framework 로 CPU 의 느린 처리속도를 분산처리할 수 있도록 한 것으로 그때부터 잘 구현했었습니다.
위 왼쪽 figure 에서와 같이 컴퓨터 서버 쪽에 parameter 를 저장해두고 model 쪽이 data 부분과 communication 하며 진행하는 모델이었습니다.
data parallelism 과는 반대로 model parallelism 에서는 오른쪽 figure 와 같이 통합하여 처리하는 식으로 진행되었습니다.
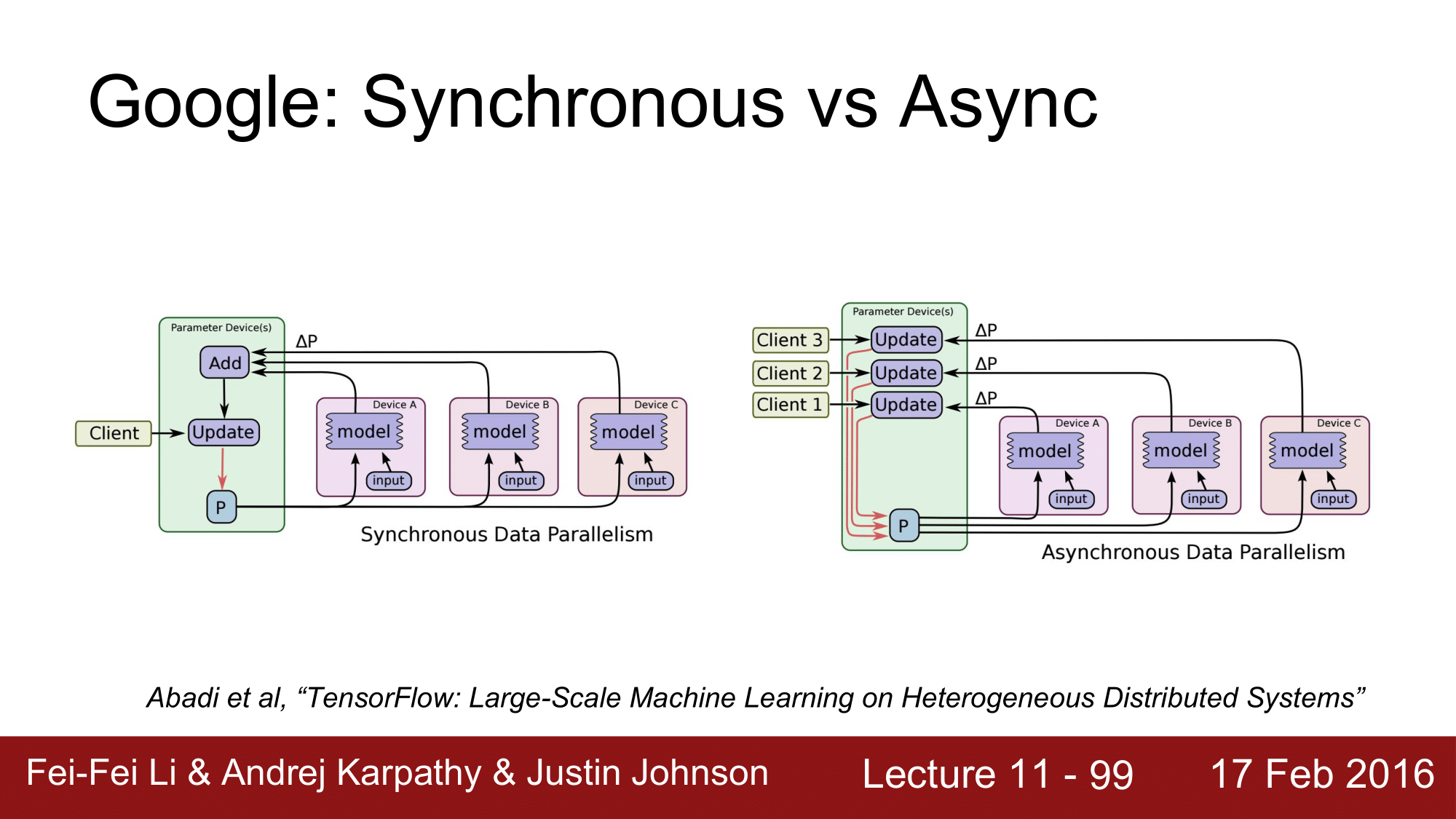
Google 이 대단한 것은 일반적인 것은 Synchronous 하게 처리하는 것을 Async 하게 처리하도록 한 점입니다.
왼쪽 그림에서 각 GPU 를 worker 라고 한다면 mini-batch 를 각 worker 에게 할당해주고 각 worker들은 foraward pass 와 backward pass 를 하면서 gradient 를 계산해주게 됩니다. 그 작업이 끝나면 각 worker 들이 gradient를 통합해준 다음에 model을 업데이트해나가는 식으로 진행됩니다.
하지만 이처럼 각 worker 들이 sync 하는데에 시간이 많이 소요되어 비효율적으로 동작하게 되는 것을 async 하게 동작할 수 있도록 했습니다.
오른쪽 그림에서는 각 worker 들이 계산한 gradient 를 통합하여 model update 하는 것이 아니라 각 worker 가 구한 gradient 를 개별적으로 update 하는 식으로 동작합니다. 이렇게 함으로써 sync 에 소요되는 시간을 대폭 감소시킬 수 있었다는 것으로, 이런 것들이 tensorflow 에 구현되어 있습니다.

딥러닝을 수행하는데 있어서 여러가지 Bottleneck 이 되는 부분들이 있는데 어떤 것들이 있는지 알아보겠습니다.

CPU 와 GPU 간의 communication 이 하나의 bottleneck 이 될 수 있다는 것이 있습니다.
forward pass 와 backward pass 를 할 때마다 데이터를 GPU 에 복사했다가 이를 다시 CPU 로 복사해오는 작업에 큰 부하가 걸린다는 것입니다.
궁극적으로는 CPU 에서는 데이터를 미리 fetch 해오고 GPU 상에서 pass 의 전과정이 가능해야지만 이런 bottleneck 을 없앨 수 있다라는 것입니다.

또 하나의 bottleneck 은 disk 입니다.
HDD 는 현재관점에서는 매우 느린 저장매체입니다. 그래서 대안으로 SSD 를 사용할 수 있습니다. 또한 file 에 random access 한는 것보다 sequential read 하는 것이 속도가 더 빠를 것이고 image 의 경우 미리 preprocessing 을 통해 raw byte stream 으로 바로 읽을 수 있도록 하면 성능향상을 기대해 볼 수 있습니다.

또한 GPU memory 에 걸리는 bottleneck 이 있습니다.

마지막으로 Floating Point Precision 에 대해서 살펴보겠습니다.

일반적으로 프로그램에서는 64bit 를 double precision 이라고 하는데 성능향상을 위해서는 32bit 의 single precision 을 사용할 수 있다는 것입니다. 실제로 32bit 를 많이 사용합니다.
오른쪽의 숙제코드를 보더라도 dtype=np.float32인 것을 확인할 수 있는데, 사실 이 32bit 도 너무 큽니다.

그래서 half precision 인 16bit 를 표준으로 많이 사용합니다.
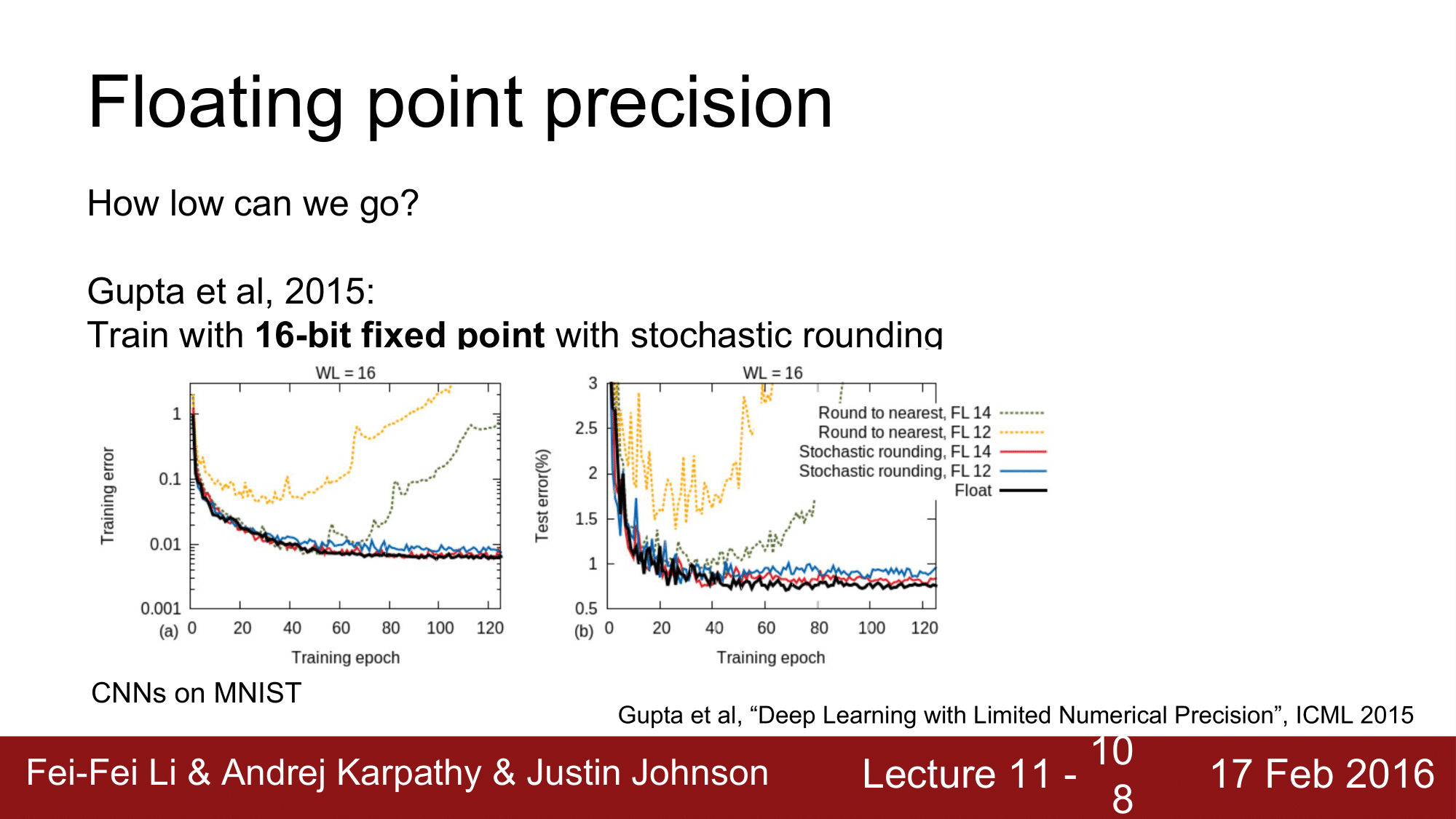
위 그래프는 16bit 로 한 train 결과로 노란색과 초록색의 경우 divergence 하는 것을 볼 수 있습니다.
이 때문에 paramter 와 activation 을 모두 16bit 로 생성한 다음 multiplication 연산이 일어나는 경우에 한해서 더 높은 bit로 잠시 올려줬다가 multiplication 이 끝나면 다시 내려주는 stochastic rounding 을 사용하여 빨간색과 파란색의 경우 converge 하는 것을 볼 수 있습니다.
다시 말해서 stochastic rounding를 이용해서 16bit 라는 raw precision 을 가진 numerical issue 를 해결했다고 보면 됩니다.

2015 년에는 10bit, 12bit 로 하는 모델을 선보인바 있습니다.

심지어 2016년에는 activaiton 과 parameter 를 1bit 로 학습시키는 모델이 나왔습니다.
그래서 모든 activation 과 weight 은 1bit 이기 때문에 +1 또는 -1로 설정이 되고 bitwise XNOR 연산을 통해 매우 빠른 연산을 수행했다고 합니다.
단 gradient 는 좀 더 높은 precision 을 사용했다고 합니다.
그래서 어쩌면 앞으로는 더 좋은 퍼포먼스를 위해서 1bit 를 사용하는 binary net으로 진화할지도 모릅니다.

정리하자면 위와 같이 됩니다.

오늘 설명한 전체 내용도 위에 정리 되어있습니다.